
20
Kubernetes Backup & Restore made easy!
For July I chose: Kasten's K10 platform 🎉 - a data management platform to backup and restore your applications easily to protect your data.
In this tutorial, we are going to talk about a challenging task of data management in Kubernetes and a tool that makes data management very easy for the K8s administrators, which is Kasten's K10.
Imagine, we have the following real-world setup in our K8s production cluster.
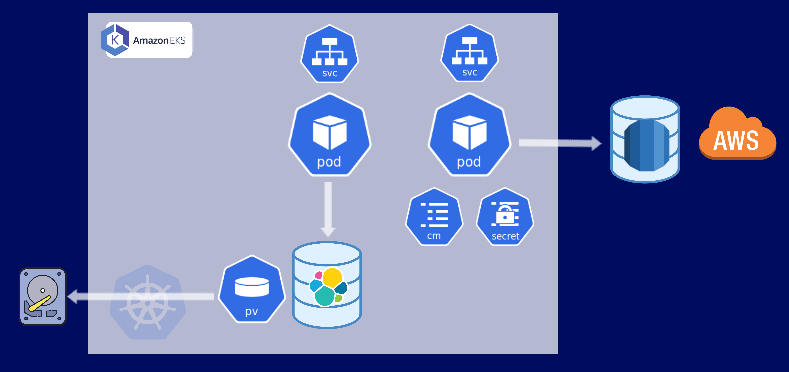
An EKS cluster, where our microservices application is running. Our microservices use ElasticSearch database, which is also running in the cluster. And in addition to that our application is using Amazon's RDS data services, which is a managed database outside the cluster.
This means our application has data services both inside and outside the cluster. And these data will be physically stored on some storage backend. RDS data will be stored on AWS of course. Data for ElasticSearch will be used in the cluster through K8s Persistent Volume components, but they also need to be physically stored somewhere. This could be a cloud storage on AWS, Google Cloud etc. or on-premise servers.
1. Underlying infrastructure fails ⛔️
The underlying infrastructure, where the cluster is running fails, and we lose all the pods, and the whole cluster. We would need to recreate the cluster with the same cluster state (K8s components - ectd) and application data. So we need to restore our whole cluster.
2. ElasticSearch DB gets corrupted ⛔️
Or let's say our ElasticSearch DB gets corrupted or hacked into and we lose all the data. Again, we need to restore our database to the latest working state.
3. Replicating Kubernetes cluster (Multi-Cloud or Hybrid Cloud) ☁️☁️
Or another common use case, say our cluster is running on AWS, but we want to make our production cluster more reliable and flexible, by not depending on just 1 cloud provider and by replicating it on a Google Cloud environment with the same application setup and application data.
In all these cases, the challenge is:
how do we capture an application backup that includes all the data that the application needs, whether it's the databases in the K8s cluster or a managed data service outside the cluster?
So that if our cluster failed, or something happened to our application and we lost all the data etc, we would be able to restore or replicate the application state with all its components, like pods, services, configMaps, etc and its data?
And that is a challenging task.
Now let's look at what alternatives we have available:
- VM or etcd Backups 👀
If you do VM backups of your cluster nodes or etcd backups, you will save the state of the cluster, but what about the application data? They are not stored on the worker nodes, they are stored outside the cluster on a cloud platform or on on-premise servers.
✅ Cluster State backup up
❌ Application Data not backed up
- Use Cloud Providers Backup and Restore Mechanism 👀
On the other side, for the cloud-storage backends, the cloud providers themselves have their own backup and replication mechanisms. But it's only partially managed by the platform, so you still have to configure the data backups etc yourself. Plus, it's just the data in the volume. This doesn't include the cluster state.
✅ Data in Volume backed up
❌ Only partially managed by cloud platform
- Write Custom Backup and Restore Scripts for the different infrastructure levels 👀
Many teams write custom scripts to piece together backup solutions on different levels, like components and state inside the cluster and data outside the cluster. But this scripts can get very complex, very soon, because the data and state is spread on many levels, many platforms. And the script code usually ends up being too tied to the underlying platform where data is stored.
The same goes for the restore logic. Many teams use custom scripts to write restore logic or cluster recreation logic from all the different backup sources.
So overall, your team may end up with lots of complex self-managed scripts, which are usually hard to maintain. 😣
✅ Tailored to application
❌ Complex scripts
❌ Too tied to the underlying platform
❌ Difficult to maintain
These are exactly the challenges that Kasten's K10 tool addresses. So how does K10 solve these problems?
K10 abstracts away the underlying infrastructure to give you a consistent data management support, no matter where the data is actually stored:

So teams can choose whichever infrastructure or platform they want for their application, without sacrificing operational simplicity, because K10 has a pretty extensive ecosystem, and integrates with various relational and NoSQL databases, many different Kubernetes distributions and all clouds.
So instead of backup scripts for each platform or level, you just have 1 easy UI interface of K10 to create complete application backups in the cluster:

So everything that is part of the application, like K8s components (pods, services etc.) and application data in volumes as well as data in managed data services outside the cluster will be captured in the application snapshot by K10.
So you can easily take that snapshot and reproduce or restore your cluster on any infrastructure you want. 🙌
K10 works with policies. Instead of manually backing up and restoring your applications, which means more effort and higher risk of making mistakes, you can configure backup and restore tasks to run automatically with the settings you defined in the policy.
Now, what if you have multiple clusters across zones or regions or even across cloud platforms and on-premise data center. How do you consistently manage 10s or 100s of cluster backups? 🤔 Well, K10 actually has a multi-cluster mode. In K10's multi-cluster dashboard, you have a view of all your clusters, as well as a way to create and configure global backup and restore policies that you can apply to multiple clusters.
Now, if you have 100s or 1000s of applications across many clusters, of course you don't want to create policies on the UI. For that, K10 provides us with Kubernetes native way of scripting policies with YAML. So you can also automate your policy creation and configuration as part of your policy as code workflow. 👍
In the video, I will show you how K10 actually works in practice. In the hands-on demo, we will create an automated backup policy for our mysql application to protect its data and then restore it within seconds:
More awesome tools coming up next on this series, so stay tuned for it! 🎬 😊
Like, share and follow me 😍 for more content:
20