

28
Notes on Kafka: Brokers, Producers, and Consumers
We had a good overview of what brokers, producers, and consumers are in the previous sections. Now it's time to go deeper! You can simply skip ahead onto the parts you're interested in or you could also check out each one below (which I hope you do!)
As previously tackled, a Kafka cluster is composed of multiple brokers and each broker is basically a server.
It is also important to note that when you connect to a broker, which is called the bootstrap broker, you're already connecting to the entire cluster.
Also, recall that when you create a topic, the topic and its partitions will be distributed among the available brokers in the cluster. In the example below, we have cluster of three brokers and three topics.
Each topic has different number of partitions. This means that for Topic-A, the data streaming to that topic will be distributed to the 4 partitions. The same goes for Topic-B, but since this topic has only 3 partitions, it's only occupying 3 brokers.

On the other hand, Topic-C has 6 partitions which means two brokers (BROKER-101 and BROKER-3) will contain 2 partitions.
Besides specifying the partition when you create a topic, you need to also indicate the replication factor.
In the example below, we have Topic-A with two partitions. We've also set it's replication factor to 2. When broker 102 goes down, the topic will still have both partitions accessible, ensuring that data will still be served.
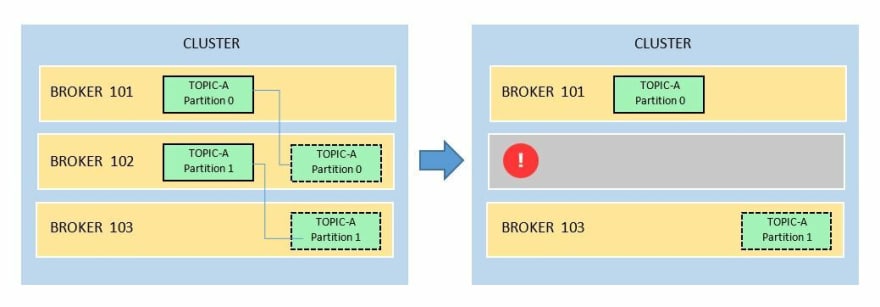
We've learned so far that topics are split into partitions and these partitions are distributed into the brokers. The partitions also needs to each be replicated to make sure that there's fault tolerance.
Between the partition and it's replica, one is elected as a leader and the other replica/s is called the in-sync-replica.
Using the same example we have Topic-A with 2 partitions.
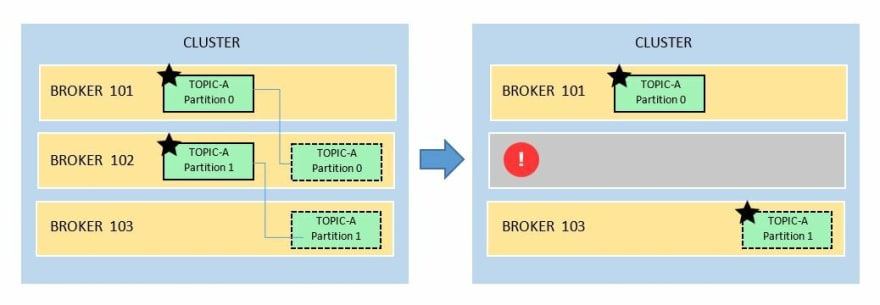
In the event broker 102 goes down,
Producers write data into topics. These producers are client apps that automatically know which broker and partition to write to.
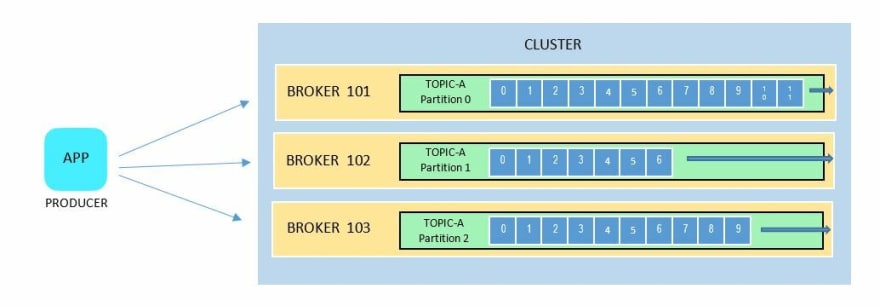
Producers can also choose to receive acknowledgement of data writes. This means producers can opt to wait for confirmation from the brokers that the data was written successfully to the partitions. There's three types of acknowledgement:
| Acknowledgment | Description |
|---|---|
| acks=0 | - Producer doesn't wait for confirmation - If producer sends the data to a broker which failed, the data is loss. |
| acks=1 | - Leader confirms to producer if data write is successful - Limited data loss. |
| acks=all | - Producer waits for both leader's and ISR's confirmation - No data loss |
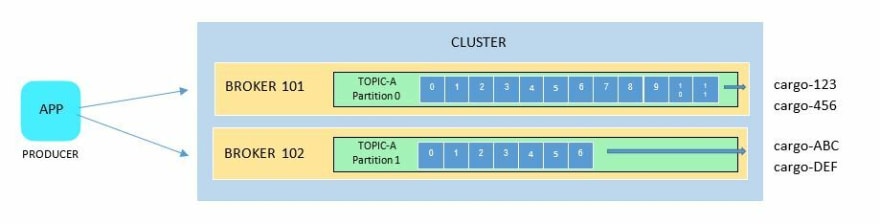
Producers can send the message with a key. Message keys allows the producer to assign the data to a specific partition.
Think of keys as tags. As an example, we have a producer sending data to a topic with two partitions below. We can assign:
All data "tagged" with cargo-123 and Cargo-456 will be sent to partition 0, while those "tagged" with cargo-ABC and cargo-DEF will be sent to partition 1.
Consumers are applications on the other ends. They read data from the topic, and just like producers. they also know which topic to read from.
In the example below, we have two consumers that read from the same topic. Consumer 1 reads from a single partition only while Consumer 2 read data in parallel from 2 partitions.
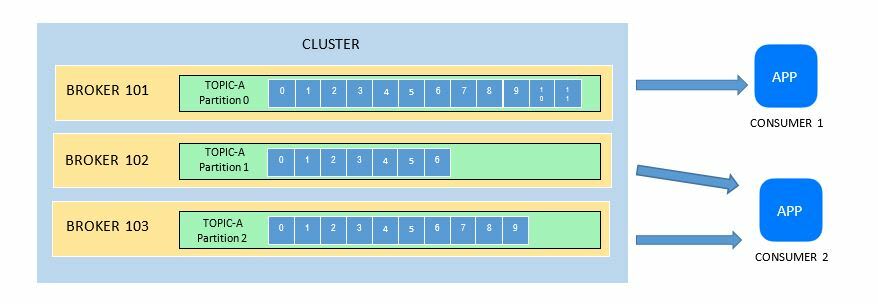
In a real-world scenario, consumers actually read data in groups. Consumers within a group read from exclusive partitions.
In the example below, we have three consumer groups - each with its own number of consumer apps.

As discussed in the previous sections, offsets are a way to "bookmark" the current position in the partition.
The purpose of offsets are for consumers to know where they left off in case the consumer dies - "bookmarked" the last read data. So that when the consumer comes back, it can check the commited offset and proceed to the last known position in the partition.
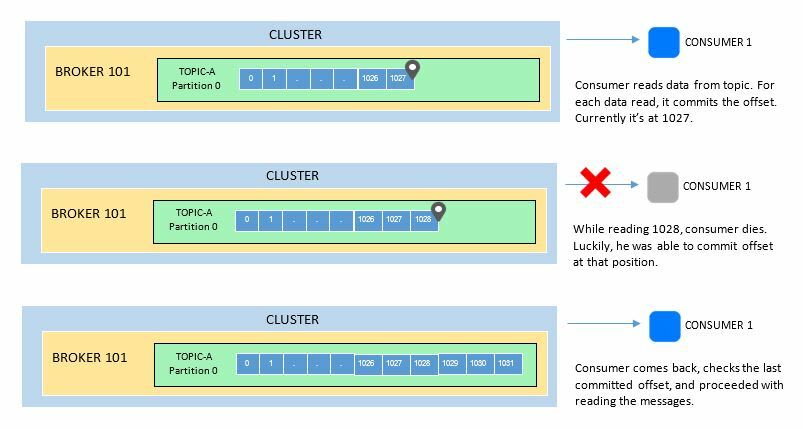
Additionally, consumers also has a choice on when to commit offsets. These are called delivery semantics and there are three types:
At most once
At least once (preferred)
Exactly once
When a client connects to a broker from a cluster, it is automatically connected to all the brokers inside that cluster. This is because each broker knows all of the other brokers, topics, and partitions - this information is called the metadata.
Behind the scenes, this is how broker discovery is done when a Kafka client (producer or consumer) first connect to one broker:
Awesome job getting to the end!
Whew, this article has covered a lot and I'm pretty sure you've gained a ton too. Now, before we conclude the Kafka theory and proceed with the labs, here's a summary of all we've discussed.
Whew, this article has covered a lot and I'm pretty sure you've gained a ton too. Now, before we conclude the Kafka theory and proceed with the labs, here's a summary of all we've discussed.
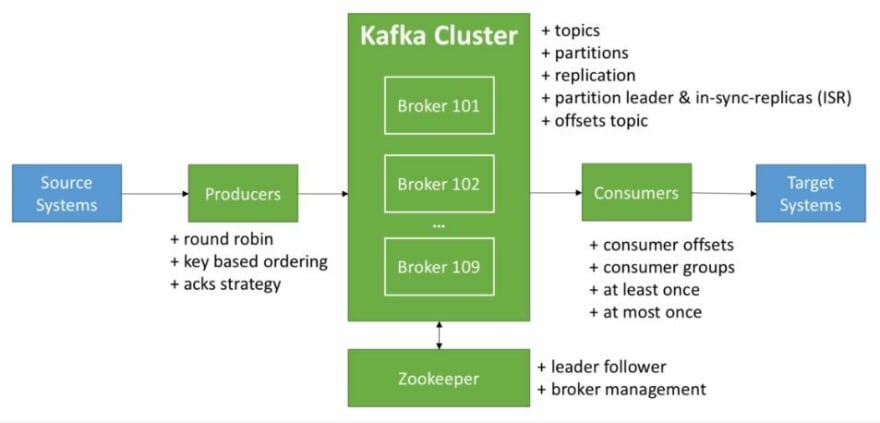
Photo is from Stephane Maarek's course - such an extraordinary instructor! If you'd like to know more, you can check out the his course, along with other ones that I find useful:
Apache Kafka Series - Learn Apache Kafka for Beginners v2 by Stephane Maarek
Getting Started with Apache Kafka by Ryan Plant
Apache Kafka A-Z with Hands on Learning by Learnkart Technology Private Limited
The Complete Apache Kafka Practical Guide by Bogdan Stashchuk
If you find this write-up interesting, I'll be glad to talk and connect with you on Twitter! 😃
28