
25
Scratching an itch with Spark
One of the things I love about Spark is how easy it makes working with various data sources. Once you've got the data out of the source and into a Dataset or DataFrame then you can manipulate that data without thought to the original format. Most of the times this is in CSV, Parquet, JSON, or a few others. But occasionally (or quite a lot of the time it seems if you're me) people will have the bulk of their data in Excel.
I'm not going to go into why Excel is a bad format for data storage and distribution, you can find plenty of reasons on-line, or you've likely encountered it yourself (Excel interpreting dates anyone?).
I've been working on a custom data source for Spark recently using the newer DatasourceV2 APIs, which make it easier to write data sources without having to consider RDDs, whilst bringing along a lot of new functionality like predicate push-down.
At the moment I'm still working through a few kinks, and ensuring that I've got as much code and branch coverage as I can, at which point I'll do a deeper dive into the how as I can't see a lot about how to write your own data sources on-line or off-line. But at the moment the data source supports the following features.
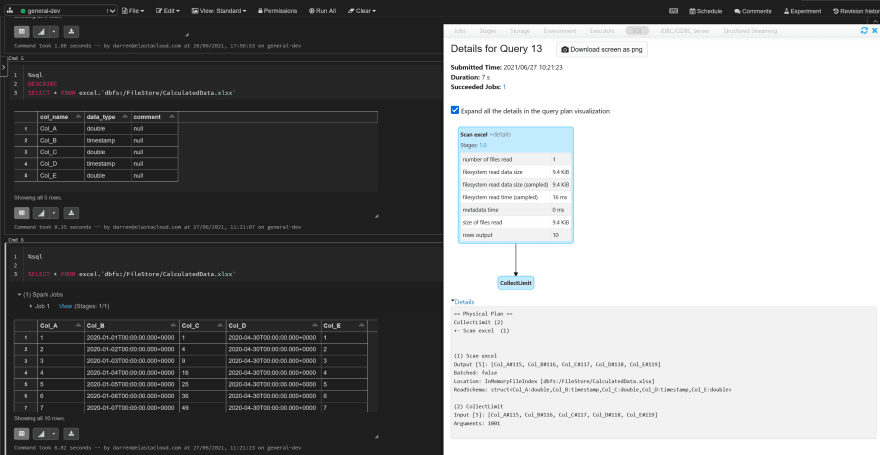
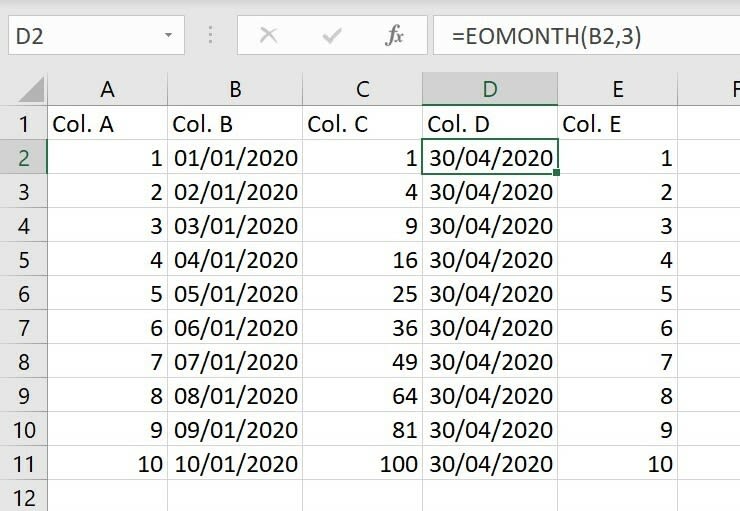
This screenshot is querying a sample workbook I put together which contains formula data, I wanted to do this to make sure that the data was extracted as expected. And thanks to the Apache POI library, most formulae people use should be covered.
Code coverage is looking pretty good at the moment, but I want to make sure all of the key parts of the data source are covered, as there's a few "quirks" of Excel which I need to make sure are working as expected.

Hopefully I can jump onto the deeper dive soon, just in case there's anyone else out there crazy enough to want to write their own data source.
25