
29
Primeiros passos com self-hosting
Neste post vamos fazer uma visão geral das principais partes do self-hosting.

Acredito que umas das primeiras considerações quando montamos nosso setup de self-hosting é pensar como isso vai se organizar e onde vai ficar cada coisa.
Self-hosting não é ser “contra a nuvem” mas sim um movimento para ter controle dos nossos dados e aplicações que usamos, mesmo usando a nuvem nós que vamos configurar tudo e ter controle de como cada coisa funciona.
Outro modelo é hospedar “tudo em casa” (chamado de on-premise), funciona muito bem. Mas um desafio que logo vamos abordar é abrir a conexão da sua operadora para acessar seus serviços fora de casa.
Daí surge um terceiro modelo: o híbrido, parte das coisas que necessitam de velocidade ficam em casa e o restante que precisa acessar fora de casa na nuvem. No meu caso, coloco na nuvem (uma virtual private server (VPS) da digital ocean) o nextcloud com apenas meus contatos e calendário (no android uso o davx5 para sincronizar a agenda e os contatos com o nextcloud) e em casa guardo meus backups (com uma cópia no rsync.net) e todo resto :P
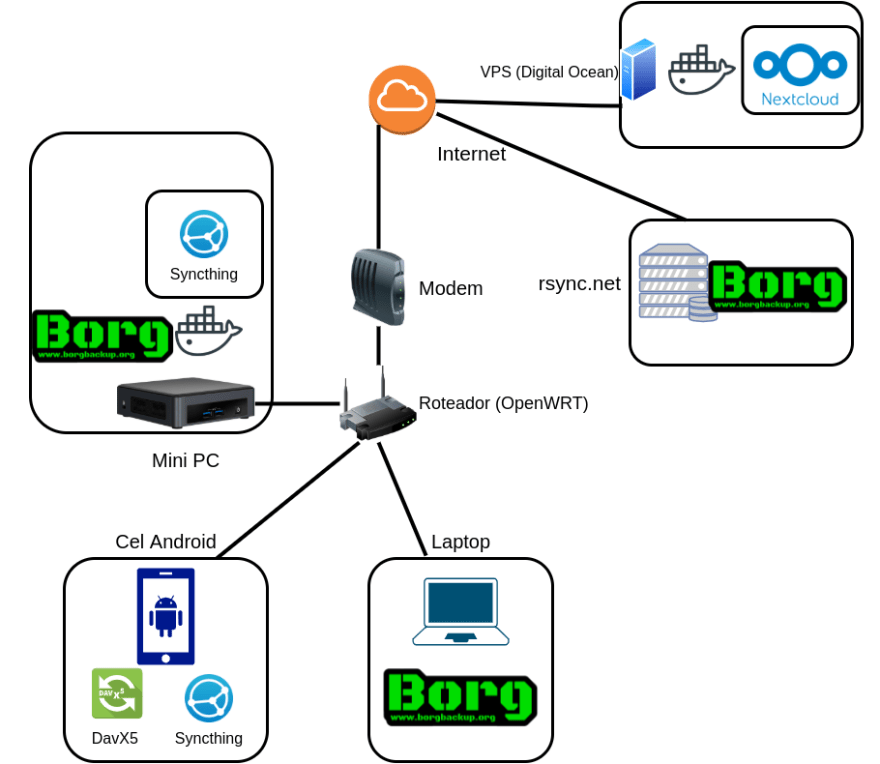
Além de ser muito bonito e divertido de fazer, recomendo fazer um diagrama de como vai se organizar suas aplicações e dispositivos, acima é como organizo tudo.
Para hospedar nossas coisas em casa, precisamos de um hardware para fazê-lo, pode ser usado com computador velho ou, outras opções populares, são usar a Raspberry Pi, mini pc (tipo intel NUC) ou por fim um servidor de armazenamento conectado em rede (NAS, de Network Attached Storage). Embora seja uma melhor opção pelo reuso e sobrevida de um equipamento obsoleto, é importante ficar ciente e atento a falhas por fadiga que podem comprometer a disponibilidade ou a confiabilidade do serviço.
Quando eu comecei nessa jornada do self-hosting, havia comprado um SSD para meu notebook então peguei o disco que veio nele e conectei numa Raspberry Pi. Começar com uma Raspberry Pi é ótimo: é barato, consome pouca energia e atende aos requisitos de recursos de várias aplicações.
Mas existem outras necessidades que uma Raspberry Pi não consegue atender, como por exemplo rodar máquinas virtuais, e daí surge a necessidade de outros hardwares apropriados. Como um mini-pc (ou Intel NUC) que é literalmente um mini pc e os componentes tradicionais como processador x86 (ao invés do ARM do Raspberry Pi), slots de memória RAM que pode ser trocada, etc.

Quer armazenar muitos arquivos? Talvez um NAS seja mais adequado. Este equipamento conta com conexão à rede e diversos slots para colocar os discos.
Por fim, um item de hardware que é opcional mas recomendo é um “no break”, para que em caso de cair a energia na sua casa não aconteça nada.
Tudo, inclusive toda forma de tecnologia, está sujeita a falhas, mas enquanto peças podem ser substituídas, arquivos perdidos podem não serem recuperáveis, por isso surge a necessidade de cópias de segurança, os famosos backups. A regra de ouro é quanto mais importante, raro ou caro mais versões e de mais difícil acesso elas devem ser.
Isso é uma consideração importante principalmente com a Raspberry Pi, os SD cards não são muito confiáveis, depois de alguns anos de uso eles acabam “morrendo”. Comigo foi muito nítido isso, teve um SD card que me serviu fielmente por 2 anos, enquanto outros logo depois de 1 ano de uso contínuo eles morreram. Mesmo adotando alguns truques para diminuir sua leitura e escrita, como montar com a flag noatime, os logs e outras pastas como tmpfs e desativar o swap.
Outra preocupação com os backups são os ataques ransomware, se seu computador teve os arquivos sequestrados, depois de sincronizar os backups também podem estar comprometidos. Por isso é aconselhável ter backups versionados, no qual teremos um "histórico" dos arquivos e no caso de um ransomware, basta restaurar a penúltima versão dos backups no qual os arquivos originais estarão lá.
Uma prática indispensável quando falamos de storage é o Redundant Array of Independent Disks (RAID: Arranjo redundante de discos baratos) que permite combinar os discos para que o sistema operacional os enxergue tudo como um disco só. Os dois modos mais básicos são o RAID 0 e RAID 1. No RAID 0 temos 2 discos que vão somar suas capacidades, enquanto no RAID 1 teremos a capacidade de apenas 1 disco e outro é usado como redundância caso um disco falhe, bastando trocar o disco quebrado que os dados serão espelhados nele.
Existem outros níveis de RAID, que são no fundo combinações do 0 e 1, como o RAID 5 (no qual teremos 4 discos, mas apenas podendo utilizar apenas o espaço de 3, pois 1 drive é usado como redundância).
A fim de combinar os discos utilizando o RAID temos diversas implementações que podem ser usadas no Linux. A mais simples é o mdadm que mapeia os drives num “disco virtual”.
Outra solução um pouco mais avançada é utilizar o LVM que é um gerenciador de volumes que permite coisas mais avançadas como diminuir e aumentar as partições usadas e realizar snapshots, que é um “retrato” do sistema de arquivos que pode ser acessado depois, dessa forma criando um “ponto de restauração”.
Por fim os sistemas de arquivos recentes como BTRFS e ZFS podem ser usados RAID e tem recursos legais como os snapshots, compressão nativa dos arquivos (dessa forma aqueles arquivos de texto como dados em csv ficam bem menor) e por fim como esses sistemas de arquivos usam o conceito de copy-on-write ou seja para toda escrita será feita uma cópia para manter a versão anterior, isso permite que para realizar a manutenção dos disco (o fsck, a checagem da integridade do sistema de arquivos) não precise desligar tudo (nesses sistemas o equivalente do fsck é o scrub).
A única ressalva para usar o ZFS e BTRFS são bancos de dados, o copy-on-write nos bancos de dados prejudica o desempenho, nesses casos talvez seja uma boa manter o sistema operacional num sistema de arquivos tradicional como ext4 e os bancos de dados nele e o armazenamento restante no ZFS ou BTRFS.
Outra preocupação é a criptografia dos discos, para proteger os arquivos em caso de furto, nesses casos é uma boa instalar o pacote dropbear-initramfs (tutorial) que permite entrar com a senha da criptografia de forma remota (por ssh), sem precisar ter um teclado in loco.

Uma regra de ouro dos backups é a regra 3-2-1, que diz que devemos ter ao menos 3 cópias, em 2 mídias diferentes e 1 “fora de casa” em caso de incêndio. Para ter esse backup fora de casa é mais prático usar a nuvem, mas como utilizar a nuvem de forma segura? Podemos utilizar uma solução de backup que tenha criptografia, como o borgbackup, outra opção para utilizar o Google Drive, Dropbox e similares é utilizar o cryptomator.org que criptografa seus dados antes de enviá-los para a nuvem.
Partindo para as indicações, veja o vídeo do Fabio Akita: Quebrei 3 HDs: Entendendo Armazenamento explicando como os discos rígidos funcionam. E o meu texto de como montei minha solução de backups criptografados com o borgbackup e syncthing no Android: Como parei de me preocupar e passei a adorar minha solução de backups.
Em algumas operadoras como a NET, seu modem tem um IP “interno” dentro da rede da operadora, pois os IPs IPV4 são muito escassos, o famigerado Carrier-grade NAT (CGNAT), dessa forma não é possível acessar sua casa através da internet.

O único jeito é ligar na operadora e pedir para sair do CGNAT, permitindo assim hospedar na internet seus serviços. Foi o que fiz (tenho NET), mas não consigo abrir algumas portas como a 80 (http) e 443 (https), pois na NET isso só é permitido comprando o plano para empresas 😞
Pesquise e pergunte no /r/InternetBrasil, lá tem muito conteúdo sobre isso.
Outra questão é que os IPs não são fixos. Dentro da sua casa, quando a Raspberry Pi liga ela “pede” um IP pro seu roteador, o Dynamic Host Configuration Protocol (DHCP) que atribui um IP para a Raspberry Pi, mas os IPs muitas vezes são alocados de sequencial, ou seja nem sempre a Raspberry Pi vai ter o mesmo IP, quebrando o encaminhamento de portas do roteador. Então no roteador na configuração do DHCP atribua um IP fixo para a Raspberry Pi.
Outro IP que não é fixo é o do seu modem, que é o seu IP público na internet, infelizmente às vezes ele acaba mudando (de novo no plano para empresas o IP é fixo), daí surgem os serviços de DNS dinâmico, como o DynDNS ou NOIP, eu utilizo o duckdns e no google domínios tem a opção de DNS dinâmico.
A partir daí é só fazer os encaminhamentos de portas no seu modem, evite a opção DMZ, que expõe completamente a Raspberry Pi na internet, encaminhe apenas as portas que realmente precisa expor. Outra opção é ter um roteador próprio, e o usar o modem da operadora apenas como modem colocando no modo bridge e o seu roteador vai atuar como firewall encaminhando apenas algumas portas. Eu faço isso com meu roteador usando o OpenWRT e criei algumas VLANs (redes lógicas separadas para segregar os equipamentos) para minha rede.
Na mesma linha pode ser utilizada a sua VPS na cloud como proxy para acessar suas coisas em casa, pode ser algo simples como o autossh que cria tunnels ssh permitindo acessar sua casa passando pela VPS.
Ou criar uma VPN com wireguard na sua VPS e conectar sua Raspberry Pi, viabilizando seu acesso externo. O legal dessa solução é que você pode criar duas configurações no seu computador/celular: uma que usa a VPN apenas para acessar seus serviços e uma que passa todo seu tráfego pela VPN para usar em WiFis não confiáveis como WiFis públicos.
Por fim, outra possibilidade é usar o Tor, para criar um .onion que permite hospedar seus serviços em casa, sem precisar abrir suas portas, veja a documentação: onion-services.
Uma preocupação em expor seus serviços na internet é a de segurança, pois os mesmos podem ser hackeados e o hacker estará na sua rede. Isso pode ser feito de forma segura adotando as medidas de segurança que falaremos, mas outra possibilidade é utilizar o port knocking, no qual as portas dos seus serviços ficam fechadas e depois de “bater” numa sequência de portas corretas (tipo uma senha) a porta é aberta, apenas para o IP, e por um período de tempo, escondendo e protegendo seus serviços. Utilizo o knockd com o firewall ufw.
Os contêineres vieram para ficar e são uma maneira simples e rápida para colocar seus serviços no ar. Mas é preciso tomar cuidado em usar apenas imagens confiáveis, no fundo você está rodando um software feito por um terceiro na sua máquina.
Foram encontradas imagens maliciosas minerando bitcoin, ou imagens desatualizadas e vulneráveis. Antes de utilizar uma imagem dá uma olhada no Dockerfile no github para procurar por coisas suspeitas.
Imagens oficiais do dockerhub são confiáveis, outra fonte excelente de imagens é o LinuxServer.io com diversas imagens ótimas.
Partiu para as indicações? Tem um site excelente para aprender docker, bem direto ao ponto o docker-curriculum.com, curso eu indico o docker-mastery na udemy que até fala um pouco de clusters com docker swarm e kubernetes, por fim no youtube tem o vídeo excelente da TechWorld with Nana Docker Tutorial for Beginners.
Quando vamos hospedar diversos serviços uma construção comum que é utilizada é o proxy reverso, com ele quando vamos acessar nossos serviços evitamos de ter que usar uma porta diferente para cada coisa, dessa forma podemos configurar o proxy reverso para como cada serviço vai ser acessado, normalmente por um subdomínio tipo nextcloud.seu-dominio.tld ou como uma subpasta seu-dominio.tld/nextcloud.
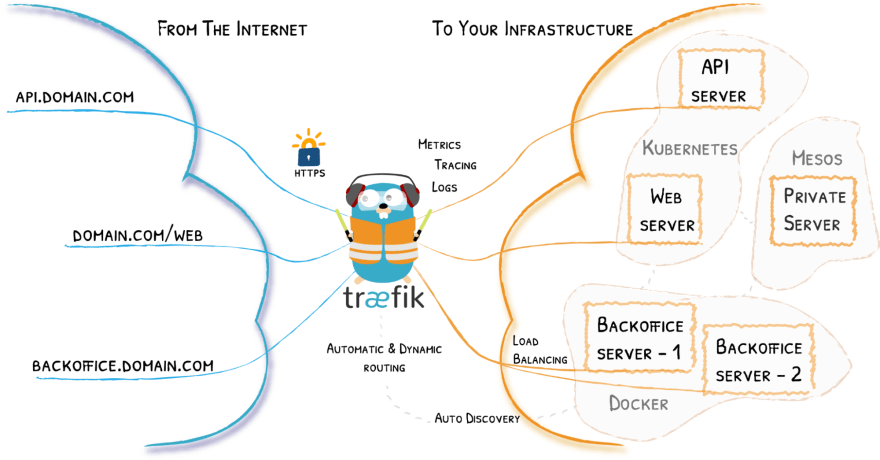
As opções mais populares são o Secure Web Application Gateway (swag), da linuxservers.io, que é um nginx, com let’s encrypt (para ter o https) e fail2ban (que bloqueia bots e IPs que estão tentando te invadir).
A outra opção é o traefik que tem a vantagem de já ser integrado com o docker e kubernetes, dessa forma ao invés de configurar as “rotas” de cada serviço em arquivos de configuração (como é feito no nginx) as configurações vivem nos labels do contêiner de cada serviço, muito mágico ✨
Aliado com o proxy reverso, podemos utilizar o authelia, que permite ter o mesmo usuário e senha (single sign-on) sincronizado com todos seus serviços e autenticação em 2 fatores integrada em todos seus serviços, tornando tudo mais prático e seguro.
Bora para um exemplo?
version: "2.1"
services:
traefik:
image: "traefik:v2.4"
container_name: "traefik"
restart: unless-stopped
command:
#- "--log.level=DEBUG"
- "--api.insecure=true"
- "--providers.docker=true"
- "--providers.docker.exposedbydefault=false"
- "--entrypoints.web.address=:80"
ports:
- "80:80"
- "8080:8080"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro"
whoami:
image: "containous/whoami"
restart: unless-stopped
labels:
- "traefik.enable=true"
- "traefik.http.routers.whoami.rule=PathPrefix(`/whoami/`)"
- "traefik.http.routers.whoami.entrypoints=web"
bitwarden:
image: bitwardenrs/server
container_name: bitwarden
restart: unless-stopped
#environment:
#- SIGNUPS_ALLOWED=false
volumes:
- ./docker_vols/bwdata/:/data/
labels:
- "traefik.enable=true"
- "traefik.http.routers.bitwarden.rule=PathPrefix(`/vault/`)"
- "traefik.http.routers.bitwarden.entrypoints=web"
- "traefik.http.middlewares.bw.stripprefix.prefixes=/vault/"
- "traefik.http.routers.bitwarden.middlewares=bw"Esse é um arquivo docker-compose, é um arquivo yaml que define vários contêineres, no fundo é como se o fizesse vários docker run, um para cada contêiner.
Para executá lo, basta baixar esse arquivo como docker-compose.yml e rodar o docker-compose up -d
Temos 3 contêineres definidos: o traefik, o whoami (usado para debugar o traefik) e o bitwarden (gerenciador de senhas). Repare como as “rotas” para o traefik estão definidas nos labels de cada contêiner ✨
Espere um pouco e vamos testar tudo: abra seu navegador no endereço
localhost/whoami/ , e veja a rota para o whoami funcionando. Depois vá para localhost/vault/ e acesse o bitwarden. Por fim localhost:8080 e veja o dashboard do traefik (não se esqueça de colocar uma senha depois).No bitwarden, repare na parte volumes, aqui os dados da aplicação serão salvos na pasta docker_vols/bwdata, para ser feito o backup.
No traefik, veja em volumes:
/var/run/docker.sock:/var/run/docker.sock:ro, isso vai “conectar” o docker no contêiner do traefik, fazemos isso para que o mesmo consiga “mapear” os outros contêineres e ler suas regras de roteamento em suas labels. Tome cuidado e só faça isso com contêineres que confia pois isso pode dar a permissão de acessar e comprometer os todos seus contêineres e seu computador.Por fim repare que todos os contêineres têm
restart: unless-stopped, isso é a política de restart do docker, dessa forma caso o computador seja desligado quando for ligado os contêineres serão iniciados automaticamente, unless stopped, ou seja a menos que sejam parados.Ultimo exemplo:
version: "2.1"
networks:
web:
external: true
internal_net:
external: false
services:
traefik:
image: "traefik:v2.4"
container_name: "traefik"
restart: unless-stopped
networks:
- web
command:
#- "--log.level=DEBUG"
- "--api.insecure=true"
- "--providers.docker=true"
- "--providers.docker.exposedbydefault=false"
- "--entrypoints.web.address=:80"
ports:
- "80:80"
- "8080:8080"
volumes:
- "/var/run/docker.sock:/var/run/docker.sock:ro"
ttrss:
image: wangqiru/ttrss:latest
container_name: ttrss
restart: unless-stopped
networks:
- internal_net
- web
environment:
- DB_PASS=E7WaTdu9KPLXxYXTqtrA
- SELF_URL_PATH=http://localhost/
- DB_HOST=ttrss_db
- PUID=1000
- PGID=1000
- TZ=America/Sao_Paulo
depends_on:
- ttrss_db
labels:
- "traefik.enable=true"
- "traefik.http.routers.ttrss.rule=PathPrefix(`/ttrss/`)"
- "traefik.http.routers.ttrss.entrypoints=web"
- "traefik.http.middlewares.sp1.stripprefix.prefixes=/ttrss/"
- "traefik.http.routers.ttrss.middlewares=sp1"
- "traefik.docker.network=web"
ttrss_db:
image: postgres:13-alpine
container_name: ttrss_db
restart: unless-stopped
networks:
- internal_net
environment:
- POSTGRES_PASSWORD=E7WaTdu9KPLXxYXTqtrA
volumes:
- ./docker_vols/ttrss_db/:/var/lib/postgresql/data
labels:
- "traefik.enable=false"Continuamos com o nosso conhecido traefik, mas agora vamos colocar no ar o tt-rss, que é um leitor de feeds RSS, que utiliza um banco de dados postgres, essa é a primeira coisa diferente nesse exemplo repare que no topo estão definidas 2 redes (uma chamada web e outra internal_net). O traefik que é o contêiner que está exposto está apenas na web, a aplicação (ttrss) em ambas as redes e o banco de dados apenas na internal_net. Fizemos isso para segregar o banco de dados (que contêm dados sensíveis) do traefik para que o mesmo caso comprometido não acesse o(s) banco de dados.
Outra coisa a destacar é a opção depends_on, que cria um relação de dependência entre o contêiner da aplicação (ttrss) e o seu banco de dados, iniciando o banco de dados antes da da aplicação.
A fim de manter tudo isso seguro, existem diversas práticas e níveis de segurança, um bom começo é ter senhas fortes e únicas (evitar o famoso usuário admin com senha admin) com um gerenciador de senhas e realizar as atualizações de segurança.
Para deixar todos seus contêineres atualizados, tem o Diun, que “conecta” no docker (como fizemos com o traefik) e verifica periodicamente se existem atualizações para seus contêineres, disparando uma notificação via email ou telegram etc …
Já para manter o host atualizado, uma possibilidade é utilizar o UnattendedUpgrades que atualiza os pacotes automaticamente, e se quiser pode até reiniciar automaticamente quando necessário. Porém, talvez seja melhor assinar as listas de email/rss de segurança da sua distro (debian security-announce, Ubuntu USN), do docker e das suas aplicações e frameworks e veja se faz aquelas atualizações de fato te afetam e se realmente faz sentido aplica-lás.

Um site excelente para deixar nos favoritos é o Open Web Application Security Project (owasp) é uma comunidade de segurança com diversas dicas e recomendações, por exemplo: como armazenar senhas de forma segura e no nosso caso Docker security.
Uma forma excelente para aprender segurança é praticar nas Capture the flag (CTF) que são ambientes controlados para testar a segurança como um todo e revelar a flag (tipo uma senha), comprovando que conseguiu comprometer a segurança. Tem vários sites, tenho mais contato com o overthewire e o hackthebox.
Um vídeo que gostei foi do LiveOverflow: Protect Linux Server From Hackers, no qual ele disseca as dicas populares de boas práticas para proteger seus servidores linux e ele mostrou que essas boas práticas nem sempre são tão positivas e “preto no branco”. Depois ele fez uma continuação bem interessante: Understand Security Risk vs. Security Vulnerability! pontuando as diferenças e semelhanças entre riscos de segurança e vulnerabilidades.
Na seção anterior sobre storage, como saberemos se um disco falhou? Quando tudo parar de funcionar? Ou tem algum jeito de “ficar de olho”, por isso que precisamos ter uma solução de monitoramento.
As soluções mais populares de monitoramento são o zabbix e o prometheus, que depois de configurados te notificam em caso de alguma falha.
No caso dos discos, temos dois indicativos que os discos estão para falhar: As informações S.M.A.R.T. -- Self-Monitoring, Analysis, and Reporting Technology (tecnologia de automonitoramento, análise e relatório) geradas pelo próprio disco com diversas informações da "saúde" do disco, o disco não gera isso sozinho, sua solução de monitoramento precisa disparar os auto-testes e monitorar essas infos. Porém um estudo de 2007 do Google, mostrou que os dados S.M.A.R.T sozinho não são um bom indicativo da falha dos discos, daí surgem o segundo indicativo o tempo de escrita e leitura, se o disco começa a demorar muito para ler ou escrever isso pode indicar uma falha, essa informação é gerada na solução de monitoramento.
Outra solução legal de monitoramento é o healthchecks.io, serviço para monitorar seus cronjobs (tarefas executadas periodicamente), por exemplo imagine que você configurou para fazer backup do seu laptop na sua Raspberry Pi, mas por algum problema o backup para de ser feito com sucesso. Como vai saber que parou de funcionar? No healthchecks.io você configura uma periodicidade que os backups devem ser feitos e quando é feito o backup seu laptop “pinga” o serviço, e em caso de falha ou o backup deixou de rodar uma notificação é enviada.
Essa é a parte mais legal 🤩, chegou o dia que seu SD card da Raspberry Pi morreu 😞 , tranquilo só fazer a restauração do backup no SD novo e instalar e configurar tudo mas isso pode ser demorado, com a infraestrutura como código (IaC) você cria uma “receita” que configura toda sua infra automaticamente.
A ferramenta que tenho mais contato é o ansible, ele é similar ao chef e puppet. A principal vantagem do ansible é que ele é agentless, ou seja não precisa de um ter software instalado esperando por instruções do controle, basta ter o python instalado e acesso ssh e na máquina que vai disparar o ansible basta instalar com um pip install, super prático.
Apesar de ser muito legal automatizar a configuração dos ambientes com IaC, se tudo é importante nada é importante, a IaC não precisa estar no topo das suas prioridades quando configurando seu setup.
Espero com essa visão geral dos aspectos do self-hosting tenha uma noção do que se trata e comece a aprender mais sobre o tema e adotar esse movimento.
Além de todas indicações que já fiz vou fechar indicando um podcast: o Self-Hosted podcast que me ajudou muito a aprender sobre esses tópicos e o canal do YouTube: Techno Tim que tem várias dicas de como montar seu homelab.
29