
23
Git - Um breve estudo.

Desde que comecei a estudar programação com maior assiduidade procuro metodologias de documentar o que venho aprendendo de alguma forma. Um amigo recomendou utilizar o Dev.to e minha experiência tem sido bastante positiva.
Sendo assim, irei documentar tudo que acabo estudando ou desenvolvendo, além da solução de problemas que eventualmente venham a ser um percalço no meu processo de aprendizado.
Neste Post irei tratar da utilização do Git. Abordando todos os pontos que estudei e desafios enfrentados durante o estudo. Sintam-se livres para comentar e adicionar dicas adicionais. Posteriormente poderei criar anexos com observações e dicas úteis que edifiquem o conteúdo tratado. Então vamos lá.
Em resumo, o git é um sistema de controle de versionamento. É isso.
Ok, a definição certamente é mais complexa, mas foi a melhor frase que encontrei para definir a função principal do Git. Ele certamente é o sistema de controle de versionamento mais utilizado no mundo, e essa fama se dá pela facilidade de uso, e principalmente no desempenho.
O controle de versão é a atividade de rastrear e gerenciar as mudanças em um código de software. Através dele as equipes de desenvolvimento conseguem realizar múltiplas tarefas e modificações de código com o intuito de adicionar funcionalidades, corrigir bugs entre outras atividades.
Os sistemas de controle de versão guardam as alterações ao longo do tempo em um tipo de banco de dados especial que pode ser visualizado e chamado quando se deseja obter uma certa versão específica do código. Geralmente essa solicitação ocorre quando erros são cometidos e se quer voltar numa versão anterior do código.
Assim como todo software, necessitamos configurar suas opções para que possamos utilizar com maior precisão e utilizar seus recursos com maestria. Desse modo, vamos começar pelo básico.
Para começarmos a utilizar o controle de versão em nossos projetos devemos inicialmente instalar o Git no nossa máquina. Essa instalação pode ser feita através do download do Git através do site oficial do Git.
No meu caso estou utilizando atualmente o Windows 10 Pro e a versão mais atual do Git disponível é esta do dia 06/06/2021.

Após instalado o Git em nosso sistema, devemos fazer as primeiras configurações para utilizarmos o controle de versão adequadamente.
As configurações do utilizador podem ser visualizadas através do comando:
git config --listNuma primeira instalação, algumas informações como o nome do usuário, e-mail e editor padrão por exemplo não terão sido definidas. Sendo assim, configuraremos cada informação.
Antes de nos aprofundarmos nas configurações do Git, quero apenas explanar parcialmente sobre os escopos dos comandos.
O Git guarda as informações em três lugares:
- GitConfig --system:
Altera as configurações para todos os usuários do seu sistema se utilizada a opção
--system - GitConfig do usuário --global:
Altera as configurações apenas para o usuário que está executando o projeto.
--global - GitConfig do projeto:
Altera as configurações apenas do projeto que se está desenvolvendo. O comando para utilizar este escopo é:
git config
Para definir informações que aplicaremos para todos os repositórios de um usuário, utilizaremos a configuração global.
Configurando o user-name:
git config --global user.name "nomedousuario"Configurando o e-mail:
git config --global user.email "seuemail"Você pode utilizar também um editor padrão para o seu código. Por padrão o Vim é utilizado. No meu caso, quero definir meu editor de texto padrão para o VS Code. Você pode utilizar o seguinte comando para utiliza-lo também:
git config --global core.editor "code --wait"Caso você utilize outro editor de texto, sugiro procurar a documentação que trate desta temática.
Essas são as configurações elementares do Git. Para visualizar as configurações definidas, você pode chamar no control cada uma:
git config user.name - No caso do nome do usuário.
git config user.email - No caso do e-mail.
Pronto, a configuração mais básica do git foi feita. Agora, quando realizamos alterações em nosso código e submete-las ao git, essas informações serão levadas também.
Obviamente todo mundo que está desenvolvendo um projeto precisa colocar esse projeto em algum lugar para administrar suas versões, guardar de maneira segura seus dados, enfim, gerenciar todas as atividades desenvolvidas durante o processo de produção. Como eu já disse, o Git auxilia nisso, e para começarmos a executar tais atividades necessitamos criar algo chamado repositório.
O repositório Git armazena todas as alterações feitas em um projeto dentro de uma pasta chamada .git/. Aqui ele constrói algo como uma linha do tempo que armazena cada alteração enviada. Cada alteração guarda um código Hash único que poderá ser chamado posteriormente para consulta dos dados armazenados. Vou detalhar tudo a seguir. Vamos partir para a inicialização e cada etapa será explanada.
Para iniciarmos um repositório devemos antes de qualquer coisa ter um projeto, neste caso vou criar um diretório através do terminal do Win10.
mkdir git-projectDepois de criado o diretório, podemos adicionar um novo arquivo, no nosso caso irei criar um HTML para simular algumas alterações.
touch index.htmlPronto, agora temos um repositório chamado git-project e dentro dele temos um arquivo chamado index.html. Vamos imaginar que esse é o nosso super projeto, iremos usa-lo por hora para explicar alguns conceitos.
Agora que já temos o mínimo para iniciar o repositório, podemos prosseguir com o estudo.
Vamos inicializar um novo repositório para o diretório criado, a inicialização é feita através do seguinte comando:
git initQuando inicializamos um repositório através do comando supracitado, o Git cria um repositório vazio o .git/ com subdiretórios para objects, refs/heads, refs/tags arquivos e models. Além disso, cria uma branch vazia sem nenhum commit. (Veremos mais sobre branches em breve).
Bom citar que existem outros tipos de Git Init, não pretendo me aprofundar muito, mas para efeito de informação temos:
git init Transforma o diretório atual num repositório Git.
git init <directory> Transforma um diretório especificado num repositório Git.
git init --bare Cria um novo repositório vazio (um repositório para ser usado apenas como um repositório remoto). Esse tipo de init é utilizado em servidores e são considerados apenas repositórios para armazenamento. Ele facilita a troca de informações entre os desenvolvedores. No link a seguir você pode ver um pouco sobre a diferença entre git init e git bare.
Caso você inicialize um repositório Git num diretório errado você pode remover o repositório muito facilmente. Basta utilizar o comando $ rm -rf .git e pronto, seu repositório local foi removido.
Caso exista o .gitignore/ e .gitmodules/ você pode exclui-los também utilizando o comando $ rm -rf .git*
Quando executar, sugiro visualizar se alguma pasta oculta ainda existe.
Tudo pronto, aprendemos a iniciar um repositório local no nosso Git. Agora podemos começar a manipular arquivos livremente. A partir daqui somos capazes de realizar alterações em nosso código e transferi-los entre status. A seguir vamos entender o ciclo de vida de arquivos e como eles se comportam no Git.
O ciclo de vida dos arquivos é uma descrição bem grosseira para referenciar os status que cada arquivo passa durante o processo de produção de um projeto.
Quero explicar antes de tudo cada um dos status para melhor entendimento do assunto.
Os status são situações (num grosso modo) que os arquivos se encontram. Esses status são:
Untracked - O arquivo acabou de ser adicionado mas ainda não foi visto pelo Git
Unmodifier - Quando o arquivo foi visto pelo git mas não foi modificado.
Modified - O arquivo foi modificado.
Staged - Área onde será criada a versão.

Como vemos na imagem, existem regras que levam um arquivo de um status para outro. Seguindo o fluxo podemos definir como sendo:
Untracked -> Unmodified
Quando adicionamos um arquivo e ele é visto pelo Git e não tem modificações, ele passa a ter o status de unmodified.Unmodified -> Modified
Quando qualquer alteração no arquivo é executada.Modified -> Staged
Quando a modificação é salva no Git. Neste momento ela ainda não foi efetivada.Staged -> Unmodified
Essa alteração se dá quando realizamos um commit, aqui um código hash da modificação é gerada e nosso arquivo está apto a receber novas mudanças do código para um novo commit.Unmodified -> Untracked
Quando removemos um arquivo.
Podemos visualizar o status de cada arquivo atráves de um comando que o Git nos fornece, o git status.
Este comando exibe algumas informações relevantes sobre os status dos nossos arquivos, essas informações podem ser:
- Onde o arquivo está.
- Os commits realizados.
- Se existe algum commit pendente.
Aqui podemos ver alguns exemplos:
Arquivo house.html foi criado mas não foi visto pelo Git.

Aqui o arquivo foi adicionado através do comando git add house.html. Ele passa para o estágio stage e está pronto para ser commitado.

Aqui o arquivo foi commitado, ou seja, criamos uma snap (ou espelho) das modificações que estarão salvas num código hash que podemos utilizar posteriormente.

O commit é feito através do comando git commit -m "First commit"
-m = comando para passarmos uma mensagem.
"" = A mensagem é passada entre as aspas.
A partir desse momento o arquivo tem o status de unmodified pois ele foi criado, adicionado e commitado. Agora o Git aguarda modificações do arquivo.

Quando modifico o arquivo ele vai para o status de modified e aguarda ser transferido para o status staged. E o ciclo se inicia novamente.

Como podemos ver, entender os ciclos não é muito complexo. Caso você tenha alguma dúvida, existe um curso gratuito na udemy que pode te auxiliar em todo o contexto de entendimento básico do Git.
A própria documentação do Git pode te auxiliar nisso também. O link abaixo te direciona para um artigo que explica mais detalhadamente os status do Git.
https://git-scm.com/docs/git-status
Sei que já falei bastante de commits, que precisamos dele para subir alterações num projeto e bla bla bla, mas não cheguei a explicar ele muito bem. Vou fazer a boa e dar uma breve introdução sobre commits para ficamos alinhados a partir daqui.
Bom, o git commit é usado para salvar alterações num repositório local. E esse comando só funciona quando arquivos são inseridos para serem commitados, ou seja, quando passamos esses arquivos para o status staged através do comando git add.
Quando commitamos informações de um arquivo criamos uma cópia dos arquivos no que podemos chamar de espelho. Cada espelho guarda todas as informações do commit, como um código hash por exemplo, que seria basicamente um ID único que nomeia aquele commit. Quando precisamos retornar as informações de um determinado commit, é esse código hash que utilizamos. Além do hash, temos também quem realizou o commit e quando foi feito. Posteriormente explicarei a estrutura de informações do commit quando estivermos estudando o git log.
Acho importante frisar que o commit adiciona no repositório LOCAL as alterações realizadas, ou seja, para inserirmos num remoto, precisamos de outro comando que subiria para o GitHub por exemplo, mas nos limitaremos apenas a Git neste artigo.
Quando vamos realizar commits, podemos comparar as alterações entre os arquivos através do comando git diff. As alterações são listadas conforme a seguir:

A partir desse ponto iremos falar muito sobre branches. É um assunto bem recorrente quando começamos a trabalhar em projetos com outras pessoas, sendo assim, é um conceito que precisamos entender bem para manipular com mais eficiência nosso processo de produção.
Branch é exatamente o que diz a palavra se traduzida, são ramos. Esses ramos são criados para que possamos trabalhar de maneira organizada em nossos projetos. Isso porque nossos repositórios são como uma árvore, onde temos uma estrutura base(o tronco) e dela derivam todas as ramificações(os galhos).
Quando criamos um repositório, ele contem uma branch principal chamada branch master da qual derivam todas as outras branches. Na imagem abaixo é exibida como é a estrutura de ramos dos nossos repositórios.

Ao criarmos uma nova branch temos agora duas linhas de trabalho diferentes, onde podemos executar modificações em nosso projeto sem impactar diretamente no funcionamento do mesmo. Isso permite para nós desenvolvedores, criamos funcionalidades e testa-las sem impactar no projeto principal.
Como eu disse, quando criamos um projeto novo, ele já contém uma branch, a branch master. Podemos verificar isso digitando:
git status. Ele exibirá exatamente em qual branch estamos.

Além disso, podemos ver quais branches estão disponíveis no nosso projeto a partir do comando git branch.

O asterisco exibe em qual branch estamos no momento. Note que existe outra branch ativa chamada feature, nela poderemos desenvolver ferramentas para nosso projeto e depois vincular as alterações a branch master.
Para criarmos uma nova branch, basta executarmos o comando git checkout -b nomedabranch

Quando criamos uma nova branch, automaticamente a branch ativa é trocada. Acima o próprio git nos informa que "NovaBranch" é a branch ativa no momento, sendo assim, as alterações no código que forem efetuadas, estarão vinculadas a essa branch específica.
Para excluirmos uma branch criada, o comando que podemos executar é git checkout -D nomedabranch. Desse modo, a branch especificada será removida do nosso projeto.
Para mudarmos para outra branch existente basta digitarmos o comando git checkout nomeDaBranch. Assim, iremos trocar a branch ativa.

Note que após executado o comando, o git nos informa que mudamos a branch ativa. Na imagem acima, faço a mudança para a branch master.
Você pode acessar esse artigo do medium para entender um pouco mais sobre branch e manipulação.
Sabendo disso, podemos partir para as próximas partes do artigo. Lembrando que manipulação de branches é de extrema importância caso queiramos trabalhar com grandes projetos.
git logO log tem relação direta com o seu significado em português, registro. Com esse comando você pode visualizar as informações de registro de um commit realizado. Caso tenha interesse, você pode ler sobre esta função aqui.
Supondo que temos um projeto já criado, o git já iniciado, e commits já executados, podemos visualizar os commits e as informações pertinentes a cada um apenas utilizando o comando git log.

Se executar o comando, poderemos ver algo bem semelhante a imagem acima. Para descrever melhor cada informação, temos então:
- Commit - código Hash único que nomeia o commit
- Author - Quem que executou o commit
- Date - Data que o commit foi realizado
- Mensagem - Por último a mensagem que foi passada através do
git commit -m "sua mensagem". É importante descrever bem o que foi executado para que posteriormente possamos identificar com melhor precisão um commit em específico.
Podemos visualizar as logs exibindo a relação entre as branches através do seguinte comando git log --decorate.
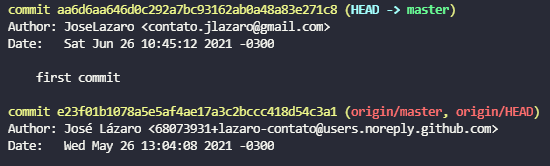
Diferente do git log convecional, podemos ver agora as branches de cada commit realizado.
Para visualizarmos apenas os commits realizados por um autor em específico, podemos utilizar o comando git log --author "Nome do Autor". Veja o exemplo.

Aqui o que se exibe são as mesmas informações do git log só que filtradas por autor.
Podemos visualizar de forma gráfica as branches dos commits realizados com o comando git log --graph, é bem útil caso queiramos ter uma melhor visualização do fluxo de trabalho que estamos executando no projeto.

A linha lateral mostra o caminho que percorremos durante os commits. Note que todos os commits realizados neste caso ilustrado foram realizados diretamente na branch master, não é uma prática recomendada quando estamos trabalhando com mais pessoas e diversas outras funcionalidades. Existem metodologias de fluxo de trabalho que utilizam branches para melhor desenvolvimento de aplicações. Vamos conhecer uma delas em breve.
Caso desejemos visualizar a relação de commits realizada por autor, podemos visualizar com o comando git log shortlog

A lista de commits por autor exibida pelo shortlog nos mostra a quantidades de commits, e a mensagem passada em cada commit. É bem útil caso queiramos visualizar quem executou determinada alteração no código.
Caso queiramos visualizar as quantidade de commits sem exibir a mensagens, basta adicionar o comando -sn na frente do código. Sendo assim, git log shortlog -sn.

Como eu já disse, a hash de um commit serve para retornar dados referente a ele e fazer algumas alterações quanto ao projeto. O git show "código hash da branch" mostra os detalhes de um commit específico.

Existe uma documentação do próprio Git que trata do Git show. Você pode verificar aqui no link: https://git-scm.com/docs/git-show
Quando fazemos alterações em arquivos é bem natural que existam erros e bugs. Quando executamos alterações que influenciam negativamente na usabilidade da ferramenta que estamos desenvolvendo muitas vezes necessitamos retornar para versões antigas até que um problema seja corrigido. Para nos auxiliar no gerenciamento de versões, podemos utilizar algumas funções específicas do Git. Vamos conhecer algumas delas.
O comando git checkout opera em três entidades distintas: os arquivos, os commits e as branches.
Uma descrição mais precisa da função do checkout descrita pela Atlassian é:
O checkout pode ser utilizado para visualizar commits antigos além de realizar operações nas branches criadas. A verificação das branches é semelhante à verificação de commits e arquivos antigos, e novas alterações são salvas no histórico do projeto — ou seja, não é uma operação apenas de leitura.
O git checkout permite a navegação entre branches. A verificação de uma branch atualiza os arquivos no diretório atual para que fique igual à versão armazenada na branch referenciada e diz ao Git para gravar todos os novos commits nessa branch.
Quando estamos desenvolvendo, é natural que alguns erros sejam cometidos, utilizar a linha do tempo do Git é muito útil caso queiramos manipular arquivos ao bel prazer.
Quando estamos editando arquivos e eles passam do status unmodified para modified, podemos retornar essas alterações através do comando git checkout NomeDoArquivo. Veja o exemplo a seguir:
Aqui existe um arquivo chamado house.html, ele está com status unmodified. Farei uma pequena modificação para visualizarmos a função do git checkout na prática.
Arquivo sem nenhuma modificação:

Arquivo modificado:

Quando executamos o comando git checkout house.html ele retorna o arquivo do status modified para o status unmodified, sendo assim, as alterações deixam de existir e o arquivo volta ao seu estágio inicial.

Podemos observar com o git diff que não existe nenhuma modificação. Sendo assim, o arquivo voltou ao seu estágio de unmodified.
Como vimos, o checkout retorna um arquivo do status modified para unmodified. Ou seja, não tem influencia quando adicionamos um arquivo para staged ou quando ele é commitado. Para suprir essa necessidade, podemos utilizar outros comandos bem comuns para nos auxiliar. O git reset e suas opções.
O comando git reset HEAD NomeDoArquivo retorna um arquivo do status staged para o status modified, desse modo, podemos fazer alguma pequena alteração antes de um commit ser realizado.
Na imagem abaixo realizei uma alteração no arquivo house.html e o adicionei ao status staged através do comando git add * (o asterisco adiciona todos os arquivos modificados).
Quando o arquivo passou para o status de staged utilizei o comando git reset HEAD house.html para retornar o status do arquivo especificado house.html para o status de modified. Podemos ver que após executado o próprio git nos informa o que foi executado.
Unstaged changes after reset:
M house.html
Além do git reset HEAD temos outras 3 variações de reset que devem ser utilizadas em situações distintas. Cada um dos comandos altera de forma específica o status de cada arquivo. As formas do git reset que temos são:
git reset --soft
git reset --mixed
git reset --hard
É bom explanar que, quando queremos modificar um arquivo do comando reset, devemos sempre referenciar a hash do commit anterior ao que se está tentando dar reset. Para ilustrar posso usar os commits da imagem a seguir:
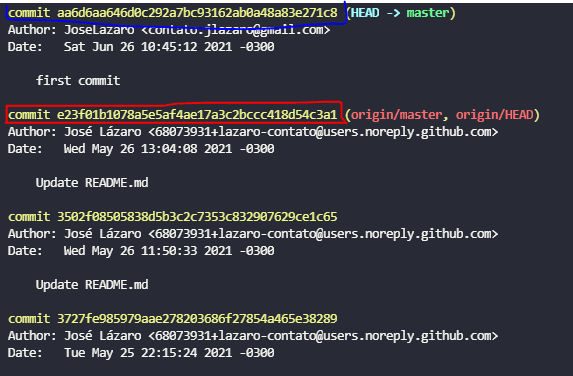
Caso eu queria realizar modificações no commit grifado com azul, eu devo utilizar o reset referenciando o último commit antes do alvo, neste caso, o hash grifado em vermelho. Sabendo disso, podemos seguir com a explicação.
git reset --soft
Retorna o commit para o status staged.
Utilizamos este comando quando realizamos um commit num arquivo e desejamos corrigir ou adicionar algo.
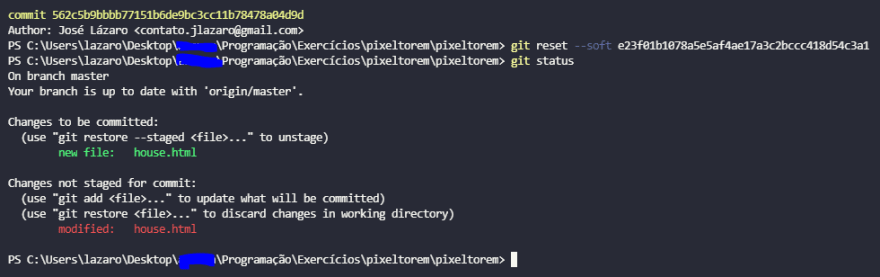
git reset --mixed
Retorna o commit para o status modified.
Aqui o commit retorna para antes de ser adicionado, apenas para o momento que foi modificado. Sendo assim, o status modified.

git reset --hard
Este comando elimina totalmente o seu commit, e retorna para o commit do hash que você está referenciando. Tudo depois dele será eliminado.
Log antes do git reset. No comando iremos referenciar o segundo commit.

Após o git reset --hard podemos notar que os commits posteriores ao referenciado deixam de existir.

É importante lembrar que quando fazemos alguma alteração do tipo, essas alterações são feitas no repositório local, quando se trata de repositórios remotos alguns problemas podem surgir, como conflito de informações entre arquivos por exemplo.
Quando estamos desenvolvendo aplicações em times e precisamos realizar modificações em códigos, adicionar novas funcionalidades ou corrigir bugs, utilizamos as branches do Git para trabalhar.
Ao finalizamos as alterações, precisamos mover essas alterações para a branch principal (master) para que nossas funcionalidades sejam aplicadas ao projeto. Sendo assim, temos duas metodologias de fluxo de trabalho que podemos seguir para executarmos nossas alterações devidamente. São elas o Merge e o Rebase.
Para explicar o processo de produção do Merge utilizarei a imagem a seguir. Ela exemplifica o mapa de commits num Merge. Os seus detalhes explicarei a seguir.

Na ilustração acima podemos notar a presença de duas branches, a master e a feature. Em cada uma das branches são executados commits de acordo com as modificações realizadas. Num determinado momento, os commits realizados na branch feature precisam ser enviados para a branch master. Desse modo, garantimos que a aplicação receba o que foi desenvolvido em outras ramificações.
Para melhor entendimento, deixe-me descrever melhor:
- C1 - O primeiro commit realizado na branch master
- C2 - Segundo commit realizado. Aqui foi criada a nova branch chamada feature. A partir daqui começamos a dividir o nosso fluxo de trabalho para o desenvolvimento de uma nova funcionalidade.
- C3 - Na nova branch feature, começamos a realizar commits que inserem as configurações da funcionalidade que queremos implementar.
- C4 - Em paralelo ao desenvolvimento na branch feature, temos modificações executadas na própria master. Essas alterações são exibidas no commit C4.
- C5 - As últimas modificações da feature são efetuadas e a partir daqui precisamos unir nossas alterações realizadas na branch feature, com nosso projeto da master.
- C6 - A união das duas branches acontece através do commit C6, e temos agora todas as modificações do código realizadas na feature pertencendo a branch master.
Gostaria de fazer uma simulação de um Merge na prática, desse modo sinto que visualizar o código será mais efetivo para concretizar o conhecimento.
Configurações do projeto
- Diretório chamado merge
- Arquivo
index.htmlque será modificado - Duas branches presentes, a branch master e outra chamada feature.
O arquivo index.html foi iniciado e commitado na branch master. Alternamos agora para a branch Feature e criamos um novo arquivo chamado index.js, iremos commita-lo na branch feature. Após isso, realizamos um novo commit na branch master. Após essas alterações podemos realizar um Merge entre as branches, vinculando as alterações da branch Feature com a branch Master.Desse modo temos a estrutura de commits das duas branches ilustrada a seguir.

Descrevendo o fluxo de commits de cada branch:
Master
Apenas o commit do index.html que chamei de first commit.

Feature
Criamos uma nova branch e commitamos um novo arquivo chamado index.js na nova branch feature. Abaixo podemos verificar os commits realizados.
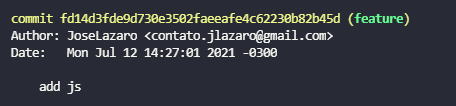
Como podemos ver, temos dois commits, o primeiro realizado na branch master e o o segundo na branch feature.
Master
Alternamos para a branch master e realizamos um novo commit, dessa vez alterando o conteúdo do arquivo index.html.

Agora precisamos unir as alterações das branches através do Merge. Para realizamos um merge, utilizamos o comando:
git merge featureO comando acima junta a branch feature com a branch master. Lembrando que para o comando funcionar, você precisa estar na branch master, onde a feature será mesclada. A imagem a seguir exibe a união das duas branches. O arquivo index.js foi adicionado, logo tivemos uma nova inserção.

Agora podemos verificar o histórico de commits em forma de gráfico com o comando git log --graph. Ele exibe todo o fluxo de commits e nos mostra também de onde surgiu determinado commit.
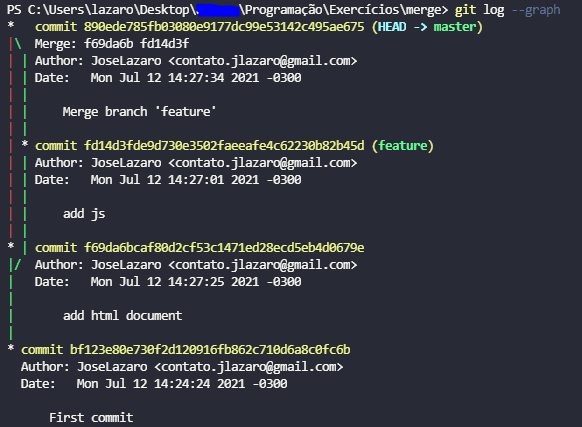
Pela ordem de commits temos:
- first commit realizado na branch master;
- add html document realizado na branch master;
- add js realizado na branch feature;
- merge, união entre as duas branches.
A branch master agora contém todas as alterações realizadas na branch feature e na própria branch master.
Com isso podemos finalizar essa breve introdução ao Git. Você pode utilizar este artigo para fins de consulta. Aprender a teoria de assuntos é muito importante para nos aprofundarmos em algum estudo, mas não se sinta pressionado a decorar cada um dos comandos, programar exige mais capacidade de aprender a consultar do que decorar métodos.
Pretendo atualizar este guia inicial periodicamente, colocando dicas que vocês podem me mandar ou que eu posso acabar descobrindo, sintam-se livres para opinar nos comentários. Até a próxima.
23