
40
So what *is* privacy? (In the context of privacy tech)
Privacy, as a concept, often lacks a clear definition. However, privacy-enhancing technologies can be generally categorised into two broad desiderata. The purpose of this post is to lay these goals out clearly in accessible terms.
When someone talks about privacy, what on earth do they mean? If you consult a dictionary, you'll likely get a definition based on not being observed by others and free from public or third-party attention. This could lead to many definitions in the context of technology. The term can range in context from preventing browser tracking through cookies, to limiting your digital footprint from being shared by data holders. At Oblivious, we focus on the latter, allowing organizations who collect information to use and manipulate it in a safe and secure manner, such that you (a data subject) can rest assured that no superfluous data sharing is performed.
Indeed the definition of privacy can cause a lot of confusion. Lawyers, politicians, security experts, and technologists all talk about privacy but often mean quite different things. If you reading this you are maybe aware of privacy-enhancing technologies (PETs) which are technological ways of dealing with privacy problems that, frankly speaking, often arise due to the exploitation of other data technologies that no legal frameworks can sufficiently deal with. Federated learning, homomorphic encryption, differential privacy, secure enclaves are all examples of PETs, which come in handy when you want to ensure privacy.
In short, the two major groups of privacy technology are:
Let’s start with the first scenario wherein two millionaires want to determine who is richer but do not want to reveal each others' wealth. This is a classic 40-year old problem in computer science called Yao’s millionaire’s problem. It forms the basis of so-called multi-party computation or input privacy. It describes situations when two or more parties wish to evaluate a joint function depended on everyone's sensitive inputs, however, they do not want to reveal those inputs to each other.
Here, a range of solutions may be employed. All the parties can simply give their inputs to a trusted friend, lawyer or consulting company as often happens in real life. However, if they want to employ cryptography they have even more options - they can use secure multi-party computation protocols (SMPC), which evaluate a function directly on encrypted data. It is based on a range of cryptographic primitives, which are still heavily researched - from garbled circuits to homomorphic encryption. A caveat here is that using these approaches severely slows down the computation and as always with new cryptographic protocols one has to be very careful with the threat models employed and how different subprotocols are combined. If you make a mistake at this step, it could have the consequence of not encrypting the data in the first place!

Another option is to refer to hardware-based approaches called trusted execution environments or secure enclaves, whereby the parties send their encrypted data to a chip or a virtual machine (VM) with additional security layers. This chip or the cloud provider hosting the VM cryptographically sign and hash the software that is run that combines the data, attesting to the data providers that it is safe for the data to be decrypted. Major chip and cloud providers have moved towards this direction under the umbrella of confidential computing in recent years. As an example, AWS has recently launched its Nitro Enclaves and you can read more about this in our previous blog post.
All three options have their pros and cons, you are either trusting in humans, cryptography, or the chip/cloud providers cryptographic attestation and consequently they are bottlenecked by human (bureaucracy and human processing), cryptographic (often large packet sizes with many rounds of communication) or hardware-based (RAM) limitations. Nevertheless, all three tackle this challenge of data collaboration.
Let’s say we have chosen our favourite approach to input privacy and each party is happy that nobody else can see their sensitive inputs. They might even use it multiple times with slightly different inputs and parties. Can they safely announce the end of their “privacy problem”? Well, not really as we have not looked carefully at the output of this function!
If one or more parties receive the output, there surely is some information about each others' input in it. It may well be that by running it multiple times with different inputs the others can work out our inputs from the outputs. To prevent this in many cases output privacy techniques can be employed.
Output privacy challenges are very well-known to statistics bureaus. Wherever you live, it is quite likely that within the last 10 years you have taken part in a census. When the census data is aggregated and shared, statistics bureaus employ statistical disclosure control techniques to ensure that no individual or house can be identified from the published data.
How do you do that? One technique that helps in this is the so-called k-anonymity. It is very intuitive and you have probably used or thought about it already without being aware of it. When releasing data you group people together and publish data for that group. For example, you group people under the age brackets, districts, etc, and ensure that in the smallest identifiable group there is at least k number of people.
Output privacy challenges are very well-known to statistics bureaus. Wherever you live, it is quite likely that within the last 10 years you have taken part in a census. When the census data is aggregated and shared, statistics bureaus employ statistical disclosure control techniques to ensure that no individual or house can be identified from the published data.
How do you do that? One technique that helps in this is the so-called k-anonymity. It is very intuitive and you have probably used or thought about it already without being aware of it. When releasing data you group people together and publish data for that group. For example, you group people under the age brackets, districts, etc, and ensure that in the smallest identifiable group there is at least k number of people.
Another option, which is very often used in data science, is synthetic data. Large corporates that work with external parties such as data science consultants do not usually give away their proprietary data during the pilot phases of joint projects or for testing purposes but instead often give them fake data that resemble and share statistical properties of the underlying data.
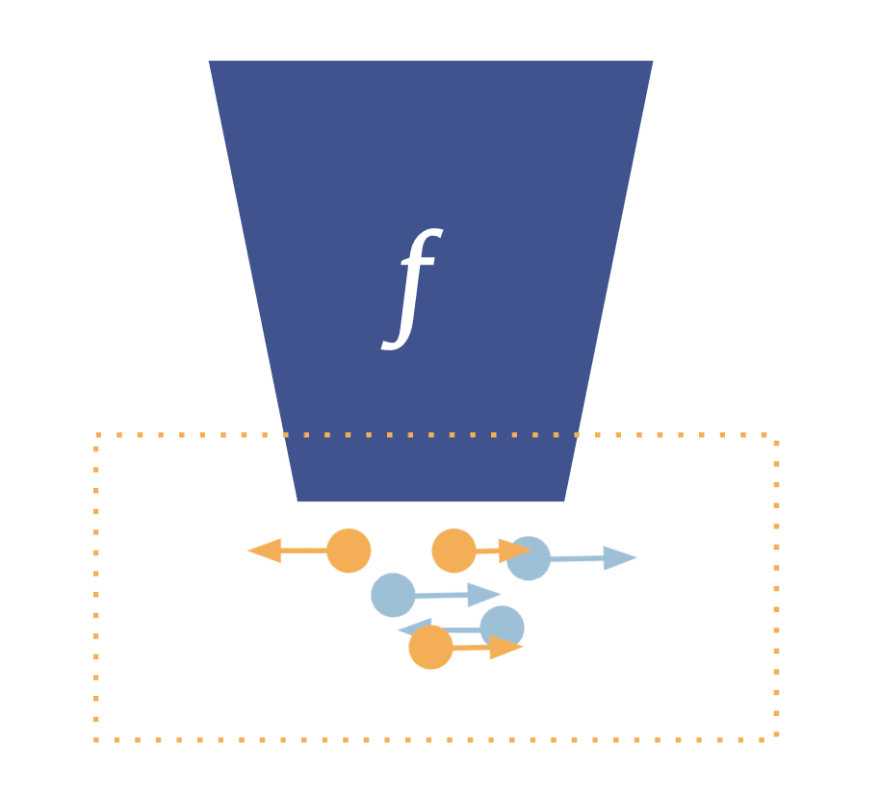
The US census bureau has decided to use another cryptographic technique called differential privacy for its 2020 census. Differential privacy is gaining usage and popularity due to its mathematical guarantees and widespread applicability. It works by adding appropriate noise to the output of a function. The challenge here is to add such amount of noise that the output still provides useful information but prevents anyone who has access to that output from reverse-engineering the original data - in particular information about individuals. The rule of thumb is that the larger the dataset, the smaller noise needs to be added to the aggregated output to ensure privacy. Hence, the large-scale data published by the census bureau are equal to what the true underlying value that they would normally publish is. However, at the township or district level, the noise kicks in and the values differ slightly.
Reading the above, you might be thinking that these sound very different and, well, you are kind of right! Input privacy really takes into account each known party and their interactions in a calculation. It prevents each party from learning something they shouldn't be able to about other parties' inputs. Output privacy does the same for the party who receives the output of a calculation - typically limiting their ability to learn about individuals rather than aggregates.
Now that we are pros when speaking about input privacy and output privacy techniques, it becomes natural to combine them together to ensure privacy in a larger set of use cases. We can evaluate join queries over data coming from multiple sources both without seeing the data in plaintext and giving guarantees about the output privacy. Such end-to-end privacy systems are something that we at Oblivious are very much focused on. If you want to have a run at playing with how secure enclaves can be used in conjunction with differentially private output guarantees, give us a shout!
Now that we are pros when speaking about input privacy and output privacy techniques, it becomes natural to combine them together to ensure privacy in a larger set of use cases. We can evaluate join queries over data coming from multiple sources both without seeing the data in plaintext and giving guarantees about the output privacy. Such end-to-end privacy systems are something that we at Oblivious are very much focused on. If you want to have a run at playing with how secure enclaves can be used in conjunction with differentially private output guarantees, give us a shout!
As a bonus for making it to the end of the article, we thought we'd map some privacy-tech buzzwords to the type of privacy they enforce. Hopefully, at the next (socially distanced) cocktail party you go to when the cryptographer starts spouting on about one of these you'll at least have a bearing on what they are trying to achieve:

40