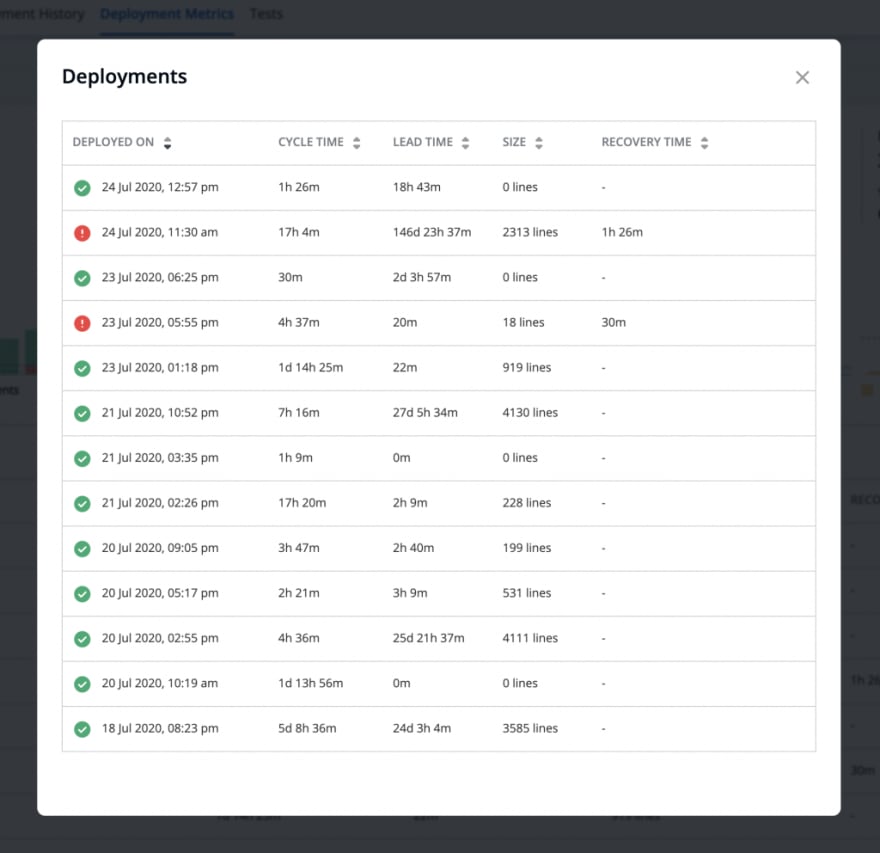
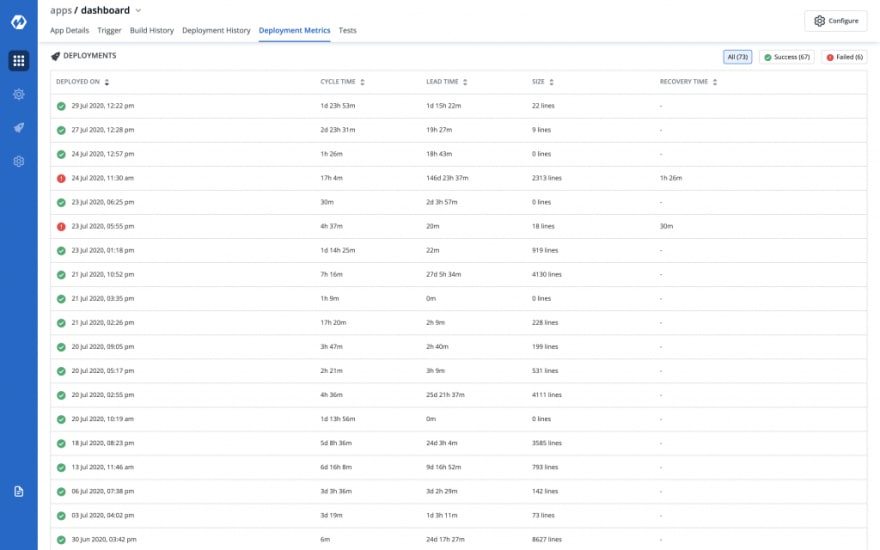
![]()
Devtron is an open source software delivery workflow for kubernetes written in go
Explore documentation »
Website
·
Blog
·
Join Discord
·
Twitter

📖 Menu
- Why Devtron
- Features
- Getting Started
- Documentation
- Compatibility Notes
- Community
- Contribute
- Vulnerability Reporting
- License
💡 Why Devtron?
It is designed as a self-serve platform for operationalizing and maintaining applications (AppOps) on kubernetes in a developer friendly way
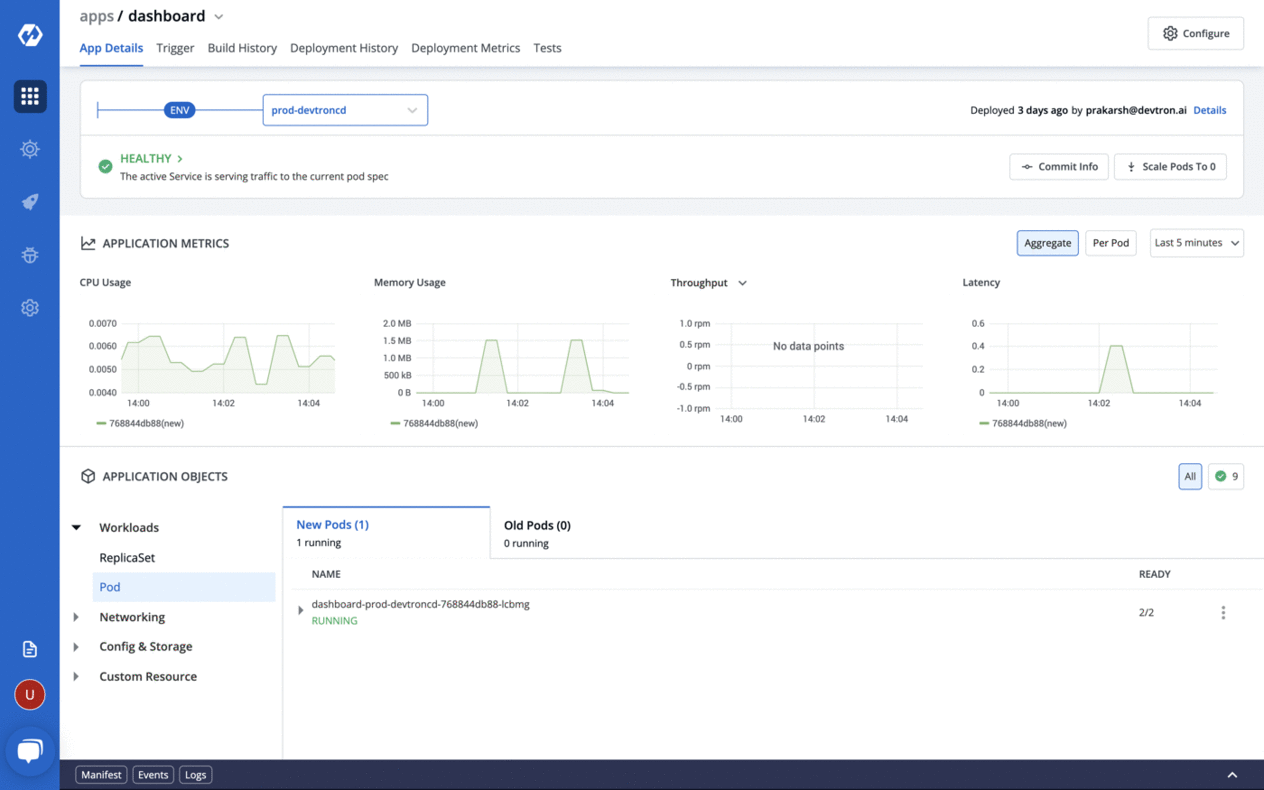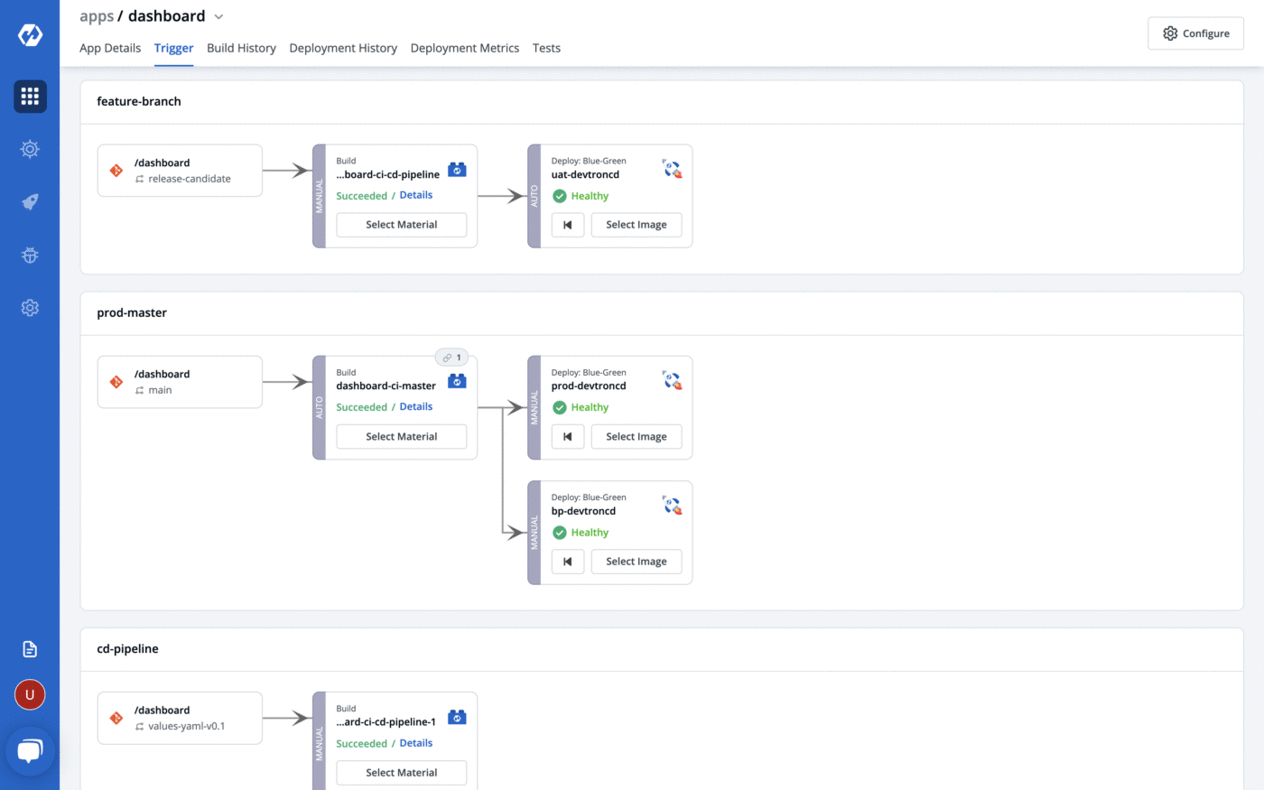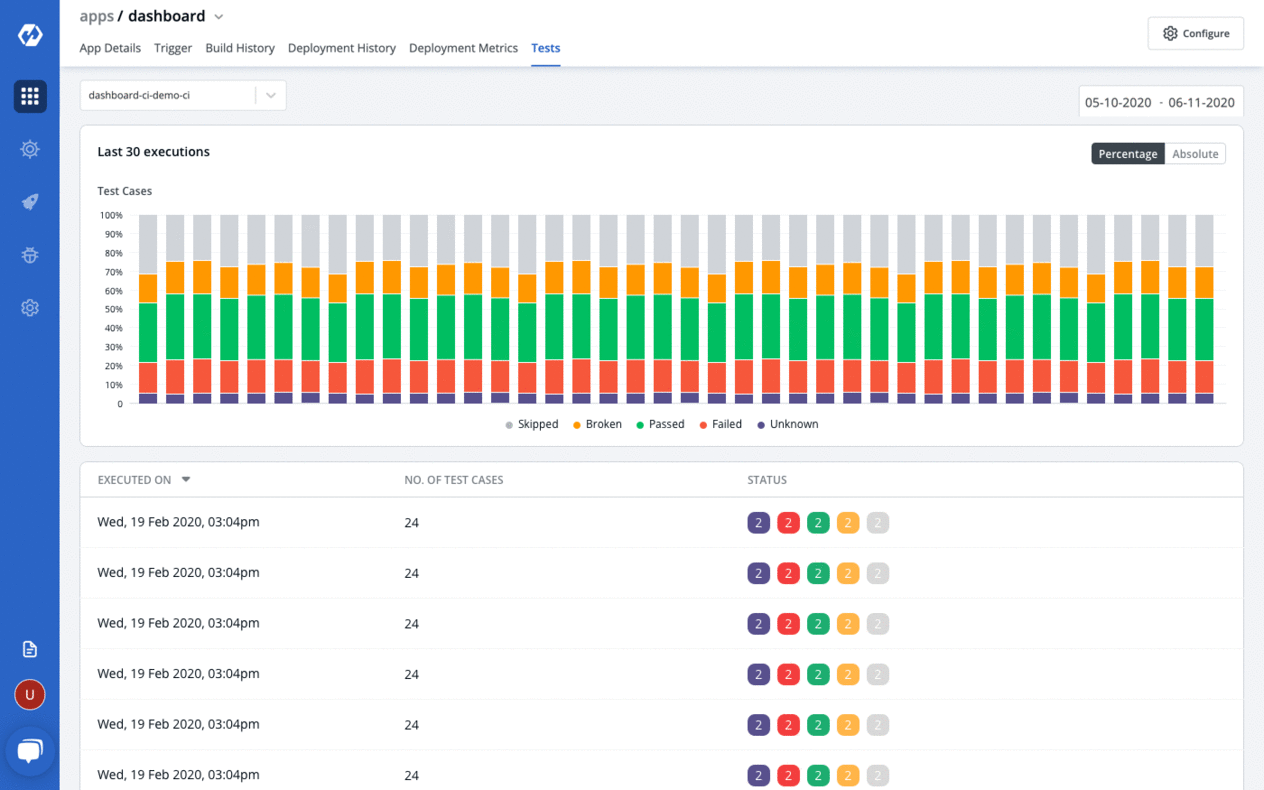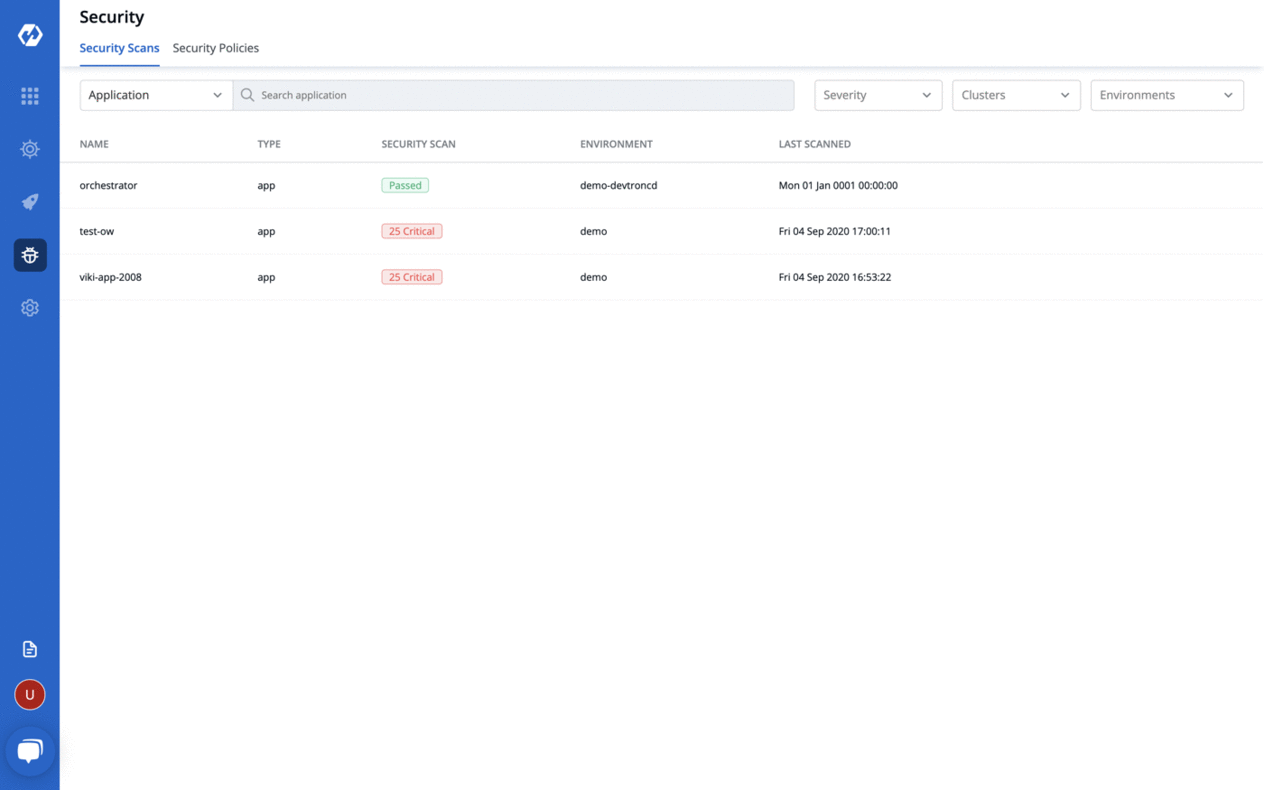
🎉 Features
Zero code software delivery workflow
- Workflow which understands the domain of kubernetes, testing, CD, SecOps so that you dont have to write scripts
- Reusable and composable components so that workflows are easy to contruct and reason through
Multi cloud deployment
- Deploy to multiple kubernetes cluster
Easy dev-sec-ops integration
- Multi level security policy at global, cluster, environment and application for efficient hierarchical policy management
- Behavior driven security policy
- Define policies and exception for kubernetes resources
- Define policies for events for faster resolution
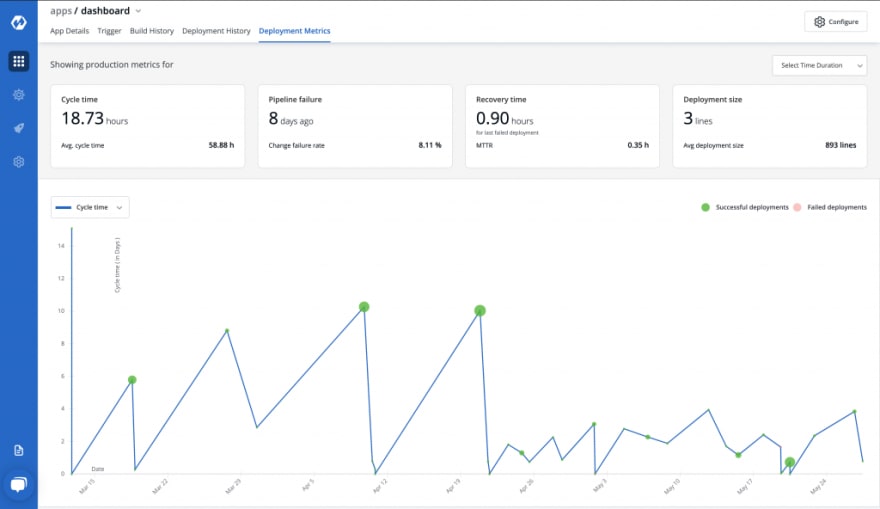
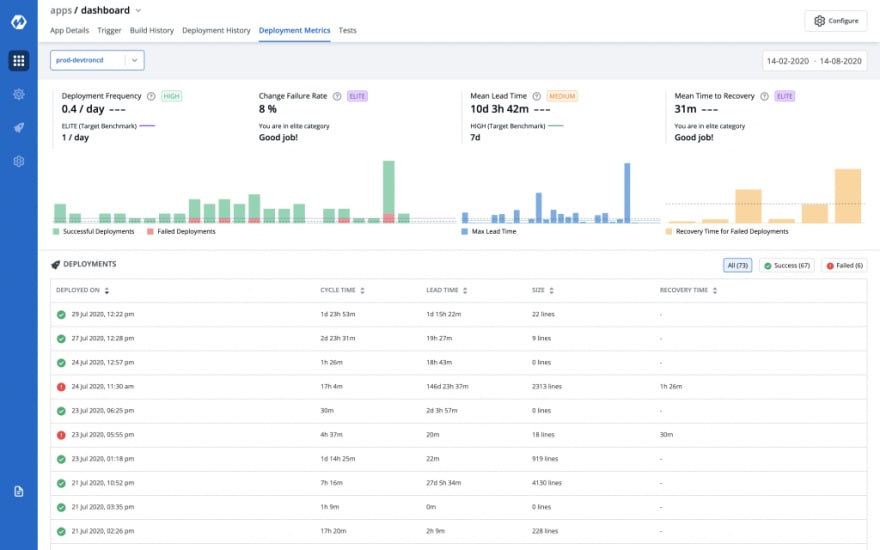
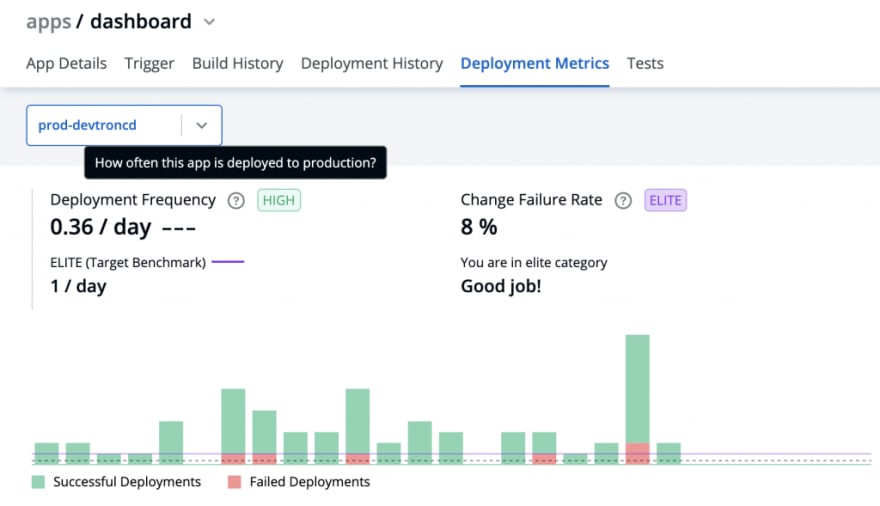
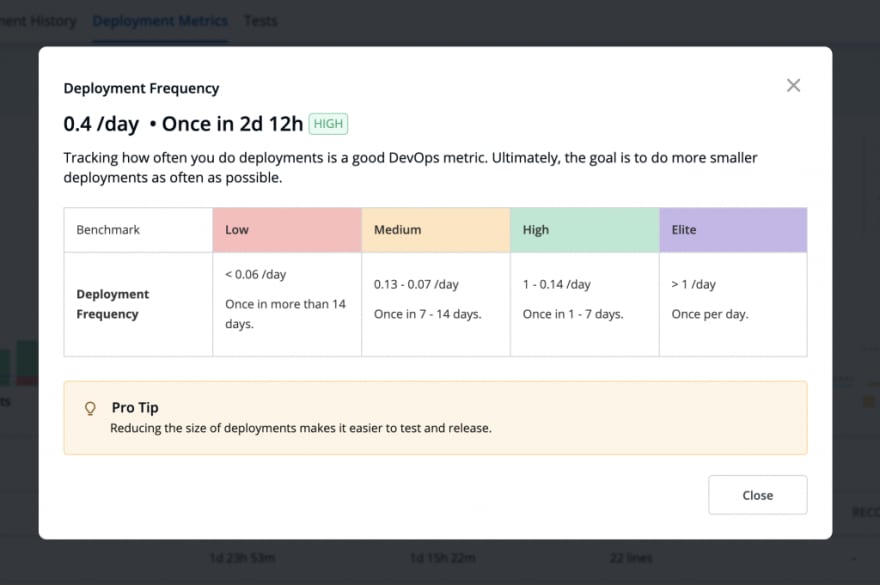
Application debugging dashboard
- One place…