



48
Donald Trump Hates It: Distributed Development Using Micro Frontends
In the beginning of July I gave a new talk about distributed web development using micro frontends. The talk was focused around different repository (and therefore devops) strategies that you can utilize for distributing frontend work. I also tried to touch various ways of combining these frontend fragments (at build-time, server-side rendering, or composed within the client, i.e., browser).
Since I just finished (and... finally!) published my book about micro frontends I'd like to recap the talk here.
So #happy that my #book #art of #microfrontends has finally been #published! packt.live/3wk2fkX Thanks to the whole team at @PacktPub and everyone contributing!
17:00 PM - 07 Jul 2021



In short, this his how the book looks like on Amazon.

But enough about the book, let's recap the talk's content.
When the so-called pizza team (i.e., max. 8 persons that can be fed by one slice of pizza) got popular the efforts to perform efficient modularization also increased. With that being said you can boil it down to:

In any case after the success of microservices and the tendency to build larger and more complex frontends, the need for more distribution on the web frontend also increased. Micro frontends are not new - in fact many patterns and ideas are as old as the web. What is new is that these patterns are somewhat becoming ordinary now - reflected by a common term and crazy people like me to work almost exclusively in that area.
One of the challenges with micro frontends is that there are multiple ways of implementing them. In order to pick the "right" way you'll need a decent amount of experience and a great understanding of the problem in front of you.
Especially the understanding of the domain problem is not always easy. Personally, I've rarely had a complete set of requirements when a project was started. Quite often the set of requirements has been claimed to be complete, but retrospectively the only constant was that these requirements sometimes changed quite drastically within the project.
It should not be a big surprise that existing solutions therefore are using the full architecture solution space:
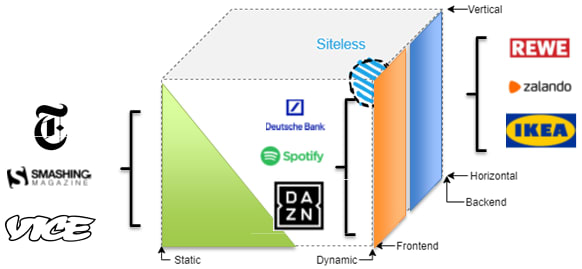
While content-heavy companies are relying on a rather static composition at build-time, e-commerce solutions are tending to compose frontend fragments dynamically in their backend.
App-like experiences are fine with a client-side composition where the micro frontends are orchestrated in the browser.
So let's go into the different strategies of distributing the work in one or more repositories.
The first one to mention may be among the most popular patterns for distributed frontends in general; a monorepo.
The monorepo is a single repository that hosts multiple packages. There are many tools to create monorepos, applications such as Lerna, Nx, or Yarn (with Workspaces) are great tools to manage their complexity.
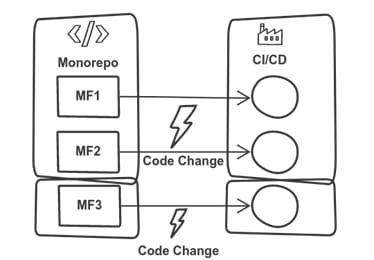
The following diagram illustrates the essential relationship between the code and its build pipeline using this pattern.
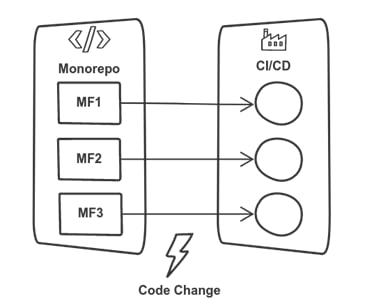
Using the central monorepo all teams work in the same repository. Therefore, deployments are also handled centrally. For real distributed development, where each team is fully autonomous with respect to their toolset, this is not really the ideal setup. Nevertheless, the high UI consistency, and the ease of distributed frontend development (which can be easily combined at build-time) make this pattern attractive.
You can find an example project using this strategy on Azure DevOps:
In the example project a single monorepo has been set up, which uses three distinct packages:
In the most simple case bar-pilet and foo-pilet just export components which are imported directly. Going for this I'd not really label the solution "micro frontends".
Therefore, for the example, I've picked a rather fancy way to "loosely" get the micro frontends at runtime using a file called feed.json, which is created at build-time using the information which micro frontends (called pilets in this case, because I am using the Piral framework) are actually available. Therefore, just adding, e.g., a third micro frontend easily works without touching the app-shell package.
With the monorepo and build-time fusion in mind we can go one step further and decompose the monorepo into individual repositories. The exception is the build pipeline, which remains in the monorepo and aggregates the individual repositories into a single (fat) pipeline.
Any change in any repository will trigger the "giant" build of the (fat) pipeline.
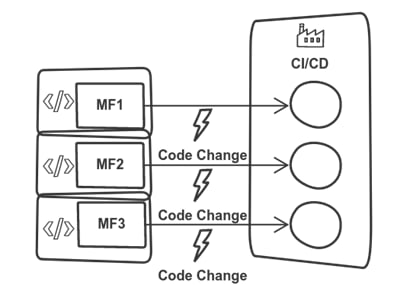
You can find an example project using this strategy on Azure DevOps:
The
pipeline repository hosts two files; one is the pipeline definition that actually needs to know the names of the other repositories:resources:
repositories:
- repository: 'self'
- repository: 'app'
type: git
name: app
ref: main
trigger:
branches:
include:
- main
- repository: 'mf1'
type: git
name: mf1
ref: main
trigger:
branches:
include:
- main
- repository: 'mf2'
type: git
name: main
ref: master
trigger:
branches:
include:
- main
pool:
vmImage: 'ubuntu-latest'
stages:
- stage: Build
displayName: Build
jobs:
- ...The other part is a simple script that puts all micro frontends as direct dependencies to the app shell. We could also do it as previously - reference them loosely via a generated feed.json file, however, this way we can improve performance even more and obtain a loading experience as known from SPAs directly. No indirection at startup.
The magic for this enhancements lies in the file pilets.ts, which originally looked like this:
export default [];The file is modified before the build to contain the static information from the different micro frontends.
In the previous pattern we scattered the repositories, but kept the single pipeline. What if we wanted to do it the other way round? Does it even make sense?
It turns out, it may be useful. Potentially, we want to develop the UI incl. all fragments in a central place, but we still want to leave room for each team to have their own deployment processes. Maybe to make them faster, maybe due to secret or other process managements.
In any case, this is how it looks like on paper.
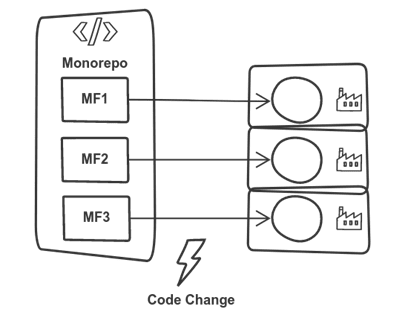
This pattern makes also sense if the individual pipelines should be kept small and may be connected to further (e.g., elevation) processes.
You can find an example project using this strategy on Azure DevOps:
The code of this example is quite similar to the first code part, except that we are not generating a feed.json file here. Instead, we rely on a dedicated service for this, which consumes the micro frontends from an NPM registry. This also explains why we want to deploy individual packages; with a service in the backend we can dynamically decide which micro frontends to actually deliver to the user.
If we are anyway going to create independent micro frontends we can already distribute the code, too. Therefore, having totally independent repositories with their own build processes makes sense.
This is the most familiar pattern from a Git setup, but the most difficult one to manage correctly. Questions like: How can I efficiently debug the micro frontend solution if all I have is a single micro frontend come up quickly. In this post I'll not go into details here.
Luckily, we use Piral which makes this quite easy. All it takes for a great development and debugging experience is the emulator package that Piral creates from the app shell's repository. This can be shared easily via an NPM registry.

You can find an example project using this strategy on Azure DevOps:
Each repository is publishing its artifact into the private NPM registry.
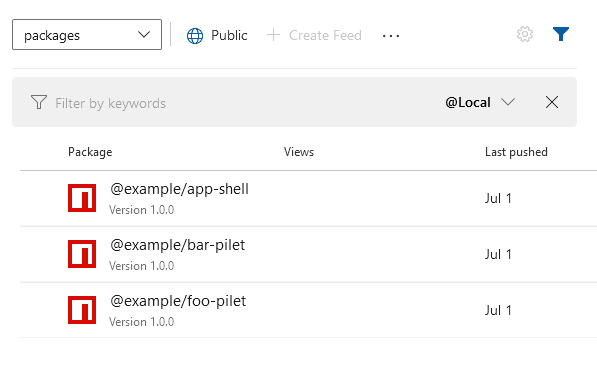
This way we have full control what we do with the packages. We also see (and use) their available versions.
Quite naturally, we may not even have to decide for a pattern. We could also take a mix of these patterns, e.g., have a monorepo approach for the core micro frontends, but then use individual repositories for auxiliary micro frontends.
The pattern could be drawn like this, even though many other combinations are possible, too:
There is a certain impact of the chosen team structure on the ideal repository pattern. Either way, the chosen pattern should fit well to the teams' expectations.
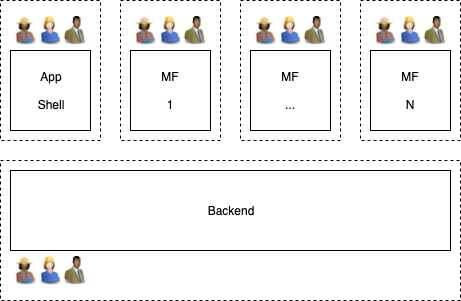
Note that some team configurations are more ideally suited for micro frontends than others.
One example of this is the vertical development configuration, where each team is rather self sufficient:
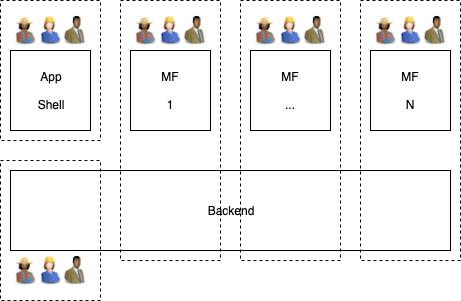
A more popular variant is the creation of real fullstack teams:
Realistically, a mixed development approach may be the go-to option here. That way, you won't need to create teams with principles that are not fitting to the team members' mindsets. Also, while the majority of devs may say they are fullstack, in reality only a minority is. Having knowledge of JavaScript does not make one a Node.js expert. Likewise, having shifted some pixels via CSS does not mean you are a frontend guru now.
The core advantage of using micro frontends is that you can now cut the teams closer to their desires - leaving them with the right degree of freedom to make them productive.
That's the talk in a nutshell. I hope I could share something interesting. If you like this then don't hesitate to get the book. Also make sure to follow me on Twitter for discount links and further information.
48