
19
Mastering Web Scraping in Python: From Zero to Hero
Website scraping is much more than extracting content with some CSS selectors. We summarized years of expertise in this guide. With all these new tricks and ideas, you'll be able to scrape data reliably, faster, and more performant. And get some extra fields that you thought were not present.
For the code to work, you will need python3 installed . Some systems have it pre-installed. After that, install all the necessary libraries by running
pip install.pip install requests beautifulsoup4 pandasGetting the HTML from a URL is easy with the requests library. Then pass the content to BeautifulSoup, and we can start getting data and querying with selectors. We won't go into much detail. In short, you can use CSS selectors to get page elements and content. Some require a different syntax, but we'll discover that later.
import requests
from bs4 import BeautifulSoup
response = requests.get("https://zenrows.com")
soup = BeautifulSoup(response.content, 'html.parser')
print(soup.title.string) # Web Data Automation Made Easy - ZenRowsTo avoid requesting the HTML every time, we can store it in an HTML file and load BeautifulSoup from there. For a simple demo, we can do this manually. An easy way to do that is to view the page source, copy and paste it into a file. It is essential to visit the page without being logged in, as a crawler would do.
Getting the HTML in here might look like a simple task, but nothing farther from the truth. We won't cover it in this blog post, but it deserves a complete guide. Our advice is to use this static approach since many websites will redirect you to a login page after a few requests. Some others will show a captcha, and in the worst-case scenario, your IP will get banned.
with open("test.html") as fp:
soup = BeautifulSoup(fp, "html.parser")
print(soup.title.string) # Web Data Automation Made Easy - ZenRowsOnce we load statically from a file, we can test as many times as possible without any networking or blocking problem.
Before we start coding, we have to understand the page's content and structure. For that, the easier way we know is to inspect the target page using a browser. We will be using Chrome's DevTools, but other browsers have similar tools.
We can open any product page on Amazon, for example, and a quick look will show us the product's name, price, availability, and many other fields. Before copying all those selectors, we recommend taking a couple of minutes to look for hidden inputs, metadata, and network requests.
Beware of doing this with Chrome DevTools or similar means. You will see the content once the Javascript and network requests have (maybe) modified it. It is tiresome, but sometimes we must explore the original HTML to avoid running Javascript. We won't need to run a headless browser - i.e., Puppeteer - if we find everything, saving time and memory consumption.
Disclaimer: we won't include the URL request in the code snippets for every example. They all look like the first one. And remember, store an HTML file locally if you are going to test it several times.
Hidden inputs allow developers to include input fields that end-users cannot see nor modify. Many forms use these to include internal IDs or security tokens.
In Amazon products , we can see that there are many more. Some will be available in other places or formats, but sometimes they are unique. Either way, hidden inputs' names tend to be more stable than classes.

While some content is visible via UI, it might be easier to extract using metadata. You can get view count in numeric format and publish date in YYYY-mm-dd format in a YouTube video . Those two can be obtained with means from the visible part, but there is no need. Spending a few minutes doing these techniques pays off.
interactionCount = soup.find('meta', itemprop="interactionCount")
print(interactionCount['content']) # 8566042
datePublished = soup.find('meta', itemprop="datePublished")
print(datePublished['content']) # 2014-01-09Some other websites decide to load an empty template and bring all the data via XHR requests. In those cases, checking just the original HTML won't be enough. We need to inspect the networking, specifically the XHR requests.
That's the case for Auction . Fill the form with any city and search. That will redirect you to a results page with a skeleton page while it performs some queries for the city you entered.
That forces us to use a headless browser that can execute Javascript and intercept network requests, but we'll see its upsides also. Sometimes you can call the XHR endpoint directly, but they usually require cookies or other authentication methods. Or they can instantly ban you since that is not a regular user path. Be careful.
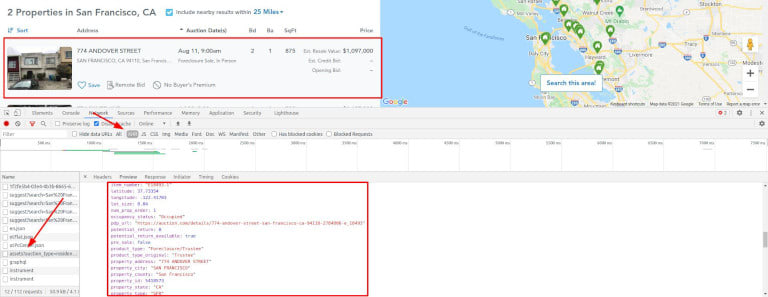
We struck gold. Take another look at the image.
All the data you can have, already clean and formatted, is ready to be extracted. And then some more. Geolocation, internal IDs, numerical price with no format, year built etcetera.
Set aside your urges for a second. Getting everything with CSS selectors is an option, but there are many more. Take a look at all these, and then think again before using selectors directly. We are not saying those are bad and ours great. Don't get us wrong.
We are trying to give you more tools and ideas. Then it will be your decision every time.
Now, we will start using BeautifulSoup to get meaningful content. This library allows us to get content by IDs, classes, pseudo-selectors, and many more. We will only cover a small subset of its capabilities.
This example will extract all the internal links from the page. For simplicity's sake, only links starting with a slash will be considered internal. In a completer case, we should check domain and subdomains.
internalLinks = [
a.get('href') for a in soup.find_all('a')
if a.get('href') and a.get('href').startswith('/')]
print(internalLinks)Once we have all those links, we could deduplicate and queue them for future scraping. By doing it, we would be building a whole website crawler, not just for one page. Since that is an entirely different problem, we wanted to mention it and prepare a blog post to handle its usage and scalability. The number of pages to crawl can snowball.
Just a note of caution: be prudent while running this automatically. You can get hundreds of links in a few seconds, which would result in too many requests to the same site. If not handled carefully, captchas or bans will probably apply.
Another common scraping task is to extract social links and emails. There is no exact definition for "social links," so we'll obtain them based on domain. As for emails, there are two options: "mailto" links and checking the whole text.
We will be using a scraping test site for this demo.
This first snippet will get all the links, similar to the previous one. Then loop over all of them, checking if any social domains or "mailto" are present. In that case, add that URL to the list and finally print it.
links = [a.get('href') for a in soup.find_all('a')]
to_extract = ["facebook.com", "twitter.com", "mailto:"]
social_links = []
for link in links:
for social in to_extract:
if link and social in link:
social_links.append(link)
print(social_links)
# ['mailto:****@webscraper.io',
# 'https://www.facebook.com/webscraperio/',
# 'https://twitter.com/webscraperio']This second one is a bit more tricky if you are not familiar with regular expressions. In short, they will try to match any text given a search pattern.
In this case, it will try to match some characters (mainly letters and numbers), followed by [@], then again chars - the domain - [dot] and finally two to four characters - Internet top-level domains or TLD. It will find, for example,
test@example.com.Note that this regex is not a complete one because it won't match composed TLDs such as
co.uk.We can run this expression in the entire content (HTML) or just the text. We use the HTML for completion, although we will duplicate the email since it's shown in the text and an href.
emails = re.findall(
r"[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}",
str(soup))
print(emails) # ['****@webscraper.io', '****@webscraper.io']HTML tables have been around forever, but they are still in use for displaying tabular content. We can take advantage of that since they are usually structured and well-formatted.
Using Wikipedia's List of best-selling albums as an example, we will extract all the values to an array and a pandas dataframe. It is a simple example, but you should manipulate all the data as if it came from a dataset.
We start by finding a table and looping through all the rows ("tr"). For each of them, find cells ("td" or "th"). The following lines will remove notes and collapsible content from Wikipedia tables, not strictly necessary. Then, append the cell's stripped text to the row and the row to the final output. Print the result to check that everything looks fine.
table = soup.find("table", class_="sortable")
output = []
for row in table.findAll("tr"):
new_row = []
for cell in row.findAll(["td", "th"]):
for sup in cell.findAll('sup'):
sup.extract()
for collapsible in cell.findAll(
class_="mw-collapsible-content"):
collapsible.extract()
new_row.append(cell.get_text().strip())
output.append(new_row)
print(output)
# [
# ['Artist', 'Album', 'Released', ...],
# ['Michael Jackson', 'Thriller', '1982', ...]
# ]Another way is to use
pandas and import directly the HTML, as shown below. It will handle everything for us: the first line will match the headers, and the rest will be inserted as content with the right type. read_html returns an array, so we take the first item and then remove a column that has no content.Once into a dataframe, we could do any operation, like ordering by sales, since pandas converted some columns to numbers. Or sum all the claim sales. Not truly useful here, but you get the idea.
import pandas as pd
table_df = pd.read_html(str(table))[0]
table_df = table_df.drop('Ref(s)', 1)
print(table_df.columns) # ['Artist', 'Album', 'Released' ...
print(table_df.dtypes) # ... Released int64 ...
print(table_df['Claimed sales*'].sum()) # 422
print(table_df.loc[3])
# Artist Pink Floyd
# Album The Dark Side of the Moon
# Released 1973
# Genre Progressive rock
# Total certified copies... 24.4
# Claimed sales* 45As seen before, there are ways to get essential data without relying on visual content. Let's see an example using Netflix's The Witcher . We'll try to get the actors. Easy, right? A one-liner will do.
actors = soup.find(class_="item-starring").find(
class_="title-data-info-item-list")
print(actors.text.split(','))
# ['Henry Cavill', 'Anya Chalotra', 'Freya Allan']What if I told you that there are fourteen actors and actresses? Will you try to get 'em all? Do not scroll further if you want to try it by yourself. I'll wait.
Nothing yet? Remember, there's more than meets the eye. You know three of them; search for those in the original HTML. To be honest, there's another place down below that shows the whole cast, but try to avoid it.
Netflix includes a Schema.org snippet with the actor and actress list and many other data. As with the YouTube example, sometimes it is more convenient to use this approach. Dates, for example, are usually displayed in "machine-like" format, which is more helpful while scraping.

import json
ldJson = soup.find("script", type="application/ld+json")
parsedJson = json.loads(ldJson.contents[0])
print([actor['name'] for actor in parsedJson['actors']])
# [... 'Jodhi May', 'MyAnna Buring', 'Joey Batey' ...]Some other times this is a practical approach if we don't want to render Javascript. We'll show an example using Instagram Billie Eilish's profile . They are known blockers. After visiting a few pages, you will be redirected to a login page. Be careful while scraping Instagram and use local HTML for testing.
We'll cover how to avoid those blocks or redirects in a future post. Stay tuned!
The usual way would be to search for a class, in our case "Y8-fY". We advise against using these classes since they will probably change. They look autogenerated. Many modern websites use this kind of CSS, and it gets generated for every change, which means that we cannot rely on them.
Plan B:
"header ul > li", right? It will work. But we need Javascript rendering for that since it is not present on the first load. As stated before, we should try to avoid that.Take a look at the source HTML: title and description include followers, following, and post numbers. It might be a problem since they are in string format, but we can get over it. If we only want that data, we won't need a headless browser. Great!
metaDescription = soup.find("meta", {'name': 'description'})
print(metaDescription['content'])
# 87.9m Followers, 0 Following, 493 Posts ...Combining some of the techniques already seen, we aim to extract product information that is not visible. Our first example is a Shopify eCommerce, Spigen .
Take a look on your own first if you want.
Hint: look for the brand 🤐.
We'll be able to extract it reliably, not from the product name nor the breadcrumbs, since we cannot say if they are always related.

Did you find them? In this case, they use "itemprop" and include Product and Offer from schema.org. We could probably tell if a product is in stock by looking at the form or the "Add to cart" button. But there is no need, we can trust on
itemprop="availability". As for the brand, the same snippet as the one used for YouTube but changing the property name to "brand."brand = soup.find('meta', itemprop="brand")
print(brand['content']) # TeslaAnother Shopify example: nomz . We want to extract the rating count and average, accessible in the HTML but somewhat hidden. The average rating is hidden from view using CSS.
There's a screen reader only tag with the average and the count near it. Those two include text, not a big deal. But we know we can do better.
It is an easy one if you inspect the source. The Product schema will be the first thing you see. Applying the same knowledge from the Netflix example, get the first "ld+json" block, parse the JSON, and all the content will be available!
import json
ldJson = soup.find("script", type="application/ld+json")
parsedJson = json.loads(ldJson.contents[0])
print(parsedJson["aggregateRating"]["ratingValue"]) # 4.9
print(parsedJson["aggregateRating"]["reviewCount"]) # 57
print(parsedJson["weight"]) # 0.492kg -> extra, not visible in UILast but not least, we will take advantage of data attributes, which are also common in eCommerce. While inspecting Marucci Sports Wood Bats , we can see that every product has several data points that will come in handy. Price in numeric format, ID, product name, and category. We have there all the data we might need.
products = []
cards = soup.find_all(class_="card")
for card in cards:
products.append({
'id': card.get('data-entity-id'),
'name': card.get('data-name'),
'category': card.get('data-product-category'),
'price': card.get('data-product-price')
})
print(products)
# [
# {
# "category": "Wood Bats, Wood Bats/Professional Cuts",
# "id": "1945",
# "name": "6 Bat USA Professional Cut Bundle",
# "price": "579.99"
# },
# {
# "category": "Wood Bats, Wood Bats/Pro Model",
# "id": "1804",
# "name": "M-71 Pro Model",
# "price": "159.99"
# },
# ...
# ]All right! You got all the data from that page. Now you have to replicate it to a second and then a third. Scale is important. And so is not getting banned.
But you also have to convert this data and store it: CSV files or databases, whatever you need. Nested fields are not easy to export to any of those formats.
We already took enough of your time. Take in all this new information, use it in your everyday work. Meanwhile, we'll be working on the following guides to overcoming all these obstacles!
We'd like you to go with three lessons:
Each of these has upsides and downsides, different approaches, and many, many alternatives. Writing a complete guide would be, well, a long book, not a blog post.
Remember, we covered scraping, but there is much more: crawling, avoiding being blocked, converting and storing the content, scaling the infrastructure, and more. Stay tuned!
Do not forget to take a look at the rest of the posts in this series.
And if you liked the content, please share it.
Originally published at https://www.zenrows.com
19