
37
Streaming Fauna Documents with Python
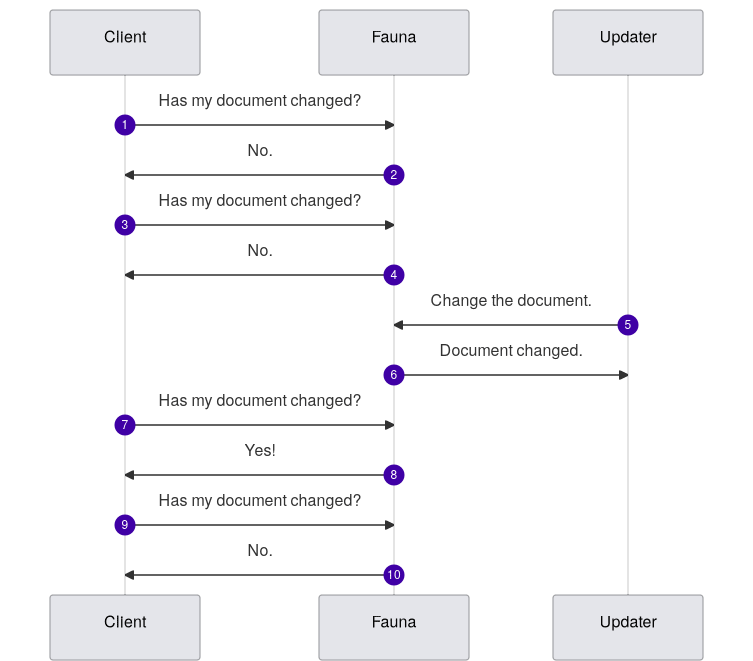
With Fauna’s document streaming feature, you can get real-time updates about changes made to your database.
In this tutorial, you will learn how to use Fauna’s document streaming feature in a Python application.
Here for the code alone? Head over to the implementation section of this article.
Streaming refers to when a program continuously reads and fetches data from a given source in real-time. For example, while watching a YouTube video or downloading a file from the internet, you stream the data from the origin and process it on your client’s device instantaneously.

Streaming, in some ways, can arguably be a better alternative to polling. Polling refers to when a client periodically makes queries to a data source to get updates. It is more expensive than streaming as the client sends many requests only to get a single update or none at all. Polling is only aware of changes when the query results return.
NOTE: The rest of this article assumes you have a fair understanding of Fauna and Python. Check out my introductory tutorial first if you don't.
We need to first create the database to use in Fauna’s dashboard. If you have not created an account on Fauna before now, do so here.
In the dashboard, click on the
NEW DATABASE button, provide a name for the database, then press SAVE. We will also be ticking the Pre-populate option to get demo data that will be used in this article:

Then, we need to create a security key to connect the database to the application. Go to the
Security tab on the Fauna sidebar (located on the left side of the screen), click the NEW KEY button, provide the necessary information, and press SAVE:
Fauna will then present you with your
Secret Key. Copy the key immediately and store it somewhere easily retrievable because it will only be displayed once.Fauna features built-in support for document streaming. Whenever changes in a particular document are streamed, all the clients subscribed to it will be notified in real-time.
Let’s write some code to implement this functionality!.
First, we will install the Fauna Python driver, importing the required libraries, and creating a database client.
In the terminal, type:
pip install faunadbAfter that, create a Python script and save the code below in it:
from faunadb import query as q
from faunadb.objects import Ref
from faunadb.client import FaunaClient
client = FaunaClient(secret="FAUNA_SECRET_KEY")Next, we will fetch the document from the Fauna database collections that we want to stream:

doc = client.query(
q.get(
q.ref(q.collection("customers"), "101")
)
)We will start by defining an
on_start function, which will be triggered when a document stream starts:def on_start(event):
print(f"started stream at {event.txn}")
data = {
"firstName": "John",
"lastName": "Smith",
"telephone": "719-872-4470"
}
client.query(q.update(doc["ref"], {"data": data}))In our
on_start function, we printed out the current timestamp of the transaction emitting the event (in microseconds) provided by event.txn. Then, the streamed document, so Fauna notifies our application in real-time.Next, we will define an
on_version function. It will be triggered when there is a change in the streamed document and Fauna has sent a notification to the subscribing application:def on_version(event):
print(f"on_version event at {event.txn}")
print(f"Event action: {event.event['action']}")
print(f"Changes made: {event.event['diff'].get('data')}")In our
on_version function, we printed out the current timestamp again (in microseconds), then printed out the event action provided by event.event['action']. We then printed out the changes made to the document.After that, we will define an
on_error function. It will be triggered when an error occurs while processing the data in the on_version:def on_error(event):
print(f"Received error event {event}")In our
on_error function, we printed out the event that triggered the issue along with its error message.We will now begin document streaming:
options = {"fields": ["document", "diff", "action"]}
stream = client.stream(doc["ref"], options, on_start, on_error, on_version)
stream.start()In the code above, we defined the fields we want in every event update. Then, we passed the
on_start, on_error, and on_version functions to the stream object and triggered it with the start method. You should get an image like the one below when the entire script executes:

NOTE: You can stop active streams using the stream.close() method.
At the time of writing, Fauna’s document streaming is still an Early Access feature. Hence there are some limitations to using it, such as:
data field.In this article, we learned about Fauna’s document streaming capabilities and how easy it is to integrate Fauna’s document streaming into a Python application.
You can learn more about Fauna document streaming from the official documentation. If you have any questions, don't hesitate to contact me on Twitter: @LordGhostX.
37