
25
MongoDB aggregations are easy
Building aggregation pipelines sometimes just seems so hard, especially when you're working with NoSQL database such as MongoDB, since there is no defined schema, and there are just so many nested fields
Well in this article i'm not going to go deep into what aggregation query is, since i think MongoDB Docs explained this perfectly, but instead i will go through a kind of seeming-complex aggregation query, which is you probably going to face if you're currently with MongoDB and i will use this example here to just show you how aggregation pipelines are just logically easy, and it's always depends on how you think while building it
Well for the sake of our example, let's consider that you have this silly
products collection which has these 2 documents:{
"_id": {
"$oid": "55c30ff62cfa09af198b465a"
},
"name": "Awesome Tshirt",
"currency": "usd",
"one_size": "xl",
"variants": [
{
"type": "color",
"base_sku": 132145,
"items": [
{
"color": "Grey Melange",
"price": 80,
"sku": 1243252369
},
{
"color": "Bottle Green",
"price": 90,
"sku": 1243252368
},
{
"color": "Deep Charcoal Grey",
"price": 80,
"sku": 1243252376
},
{
"color": "White",
"price": 80,
"sku": 1243252363
},
{
"color": "Black",
"price": 80,
"sku": 1243252362
}
]
}
]
},
{
"_id": {
"$oid": "55c30ff62cfa09af198b465c"
},
"name": "Hacker Tshirt",
"currency": "usd",
"one_size": false,
"variants": [
{
"type": "color",
"base_sku": 132155,
"items": [
{
"color": "Black",
"price": 100,
"sku": 87987963
}
]
},
{
"type": "size",
"base_sku": 342434,
"items": [
{
"size": "sm",
"price": 100,
"sku": 97896796
},
{
"size": "xl",
"price": 100,
"sku": 43534534
},
{
"size": "xxl",
"price": 100,
"sku": 76576532
}
]
}
]
}and now our goal is to get the price of all grey T-shirts, so since as you can see that each product has it's price vary based on the variant itself, so we have to get both from variants items
item object. Yes in this collection its so silly that somehow you have to choose of either having black T-shirt or XXl tshirt, but not both :DThe very first step when you create a pipeline is to always
match your query, this to narrow down querying the whole collection to just a limited number of documents that match your criteriaYou always want to narrow down the number of documents you're searching within at the very beginning of the aggregation pipeline, this will lead to faster queries
So let's do this, first we want to use only the documents that has
color variant, and it has also grey color inside it's variant items. So this is how we're translating this:{
'$match': {
'variants': {
'$elemMatch': {
'type': 'color',
'items': {
'$elemMatch': {
'color': /grey/i
}
}
}
}
}
}$elemMatch operator matches documents that contain an array field with at least one element that matches all the specified query criteria.
We're using $elemMatch here to find a variant of
type color first, and then we're using it again to find an element of color that contains grey and its case insensitive - notice the regex /grey/i - So this was our first step, notice that only 1 item will be returned in this case that has ID
55c30ff62cfa09af198b465a, since it is the only one with variants of type color that has grey colorDocument
55c30ff62cfa09af198b465c it has variants of type color, but it has only black colorNow we still need to query a nested object that is inside variants (array) and also inside items (array), so its more like this
variants -> items -> {color, price}This seems complicated, and since we're dealing with array of objects here, what could make it easier? .. to just deal with this array as an object instead, so we can just leverage the dot notation syntax in Mongo
Well we can do that by just unwinding the array! simple as that, just flatten this array into objects by using
$unwind$unwind Deconstructs an array field from the input documents to output a document for each element
$unwind is so simple that the only required parameter to pass is
path which is the path of the array you want to flatten{
'$unwind': {
'path': '$variants'
}
}Notice the dollar sign before
variants, we have to prefix the field name with it so Mongo can interpret it, it just tells Mongo to inject the actual value of variantsNow by then we will have also 1 document still, since
variants array has only 1 element
Notice that
variants is now object instead of arrayNow what? we still need to query
variants.items elements which is the same case as variants before we unwind it. So i guess we will have to flatten variants.items too, so next stage will be{
'$unwind': {
'path': '$variants.items'
}
}Notice now that we can easily access
items with dot notation, since variants is an object and not an array anymore, now these are the the new documents returned after this stage
items is an object now with 1 document per items element which is exactly what we need, but did you notice something strange?Now we have documents with
items.color value that does not contains grey we have Black, White, and Bottle Green as well, why is that?Well that would be because our first
$match stage was only getting the documents that have items with grey color, having this does not necessary means that it will magically just filter other colors from items, this our job to do nowSo now we will need to get only the documents that has
variants.items.color with greyish color, looks like another $match query, right?{
'$match': {
'variants.type': 'color',
'variants.items.color': /grey/i
}It is so simple now, here we're just saying, out of the result of stage 3 we just want the documents which has variants of type
color and any item that has grey with case insensitive, that will return us these documents: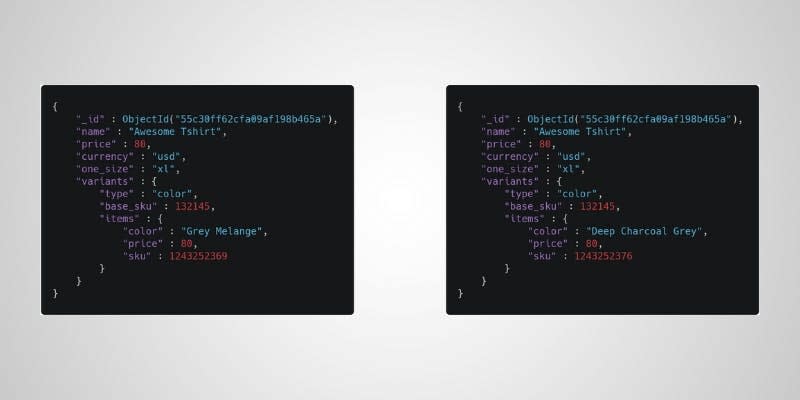
Now we have the documents, but we don't really care about all of these properties right? We only care about the color and the price
So since we're having a couple levels of nesting here
variants -> items and we only care about price and color properties, then we need to focus/project these properties only and ignore any other stuff we don't need$project Passes along the documents with the requested fields to the next stage in the pipeline.
$project is so simple also, you'll probably just need to know that:
_id is shown by default, unless you specify to hide itSo our stage implementation will be simple as
{
'_id': 0,
'color': '$variants.items.color',
'price': '$variants.items.price'
}Notice that we passed
'_id': 0 because we don't really care about the document ID - at least not in this example, normally you'll need it though - so we just hid itSo now this will be the final result

db.getCollection('products').aggregate([
{
'$match': {
'variants': {
'$elemMatch': {
'type': 'color',
'items': {
'$elemMatch': {
'color': new RegExp('grey', 'i')
}
}
}
}
}
},
{
'$unwind': {
'path': '$variants'
}
},
{
'$unwind': {
'path': '$variants.items'
}
},
{
'$match': {
'variants.type': 'color',
'variants.items.color': new RegExp('grey', 'i')
}
},
{
$project: {
'_id': 0,
'color': '$variants.items.color',
'price': '$variants.items.price'
}
}
])As you can see it's pretty straight forward, and it's quite easy and seems quite logical too, building aggregation pipelines stages is just like actually talking to rubber duck while coding, instead this time you're just talking to Mongo shell
This post was originally published on my blog blog.mrg.sh
25