
22
Web Scraping with CSS Selectors using Python
When web-scraping,
CSS selectors are one of the best friends. This tutorial will tell you what they're, their pros and cons, and why they matter from a web scraping perspective with Python examples to get you going.This blog post is not a complete CSS selectors reference, but a mini-guided tour of frequently used type of selectors and how to work them.
Intro
This blog post is about understanding
CSS selectors when doing web page web scraping, and what tools might be handy to use in addition to Python beautifulsoup, lxml libraries. Usage of
CSS selectors in different languages, frameworks, packages are not much different.Prerequisites
pip install lxml
pip install beautifulsoup4A basic familiarity with
bs4 library or whatever HTML parser package/framework you're using.This is needed if you want to train extract data from
CSS selectors on your own. If you don't want to do that, installing these libraries is not required.What is CSS selectors
CSS selectors are patterns used to select (match) the element(s) you want to SelectorGadget
Let's start with easy one, SelectorGadget extension. This extension allows to quickly grab
CSS selector(s) by clicking on desired element in your browser, and returns a CSS selector(s).SelectorGadget is an open-source tool that makes CSS selector generation and discovery on complicated sites a breeze.
Nokogiri and BeautifulSoup.jQuery selectors for dynamic sites.selenium or phantomjs testing.When using SelectorGadget it highlights element(s) in:


Pick CSS Selectors by Hand
Now is the time to think a little, just a little. Since SelectorGadget isn't a magical all around tool, sometimes it can't get the desired element. This happens when website HTML tree is not well structured, or if the site is rendered via JavaScript.
When it happens, I use Elements tab via Dev Tools (F12 on a keyboard) to locate and grab
CSS selector(s) or HTML elements by their:<input>
.class #id
[attribute]
Syntax: element_name
Type selectors matches elements by node name. In other words, it selects all elements of the given type within a HTML document.
soup.select('a') # returns all <a> elements
soup.select('span') # returns all <span> elements
soup.select('input') # returns all <input> elements
soup.select('script') # returns all <script> elementsSyntax: .class_name
Class selectors matches elements based on the contents of their class attribute. It's like calling a class function
PressF().when_playing_cod().soup.select('.mt-5') # returns all elements with current .selector
soup.select('.crayons-avatar__image') # returns all elements with current .selector
soup.select('.w3-btn') # returns all elements with current .selectorSyntax: #id_value
ID selectors matches an element based on the value of the elements
id attribute. In order for the element to be selected, its id attribute must match exactly the value given in the selector.soup.select('#eob_16') # returns all elements with current #selector
soup.select('#notifications-link') # returns all elements with current #selector
soup.select('#value_hover') # returns all elements with current #selectorSyntax: [attribute=attribute_value] or [attribute], more examples.
Attribute selectors matches elements based on the presence or value of a given attribute.
The only difference is that this selectors uses curly braces
[] instead of a dot (.) as class, or a hash (or octothorpe) symbol (#) as ID.soup.select('[jscontroller="K6HGfd"]') # returns all elements with current [selector]
soup.select('[data-ved="2ascASqwfaspoi_SA8"]') # returns all elements with current [selector]
# elements with an attribute name of data-id
soup.select('[data-id]') # returns all elements with current [selector]Syntax: element, element, element, ...
Selector list selects all the matching nodes (elements). In web scraping perspective this
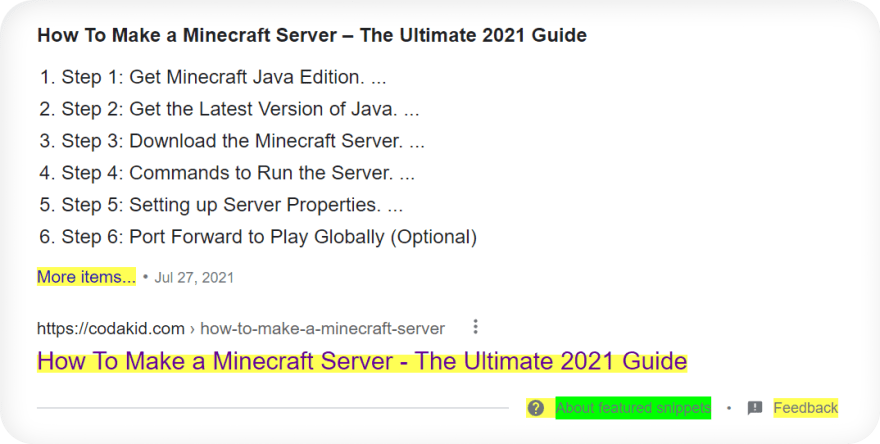
CSS selectors is great (in my opinion) to handle different HTML layouts because if one of the selectors is present it will grab all elements from an existing selector.As an example from Google Search (carousel results), the HTML layout will be different depending on country where the search is coming from.
When country of the search is not United States:
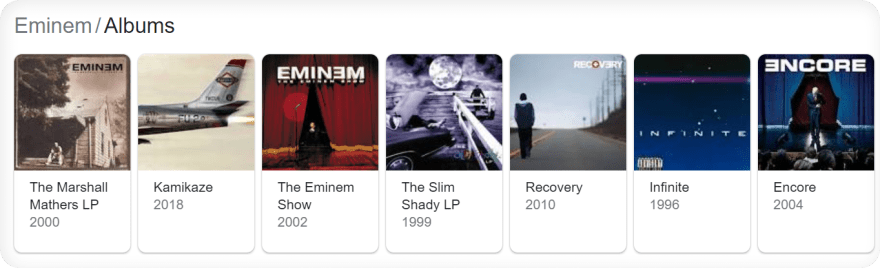
When country of the search is set to United States:
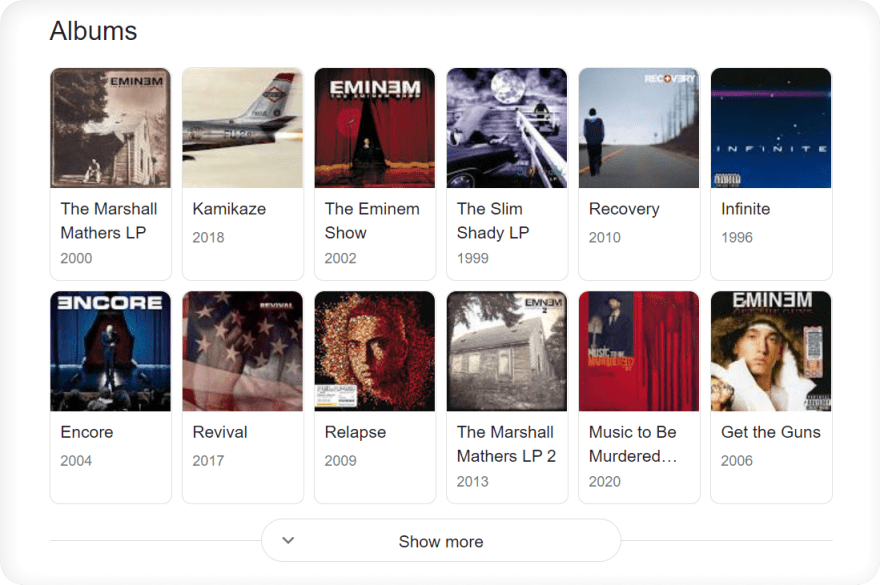
Following examples translates to this code snippet (handles both HTML layouts):
# will return all elements either by one of these selectors
soup.select('#kp-wp-tab-Albums .PZPZlf, .keP9hb')Syntax: selector1 selector2
Descendant combinator represented by a single space (
soup.select('.NQyKp .REySof') # dives insie .selector -> dives again to other .selector and grabs it
soup.select('div cite.iUh30') # dives inside div -> dives inside cite.selector and grabs it
soup.select('span#21Xy a.XZx2') # dives inside span#id -> dives insize a.selector and grabs itOther Useful
CSS Selectors:nth-child(n): Selects every n element that is the second child of its parent.:nth-of-type(n): Selects every n element that is the second n element of its parent.a:has(img): Selects every element <a> element that has an <img> element.Additional useful
CSS selectors you can find on W3C Level 4 Selectors, W3Schools CSS Selectors Reference, and MDN documentation.Test CSS Selectors
To test if the selector extracts correct data you can:
Place those
CSS selector(s) in the SelectorGadget window and see what elements being selected:
$$(".DKV0Md")Which is equivalent to
document.querySelectorAll(".selector") method (according to Chrome Developers website):document.querySelectorAll(".DKV0Md")Output from the DevTools Console for both methods are the same:

Cons of CSS Selector
Betting only classes might be not a good idea since they could probably change.
A "better" way (in terms of
CSS selectors) would be to use selectors such as attribute selectors (mentioned above), they are likely to change less frequently. See attribute selectors examples on the screenshot below (HTML from Google Organic results):
Many modern websites use autogenerated
CSS selectors for every change that is being made to certain style component, which means that rely exclusively on them is not a good idea. But again, it will depend on how often do they really change.The biggest problem that might appear is that when code will be executing it will blow up with an error, and maintainer of the code should manually change
CSS selector(s) to make the code running properly. Seems like not a big deal, which is true, but it might be annoying if selectors are changing frequently.Code Examples
This section will show a couple of actual examples from different websites to get you familiarize a bit more.
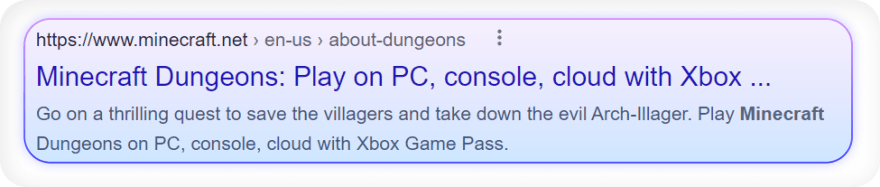
Test
CSS container selector: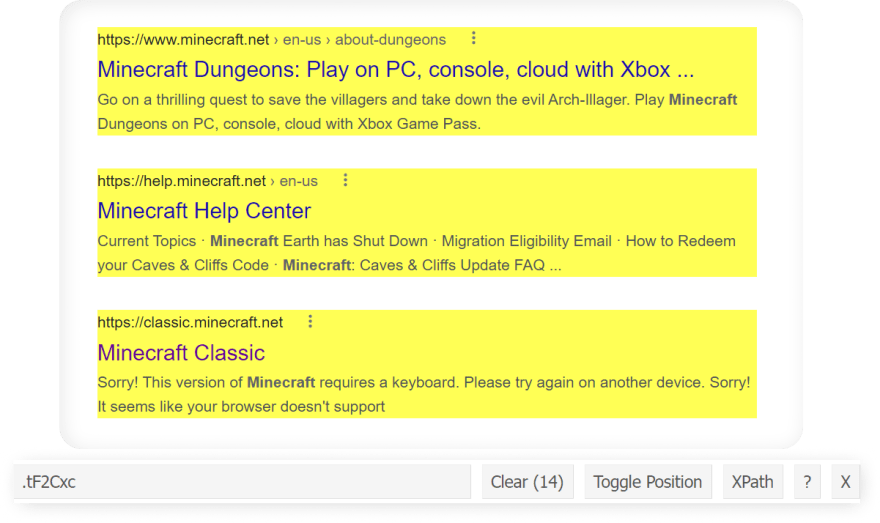
Code:
import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
html = requests.get("https://www.google.com/search?q=minecraft", headers=headers)
soup = BeautifulSoup(html.text, "lxml")
for result in soup.select(".tF2Cxc"):
title = result.select_one(".DKV0Md").text
link = result.select_one(".yuRUbf a")["href"]
displayed_link = result.select_one(".lEBKkf span").text
snippet = result.select_one(".lEBKkf span").text
print(f"{title}\n{link}\n{displayed_link}\n{snippet}\n")
# part of the output
'''
Log in | Minecraft
https://minecraft.net/login
https://minecraft.net › login
Still have a Mojang account? Log in here: Email. Password. Forgot your password? Login. Mojang © 2009-2021. "Minecraft" is a trademark of Mojang AB.
What is Minecraft? | Minecraft
https://www.minecraft.net/en-us/about-minecraft
https://www.minecraft.net › en-us › about-minecraft
Prepare for an adventure of limitless possibilities as you build, mine, battle mobs, and explore the ever-changing Minecraft landscape.
'''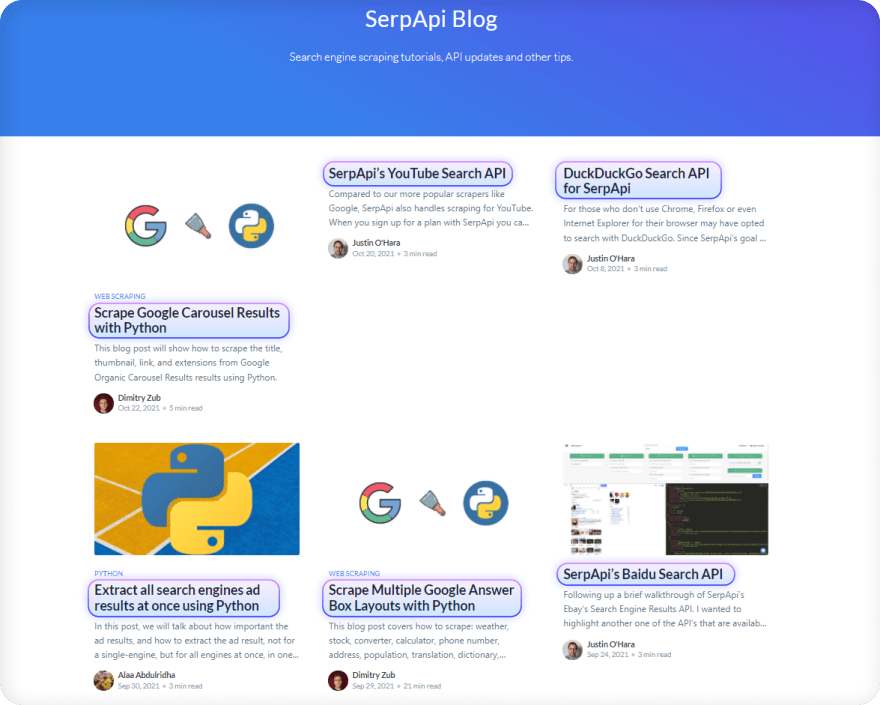
Testing
.post-card-title CSS selector in Devtools Console:$$(".post-card-title")
(7) [h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title, h2.post-card-title]
0: h2.post-card-title
1: h2.post-card-title
2: h2.post-card-title
3: h2.post-card-title
4: h2.post-card-title
5: h2.post-card-title
6: h2.post-card-title
length: 7
[[Prototype]]: Array(0)Code:
import requests, lxml
from bs4 import BeautifulSoup
html = requests.get("https://serpapi.com/blog/")
soup = BeautifulSoup(html.text, "lxml")
for title in soup.select(".post-card-title"):
print(title.text)
'''
Scrape Google Carousel Results with Python
SerpApi’s YouTube Search API
DuckDuckGo Search API for SerpApi
Extract all search engines ad results at once using Python
Scrape Multiple Google Answer Box Layouts with Python
SerpApi’s Baidu Search API
How to reduce the chance of being blocked while web scraping search engines
'''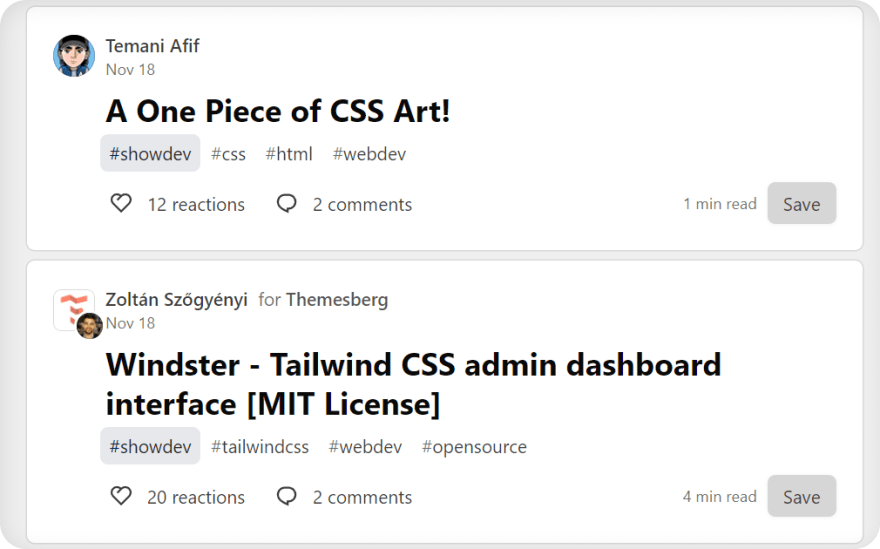
Test
CSS selector with either SelectorGadget or DevTools Console:
Code:
import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
}
html = requests.get("https://dev.to/", headers=headers)
soup = BeautifulSoup(html.text, "lxml")
for result in soup.select(".crayons-story__title"):
title = result.text.strip()
link = f'https://dev.to{result.a["href"].strip()}'
print(title, link, sep="\n")
# part of the output:
'''
How to Create and Publish a React Component Library
https://dev.to/alexeagleson/how-to-create-and-publish-a-react-component-library-2oe
A One Piece of CSS Art!
https://dev.to/afif/a-one-piece-of-css-art-225l
Windster - Tailwind CSS admin dashboard interface [MIT License]
https://dev.to/themesberg/windster-tailwind-css-admin-dashboard-interface-mit-license-3lb6
'''Links
Outro
In the further blog post, I'll cover XPath thing.
CSS selectors are pretty easy and straightforward to understand, just a matter of practice and trial and error (programming in a nutshell 💻)If you have anything to share, any questions, suggestions, or something that isn't working correctly, feel free to drop a comment in the comment section or reach out via Twitter at @dimitryzub, or @serp_api.
Yours,
Dimitry, and the rest of SerpApi Team.
Dimitry, and the rest of SerpApi Team.
22