
22
Relational data models
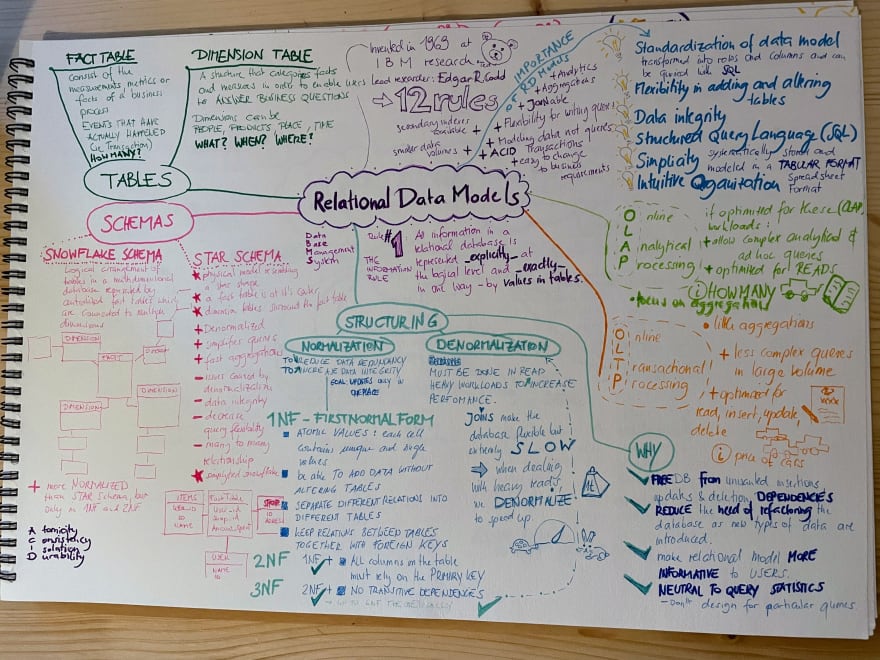
The relational data model was invented in 1969 at the IBM research department, with the lead researcher Edgar R. Codd. They created the 12 rules (13) to manifest the requirements for a data management system.
Rule 1: The information rule:
All information in a relational data base is represented explicitly at the logical level and in exactly one way – by values in tables.
Relational data models are important as they help us with
- standardisation of data models
- flexibility in adding and altering tables
- data integrity
- structured query language can be used
- simplicity - the tabular format
- intuitive organisation - spreadsheets
- small data volumes
- secondary indices needed
- Analytics needed
- Aggregations needed
- ACID transactions needed
- Flexibility for writing queries: In relational data models we are modelling data and not queries.
- easy to change, when business requirements change
- free database from unwanted insertions, updates and deletion dependencies
- reduce the need of refactoring the database as new types of data are introduced
- make the data more informative for users
- neutral to quer statistics. We don't want to design for particular queries
Normalisation is needed to reduce data redundancy and to increase data integrity. The overall goal here is to have updates only in one place.
- Atomic values: each cell contains unique and single values
- Be able to add data without altering tables
- Separate different relations into different tables
- Keep relations between tables together with foreign keys
- 1NF is reached
- All columns in a table rely on the primary key
- 2NF is reached
- No transitive dependencies
There are up to 6 normal forms. But most of the time we will need only up to 3.
When everything is normalised, we need Joins to gather the data. The more Joins you need, the slower the query will be. Denormalisation must be done to increase performance.
Consists of the measurements, metrics of facts of business process. EVENTS THAT HAVE ACTUALLY HAPPENED - like a transaction
A structure that categorises facts and measures in order to enable users to answer business questions.
Dimensions can be for example people, products, place or time.
- a physical model resembling a star shape
- a fact table is at its center, surrounded by dimension tables
- the simplified version of the snowflake scheme
denormalised | simplifies queries | fast aggregations
downsides of denormalisation | data integrity | decrease query flexibility | many to many relationship |
logical arrangement of tables in a multidimensional database represented by centralised fact tables with are connected to multiple dimension.
In the 1NF and 2NF it is more normalised than the STAR Schema
To have all the above information in one view, I made a sketchnote.
If you need a higher resolution please use this page
22