
38
🌎🌍🌏 Yugabyte cross-continent deployment 🚀
A distributed database can be deployed across continents. Of course, this introduces some latency in hundred of milliseconds, but it can be acceptable when the goal is to remain available in case of a region outage. Here is a short demo. I've setup a RF=3 cluster (3-way redundancy) with 3 nodes across Europe, America and Asia:
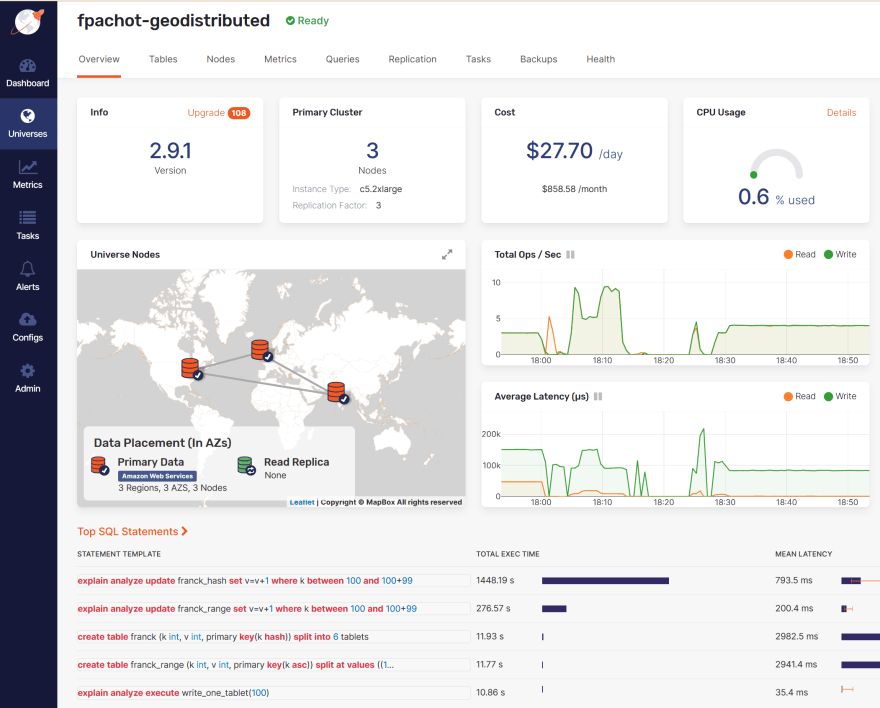
This is the view from out DBaaS platform which provides an easy GUI for the Open Source distributed SQL database. The 3 regions are in AWS: eu-west-1 is Dublin (Ireland), us-east-2 is Ohio (US), ap-south-1b is Mumbai (India) and you can see that I've flagged only eu-west-1 as "Preferred" leader zone:

This is the view from out DBaaS platform which provides an easy GUI for the Open Source distributed SQL database. The 3 regions are in AWS: eu-west-1 is Dublin (Ireland), us-east-2 is Ohio (US), ap-south-1b is Mumbai (India) and you can see that I've flagged only eu-west-1 as "Preferred" leader zone:
This sets an affinity rule to keep all raft group leaders in this region. Tables are distributed to tablets, which have their own raft consensus group, with one leader and two followers (when RF=3). The leader and at least one of the follower are always consistent, so that the RF=3 cluster can continue with one node down. You can be connected to any node, but writing and reading is done on the leader. The load is distributed by distributing the leaders over the nodes. When the nodes are within the same availability zone, the latency is low and you can distribute the leaders. However, the database cannot be available over a region failure. This is rare, but has already happened in all cloud providers. To be resilient to this, you can deploy the cluster to other regions (and even other cloud providers). Then, you will define the placement across the cluster to reduce the latency.
In this situation, you probably have multiple nodes per region, but to keep this demo simple I have only one:

I live in Switzerland, I'll connect to the node in Europe and I have defined the preferred leader placement there. Let's see the implication on read and write latency.
I'll create two tables. One with HASH sharding so that a range scan will read from 6 tablets. And one with RANGE sharding to query from one table only:
drop table franck_hash;
drop table franck_range;
create table franck_hash (k int, v int, primary key(k hash)) split into 6 tablets;
create table franck_range (k int, v int, primary key(k asc)) split at values ((100),(200),(300),(400),(500));
insert into franck_hash select generate_series(100,999),1;
insert into franck_range select generate_series(100,999),1;The placement rule is visible in "affinitized leaders" and the list of tablets show all leaders on the same node (172.159.25.209):

Now I'll read (SELECT) and write (UPDATE) 100 rows, and look at the elapsed time in milliseconds. I read a range on the primary key, so there's no cross-shard operations.
\c postgres://yugabyte@eu-west-1.compute.amazonaws.com:5433/yugabyte
psql (15devel, server 11.2-YB-2.9.1.0-b0)
yugabyte=# -- read from one tablet:
yugabyte=# explain analyze select count(*),min(k),max(k)
from franck_range
where k between 100 and 100+99;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=4.12..4.13 rows=1 width=16) (actual time=0.768..0.768 rows=1 loops=1)
-> Index Scan using franck_range_pkey on franck_range (cost=0.00..4.12 rows=1 width=4) (actual time=0.706..0.747 rows=100 loops=1)
Index Cond: ((k >= 100) AND (k <= 199))
Planning Time: 1.207 ms
Execution Time: 0.813 ms
(5 rows)
yugabyte=# \watch 0.001We read one tablet (the [100,200[ range) from the leader which is local: 0.813 millisecond. The multi-region setup has no consequence here.
yugabyte=# -- write in one tablet:
yugabyte=# explain analyze update franck_range
set v=v+1
where k between 100 and 100+99;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------
Update on franck_range (cost=0.00..4.12 rows=1 width=40) (actual time=1.378..1.378 rows=0 loops=1)
-> Index Scan using franck_range_pkey on franck_range (cost=0.00..4.12 rows=1 width=40) (actual time=0.946..0.999 rows=100 loops=1)
Index Cond: ((k >= 100) AND (k <= 199))
Planning Time: 0.063 ms
Execution Time: 127.107 ms
(5 rows)
yugabyte=# \watch 0.001The update reads from the leader and writes the new values to it. This happens in Europe and still low latency. You see that in the Update actual time: 1.378 millisecond. However, the leader sends the writes to synchronize the followers, and waits for one to acknowledge, in order to get the RF=3 quorum. The latency is probably lower for Ireland-Ohio than Ireland-Mumbai. Anyway, this is visible in the execution time: 127.107 milliseconds for the cross-atlantic roundtrip.
This is the price to pay to ensure a no data-loss failover in case of region failure. The latency to the nearest remote region adds to local writes.
In a distributed SQL database, many operations involve reading from multiple tablets: to check foreign keys, to read from secondary indexes, to check concurrent transaction status... I'm using the table sharded by hash to show a read from all tablets.
yugabyte=# -- read from all tablets:
yugabyte=# explain analyze select count(*),min(k),max(k)
from franck_hash
where k between 100 and 100+99;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------
Aggregate (cost=112.50..112.51 rows=1 width=16) (actual time=4.109..4.109 rows=1 loops=1)
-> Seq Scan on franck_hash (cost=0.00..105.00 rows=1000 width=4) (actual time=0.962..4.086 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.065 ms
Execution Time: 4.162 ms
(6 rows)
yugabyte=# \watch 0.001The latency is higher, but still in single digit millisecond because it reads from the tablet leaders which are in the preferred region. Once again, multi-region deployment has no consequences on reads thanks to the leader affinity.
yugabyte=# -- write in all tablets:
yugabyte=# explain analyze update franck_hash
set v=v+1
where k between 100 and 100+99;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=389.627..389.627 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=1.015..388.980 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.063 ms
Execution Time: 498.895 ms
(6 rows)
yugabyte=# \watch 0.001When writing, the cross-region latency, to get the quorum, adds-up for each tablet. This is nearly 0.5 seconds with my 6 tablets. This is where you need to think about the data model and application design to avoid too many cross-shard calls.
What matters is the closest region. I'll stop the node in Ohio to see the consequence on latency. I've run the multi-tablet write continuously with \watch:
Wed 01 Dec 2021 05:05:49 PM GMT (every 0.1s)
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=444.155..444.155 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=48.344..443.480 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.065 ms
Execution Time: 537.800 ms
(6 rows)
Wed 01 Dec 2021 05:05:49 PM GMT (every 0.1s)
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=441.697..441.697 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=46.783..441.126 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.065 ms
Execution Time: 520.722 ms
(6 rows)
Wed 01 Dec 2021 05:05:50 PM GMT (every 0.1s)
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=573.195..573.195 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=48.276..572.638 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.064 ms
Execution Time: 799.801 ms
(6 rows)
Wed 01 Dec 2021 05:05:51 PM GMT (every 0.1s)
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=694.457..694.457 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=89.387..693.864 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.062 ms
Execution Time: 860.702 ms
(6 rows)
Wed 01 Dec 2021 05:05:52 PM GMT (every 0.1s)
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=701.733..701.733 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=90.344..701.146 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.074 ms
Execution Time: 906.075 ms
(6 rows)
Wed 01 Dec 2021 05:05:53 PM GMT (every 0.1s)
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=810.418..810.418 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=89.464..809.829 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.063 ms
Execution Time: 932.995 ms
(6 rows)
Wed 01 Dec 2021 05:05:54 PM GMT (every 0.1s)
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=698.900..698.900 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=90.042..698.259 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.063 ms
Execution Time: 848.855 ms
(6 rows)There were no interruptions at all because this didn't even require a raft leader election - all leaders are still on the node in Ireland. But the latency has increased because now the quorum has to wait for Mumbai with a higher latency.
For the next test, I've re-started the node in Ohio.
By connecting to the same region that was defined for leader affinity, I reduced the latency at maximum. Let's see what happens if I have users connecting to another node. Here, I'll run the same as at the beginning (read and write on one and multiple tablets). But connected to the node in US.
\c postgres://yugabyte@us-east-2.compute.amazonaws.com:5433/yugabyte
psql (15devel, server 11.2-YB-2.9.1.0-b0)
yugabyte=# -- read from one tablet:
yugabyte=# explain analyze select count(*),min(k),max(k) from franck_range where k between 100 and 100+99;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=4.12..4.13 rows=1 width=16) (actual time=79.167..79.168 rows=1 loops=1)
-> Index Scan using franck_range_pkey on franck_range (cost=0.00..4.12 rows=1 width=4) (actual time=79.115..79.148 rows=100 loops=1)
Index Cond: ((k >= 100) AND (k <= 199))
Planning Time: 0.063 ms
Execution Time: 79.216 ms
(5 rows)
yugabyte=# -- write in one tablet:
yugabyte=# explain analyze update franck_range set v=v+1 where k between 100 and 100+99;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Update on franck_range (cost=0.00..4.12 rows=1 width=40) (actual time=79.463..79.463 rows=0 loops=1)
-> Index Scan using franck_range_pkey on franck_range (cost=0.00..4.12 rows=1 width=40) (actual time=79.080..79.127 rows=100 loops=1)
Index Cond: ((k >= 100) AND (k <= 199))
Planning Time: 0.064 ms
Execution Time: 310.338 ms
(5 rows)
yugabyte=# -- read from all tablets:
yugabyte=# explain analyze select count(*),min(k),max(k) from franck_hash where k between 100 and 100+99;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=112.50..112.51 rows=1 width=16) (actual time=473.667..473.667 rows=1 loops=1)
-> Seq Scan on franck_hash (cost=0.00..105.00 rows=1000 width=4) (actual time=79.107..473.640 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.066 ms
Execution Time: 473.724 ms
(6 rows)
yugabyte=# -- write in all tablets:
yugabyte=# explain analyze update franck_hash set v=v+1 where k between 100 and 100+99;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=1106.744..1106.744 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=79.298..1106.190 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.079 ms
Execution Time: 1264.824 ms
(6 rows)Reading has to go to the leader, which is in Ireland. This is 79.216 millisecond for the single tablet, and 473.724 milliseconds for the multiple tablets. There's no magic, if the user is in US, she has either to connect to the node in Ohio, and get this latency in the SQL query, or to connect to the node in Ireland, with fast SQL query, but the same latency to get back to the user. When this is a problem, we can allow reading from the follower, which is local, with
yb_read_from_followers = on. This looks like eventual consistency but it is not. Eventually consistent database have unpredictable staleness: usually low but large in case of network partition. With YugabyteDB, we can define the maximum staleness with yb_follower_read_staleness_ms allowed.Finally, what happens in the preferred leader region fails? Within 3 seconds, new leaders will be elected among the followers. There's no affinity rule, so this is balanced to the two remaining nodes:

The database is still functioning because and RF=3 cluster allows for one node down. I'll run the worst case, the multi-tablet write:
yugabyte=# explain analyze
update franck_hash set v=v+1
where k between 100 and 100+99;
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Update on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=2023.501..2023.502 rows=0 loops=1)
-> Seq Scan on franck_hash (cost=0.00..107.50 rows=1000 width=40) (actual time=194.785..2022.931 rows=100 loops=1)
Filter: ((k >= 100) AND (k <= 199))
Rows Removed by Filter: 800
Planning Time: 0.062 ms
Execution Time: 2220.721 ms
(6 rows)With leaders in Ohio and Mumbai, and transaction writing to multiple tablets, the service is still available but with high latency. This is the worst case, but with no data loss. I used 3 nodes only in 3 distant regions for the demo. In real deployment, you will ensure that you have multiple nodes in region availability zone, and closer regions.
I restart the node in Europe:

Automatically, the tablet peers in this region are elected as leaders, because it is the preferred region:

YugabyteDB sharding is fully automated. Once the placement rules defined, I used the administration console only to stop and start nodes. All failover and load balancing is automated by the nodes communicating though heartbeats.
The master server also moved back to eu-west-a1 and, as it sends regular heartbeats to the tablet servers, I can check the round-trip latency:

Now it is clear that eu-west-1a will Ohio quorum before Mumbai, as we have seen in the previous tests: 77.98 millisecond roundtrip and 120.39 millisecond. When you setup a cluster with a preferred region, it is a good idea to check this. You can also check from cloudping And if you want to reproduce what I did here, here are the statements I've run:
drop table franck_hash;
drop table franck_range;
-- create tables
create table franck_hash (k int, v int, primary key(k hash)) split into 6 tablets;
create table franck_range (k int, v int, primary key(k asc)) split at values ((100),(200),(300),(400),(500));
-- insert rows
insert into franck_hash select generate_series(100,999),1;
insert into franck_range select generate_series(100,999),1;
-- list the nodes
select * from yb_servers();
-- read from one tablet:
explain analyze select count(*),min(k),max(k) from franck_range where k between 100 and 100+99;
-- write in one tablet:
explain analyze update franck_range set v=v+1 where k between 100 and 100+99;
-- read from all tablets:
explain analyze select count(*),min(k),max(k) from franck_hash where k between 100 and 100+99;
-- write in all tablets:
explain analyze update franck_hash set v=v+1 where k between 100 and 100+99;38