
16
Query PostgreSQL, or any 🐘-compatible like Amazon Redshift, from YugabyteDB 🚀 thanks to Postgres FDW
PostgreSQL can run many kind of workloads, but is also a great federation layer for other database engines, thanks to the Foreign Data Wrapper (FDW). The latest stable version 2.8 of YugabyteDB includes the Postgres FDW extension, thanks to Radek Gruchalski's contribution.
I'll show two examples. A first one reading from a PostgreSQL 10.6 DB, the open RNAcentral database. The credentials for the reader user are public and both PostgreSQL and YugabyteDB are open-source and free. And a second example from Amazon Redshift, which is protocol-compatible with PostgreSQL.
I'm running this on YugabyteDB 2.9
Here is the definition of the RNAcentral database, connection ("server") and credentials ("mapping"):
CREATE EXTENSION postgres_fdw;
CREATE SERVER rna FOREIGN DATA WRAPPER postgres_fdw OPTIONS (
host 'hh-pgsql-public.ebi.ac.uk', port '5432',
dbname 'pfmegrnargs'
);
CREATE USER MAPPING FOR yugabyte SERVER rna OPTIONS (
user 'reader', password 'NWDMCE5xdipIjRrp'
);
CREATE SCHEMA rnacen;
-- I've generated this custom datatype definition from DBeaver:
CREATE TYPE rnacen.related_sequence_relationship AS ENUM ( 'target', 'matureProduct', 'precursor', 'target_protein', 'target_rna', 'isoform', 'mature_product', 'host_gene', 'ortholog', 'paralogue');
IMPORT FOREIGN SCHEMA rnacen FROM SERVER rna INTO rnacen OPTIONS (
import_collate 'false'
);A few notes:
I mention explicitly the 5432 port because the default from YugabyteDB is 5433
I've used
import_collate 'false'because we don't support yet the COLLATE clause (see #1127)I've created the user-defined data type as I got the
ERROR: type "rnacen.related_sequence_relationship" does not existI have imported the whole schema into a schema of the same name. Of course there are multiple options, see the PostgreSQL documentation for Foreign Data Wrapper.
I'll run the example query from the RNAcentral website:
yugabyte=# set SEARCH_PATH=rnacen;
SET
yugabyte=#
SELECT
upi, -- RNAcentral URS identifier
taxid, -- NCBI taxid
ac -- external accession
FROM xref
WHERE ac IN ('OTTHUMT00000106564.1', 'OTTHUMT00000416802.1')
;
upi | taxid | ac
---------------+-------+----------------------
URS00000B15DA | 9606 | OTTHUMT00000106564.1
URS00000A54A6 | 9606 | OTTHUMT00000416802.1
(2 rows)With EXPLAIN (VERBOSE) I can see the remote queries that are executed on the remote PostgreSQL server:
yugabyte=#
explain verbose
SELECT
upi, -- RNAcentral URS identifier
taxid, -- NCBI taxid
ac -- external accession
FROM xref
WHERE ac IN ('OTTHUMT00000106564.1', 'OTTHUMT00000416802.1')
;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Foreign Scan on rnacen.xref (cost=100.00..111.69 rows=2 width=594)
Output: upi, taxid, ac
Remote SQL: SELECT upi, ac, taxid FROM rnacen.xref WHERE ((ac = ANY ('{OTTHUMT00000106564.1,OTTHUMT00000416802.1}'::text[])))
(3 rows)It is important to verify that the predicates are pushed down, which is the case here. And it is interesting to verify that the query planner estimations, from the remote server statistics, are correct.
With EXPLAIN (ANALYZE) the query is executed to show the execution-time statistics:
yugabyte=#
explain (verbose, analyze)
SELECT
upi, -- RNAcentral URS identifier
taxid, -- NCBI taxid
ac -- external accession
FROM xref
WHERE ac IN ('OTTHUMT00000106564.1', 'OTTHUMT00000416802.1')
;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------
Foreign Scan on rnacen.xref (cost=100.00..111.69 rows=2 width=594) (actual time=57.085..57.087 rows=2 loops=1)
Output: upi, taxid, ac
Remote SQL: SELECT upi, ac, taxid FROM rnacen.xref WHERE ((ac = ANY ('{OTTHUMT00000106564.1,OTTHUMT00000416802.1}'::text[])))
Planning Time: 0.097 ms
Execution Time: 187.794 ms
(5 rows)Thanks to the predicate push-down the number of rows returned were only 2, this in 57 milliseconds. This is optimal. In case of doubt, it is easy to copy/paste the "Remote SQL" to explain it on the remote database (here in Dbeaver):
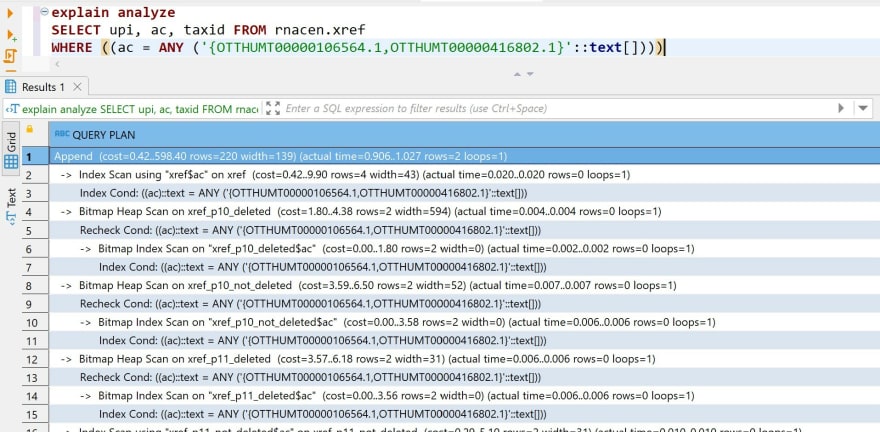
The PostgreSQL Foreign Data Wrapper has some limitations, so better check the execution plan before executing a complex query.
Having this available in YugabyteDB, which is mainly optimized for OLTP, opens many possibilities. You may have data on another PostgreSQL compatible database. You may want to transfer data from it to YugabyteDB, or query it from there. Here is an example where I query a datawarehouse on Amazon Redshift.
I have created a Redshift database from the AWS console:
The small sample schema is included:
I get the connection information from the jdbc string:

Even if this references the redshift protocol (jdbc:redshift://redshift-cluster.c1nydkstreff.eu-west-1.redshift.amazonaws.com:5439/dev), I can use the postgresql one, because AWS forked the PostgreSQL open-source code to build proprietary Redshift database:
- dbname: redshift-cluster.c1nydkstreff.eu-west-1.redshift.amazonaws.com
- host: dev
- port: 5439 (I've opened it in the security list for public access, and enabled "Publicly accessible" in the "Modify publicly accessible setting" action)
Here is how I declare this from my YugabyteDB database:
CREATE EXTENSION postgres_fdw;
CREATE SERVER redshift FOREIGN DATA WRAPPER postgres_fdw OPTIONS (
host 'redshift-cluster.c1nydkstreff.eu-west-1.redshift.amazonaws.com', port '5439',
dbname 'dev'
);
CREATE USER MAPPING FOR yugabyte SERVER redshift OPTIONS (
user 'awsuser', password 'Covid-19'
);
CREATE SCHEMA redshift_dev;
IMPORT FOREIGN SCHEMA public FROM SERVER redshift
INTO redshift_dev;I've run the following query in the AWS query editor:
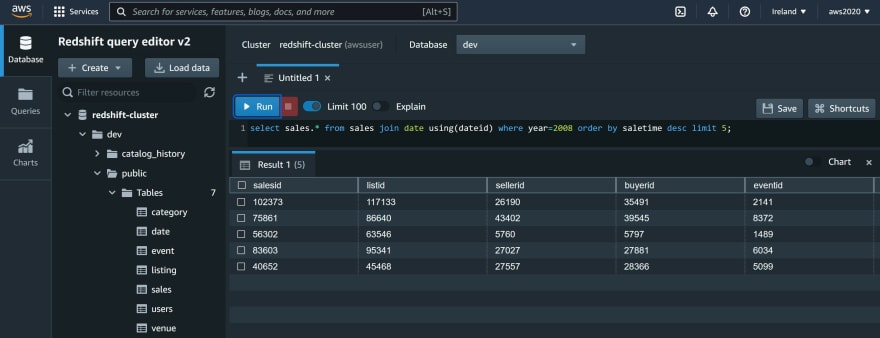
Here is the same query from by YugabyteDB database, though the Foreign Data Wrapper:
yugabyte=# set SEARCH_PATH=redshift_dev;
SET
yugabyte=# \timing on
Timing is on.
yugabyte=# select sales.* from sales join date using(dateid) where year=2008 order by saletime desc limit 5;
salesid | listid | sellerid | buyerid | eventid | dateid | qtysold | pricepaid | commission | saletime
--------------+--------+----------+---------+---------+--------+---------+-----------+------------+---------------------
102373 | 117133 | 26190 | 35491 | 2141 | 2191 | 4 | 1008.00 | 151.20 | 2008-12-31 12:58:19
75861 | 86640 | 43402 | 39545 | 8372 | 2191 | 2 | 372.00 | 55.80 | 2008-12-31 12:50:02
56302 | 63546 | 5760 | 5797 | 1489 | 2191 | 2 | 372.00 | 55.80 | 2008-12-31 12:08:14
83603 | 95341 | 27027 | 27881 | 6034 | 2191 | 1 | 288.00 | 43.20 | 2008-12-31 12:07:28
40652 | 45468 | 27557 | 28366 | 5099 | 2191 | 2 | 510.00 | 76.50 | 2008-12-31 12:05:38
(5 rows)The PostgreSQL Foreign Data Wrapper helps to connect from a PostgreSQL, or compatible database like YugabyteDB, to any database that is compatible with the PostgreSQL protocol. But, there's no distributed transactions for this. It creates a federated database, but this is not a distributed database. For consistent queries over a scale-out database, you need to run them on distributed databases like YugabyteDB, for OLTP, or Redshift, for datawarehouse.
16