
45
Partition and Clustering Key on Scylla DB
In the last 2 previous posts, we talked about Scylla DB. Today I will keep talking about the database, more specifically how works Primary Key on Scylla. We will see that the PK can be divided into two: Partition Key and Clustering Key. Let's get the difference between both and some differences in relation to a relational database.
Partition Key is responsible for data distribution across the nodes. It determines which node will store a given row. It can be one or more columns.
Clustering Key is responsible for sorting the rows within the partition. It can be zero or more columns.
Now that we know the difference about the Composites Keys, let's remember how we modeling our PK in Car table. In the cqlsh after selecting the Keyspace, use the command below.
DESCRIBE carThe result will be.
CREATE TABLE automobilies.car (
id uuid PRIMARY KEY,
brand text,
color text,
model text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'ALL'}
AND comment = ''
AND compaction = {'class': 'SizeTieredCompactionStrategy'}
AND compression = {'sstable_compression': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';How we can see, the unique PK that we have is id and could be calling of Simple Primary Key. If we do a select in the database, will retrieve only one car
cqlsh:automobilies> select * from car;
id | brand | color | model
--------------------------------------+-------+-------+-------
f714e8e5-b160-4341-807d-f4cd92b973a4 | VW | Red | GolfTo improve our test, let's include more cars in the table. The same model of car will have the same id.
cqlsh:automobilies> insert into car (id, brand, color, model) values (e0625c94-e9c2-11eb-9a03-0242ac130003, 'Ford', 'Red', 'Focus');
cqlsh:automobilies> insert into car (id, brand, color, model) values (fbd04f2c-511a-43c5-b588-9e29ebcb5d7a, 'VW', 'Nardo Grey', 'Passat');And now the select clause result in
id | brand | color | model
--------------------------------------+-------+------------+--------
fbd04f2c-511a-43c5-b588-9e29ebcb5d7a | VW | Nardo Grey | Passat
e0625c94-e9c2-11eb-9a03-0242ac130003 | Ford | Red | Focus
f714e8e5-b160-4341-807d-f4cd92b973a4 | VW | Red | GolfIf we want to find just a Golf car, we can query by id
cqlsh:automobilies> select * from car where id = f714e8e5-b160-4341-807d-f4cd92b973a4;
id | brand | color | model
-------------------------------------------+-------+-------+-------
f714e8e5-b160-4341-807d-f4cd92b973a4 | VW | Red | Golf
(1 rows)But what happening if we want to query by id and color? Well, maybe just need to add the and in the query and choose color, right?
cqlsh:automobilies> select * from car where id = f714e8e5-b160-4341-807d-f4cd92b973a4 and color = 'Red';
InvalidRequest: Error from server: code=2200 [Invalid query] message="Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING"Like we can see, when add color, we get an error, but why?
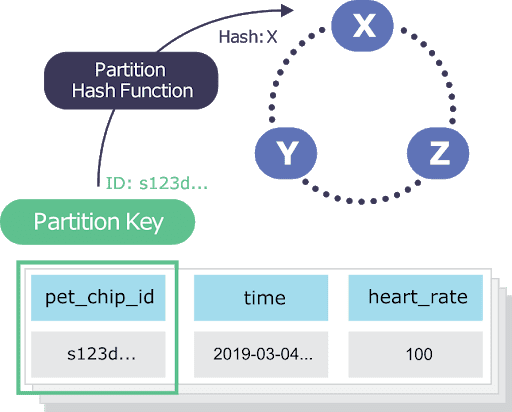
To answer this question, we need to understand how Scylla saves data (I will use an example with another domain).

In the image above, we see that Scylla uses a PK to divide the partitions. When we use just id for query, Scylla knows exactly which node contains the data by hashing the ID (which is the partition key) and that is why we got results in the first query. In the second query, when we tried to filter for color, wasn't possible, because we not defined color as Clustering Key or as Partition Key. We would still know on which partition the data exists because we have the partition key, but we would have to do a linear scan of the entire data on that partition to find the specific row we are looking for (using ALLOW FILTERING), but performing this query would be inefficient and possibly very slow. To use ALLOW FILTERING is like this
cqlsh:automobilies> select * from car where id = f714e8e5-b160-4341-807d-f4cd92b973a4 and color = 'Red' ALLOW FILTERING;
id | brand | color | model
-------------------------------------------+-------+-------+-------
f714e8e5-b160-4341-807d-f4cd92b973a4 | VW | Red | Golf
(1 rows)
cqlsh:automobilies> select * from car where id = f714e8e5-b160-4341-807d-f4cd92b973a4 and color = 'Green' ALLOW FILTERING;
--------MORE---
(0 rows)How we saw, this it's not good, so let's improve our data modeling.
We should know for which attributes we will want to query to define our keys. How we want a query for color and id, both will be our Pk, being id a Partition Key and color a Clustering Key.
cqlsh:automobilies> CREATE TABLE car (id uuid, brand text, color text, model text, PRIMARY KEY (id, color));
cqlsh:automobilies> DESCRIBE car;
CREATE TABLE automobilies.car (
id uuid,
color text,
brand text,
model text,
PRIMARY KEY (id, color)
) WITH CLUSTERING ORDER BY (color ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'ALL'}
AND comment = ''
AND compaction = {'class': 'SizeTieredCompactionStrategy'}
AND compression = {'sstable_compression': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99.0PERCENTILE';Now that we have a Clustering Key we can insert some cars with the same id, but different colors and Scylla will sort for us.
cqlsh:automobilies> insert into car (id, brand, color, model) values (f714e8e5-b160-4341-807d-f4cd92b973a4, 'VW', 'Red', 'Golf');
cqlsh:automobilies> insert into car (id, brand, color, model) values (e0625c94-e9c2-11eb-9a03-0242ac130003, 'Ford', 'Red', 'Focus');
cqlsh:automobilies> insert into car (id, brand, color, model) values (fbd04f2c-511a-43c5-b588-9e29ebcb5d7a, 'VW', 'Red', 'Passat');
cqlsh:automobilies> insert into car (id, brand, color, model) values (fbd04f2c-511a-43c5-b588-9e29ebcb5d7a, 'VW', 'Green', 'Passat');
cqlsh:automobilies> insert into car (id, brand, color, model) values (f714e8e5-b160-4341-807d-f4cd92b973a4, 'VW', 'Green', 'Golf');Our partition will stay like this

Thus we have the partitions divided for id and rows of cars sorted by color
cqlsh:automobilies> select * from car;
id | color | brand | model
-------------------------------------------+-------+-------+--------
fbd04f2c-511a-43c5-b588-9e29ebcb5d7a | Green | VW | Passat
fbd04f2c-511a-43c5-b588-9e29ebcb5d7a | Red | VW | Passat
e0625c94-e9c2-11eb-9a03-0242ac130003 | Red | Ford | Focus
f714e8e5-b160-4341-807d-f4cd92b973a4 | Green | VW | Golf
f714e8e5-b160-4341-807d-f4cd92b973a4 | Red | VW | GolfAnd now we can query by id and color
cqlsh:automobilies> select * from car where id = fbd04f2c-511a-43c5-b588-9e29ebcb5d7a and color = 'Red';
id | color | brand | model
-------------------------------------------+-------+-------+--------
fbd04f2c-511a-43c5-b588-9e29ebcb5d7a | Red | VW | Passat
(1 rows)In general, we saw how we define our PK in Scylla, can being Partition Key and Clustering Key. We need first think about our queries and after to model our tables. There are many others rules for work with these PK's, but in a unique post is not possible to cover all subject matter. I recommend that you do the courses of https://university.scylladb.com/. Well, this is what I wanted to introduce in this post, I really hope that you like it. Doubts, critics, and suggestions, I will be a disposition.
45