
36
Scrape Google Local Place from Organic Search with Python
Contents: intro, why bother reading, what will be scraped, imports, process, code, links, outro.
This blog post is a continuation of Google's web scraping series. Here you'll see how to scrape Local Place Results from organic search results using Python with beautifulsoup, requests, lxml libraries. An alternative API solution will be shown.
Note: This blog post assumes that you know the basics understanding of web scraping using bs4, requests/regex/css selectors.
You can do:
- place analysis in the local area(s).
- compare analysis of the same place in different areas.
- analysis of user feedback (rating, reviews).
- compare one place to a competitor place in Google results, who appears on the page and try to understand why.
- create a dataset for analysis.

import requests, lxml
from bs4 import BeautifulSoup
from serpapi import GoogleSearchSelecting CSS selectors to extract container with all data, title, address, phone (if there), open hours, place options, website, directions link to Google Maps.
Extract phone numbers correctly
To extract phone numbers no matter what language and country is used, e.g. German, Japanese, French, Italian, Arabic, etc. I used regex which you can see in action on regex101.
It also could be done with xpath but beautifulsoup doesn't support xpath directly and using lxml.etree that supports xpath I didn't want either (Examples from Ian Hopkinson on GitHub). I found really difficult or impossible to make it work with CSS selectors, so regex was used instead.
Firstly, a GIF illustration for a bit of familiarization.
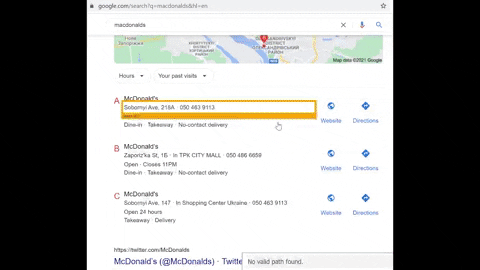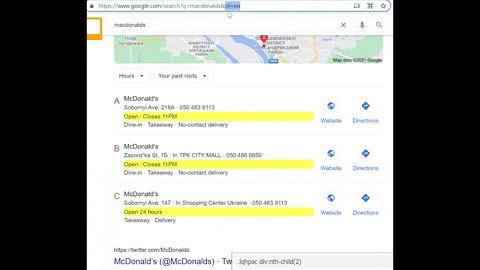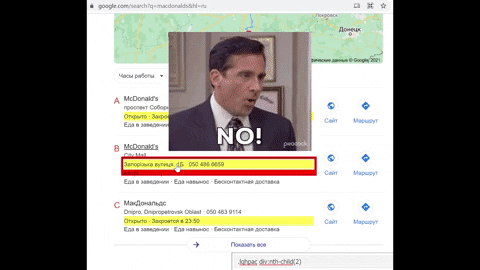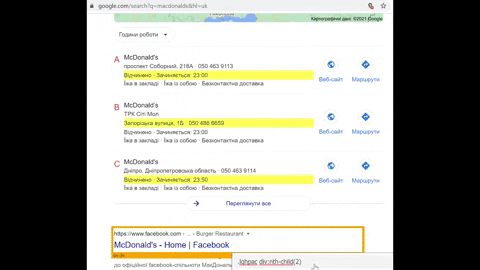
Secondly, it's because of this (French language/country was used):


Thirdly, now you see that sometimes <span> with a class lqhpac have 2 or 3 <div> elements inside it and only the phone numbers need to be extracted. That's why regular expression comes into play.
A quick note: this issue doesn't occur at all if you're using hl=en&gl=us and this step could be skipped if you don't need data other than English.
Solution
The solution is incredibly simple yet does what is supposed to:
- locates
·symbol that always appears. - creates a capture group for the phone numbers and use
.*which selects everything afterward. - the final regular expression will look like this:
· ?(.*)
The screenshot below shows what is being captured with regular expression. Notice how the phone numbers differ and are still being captured.
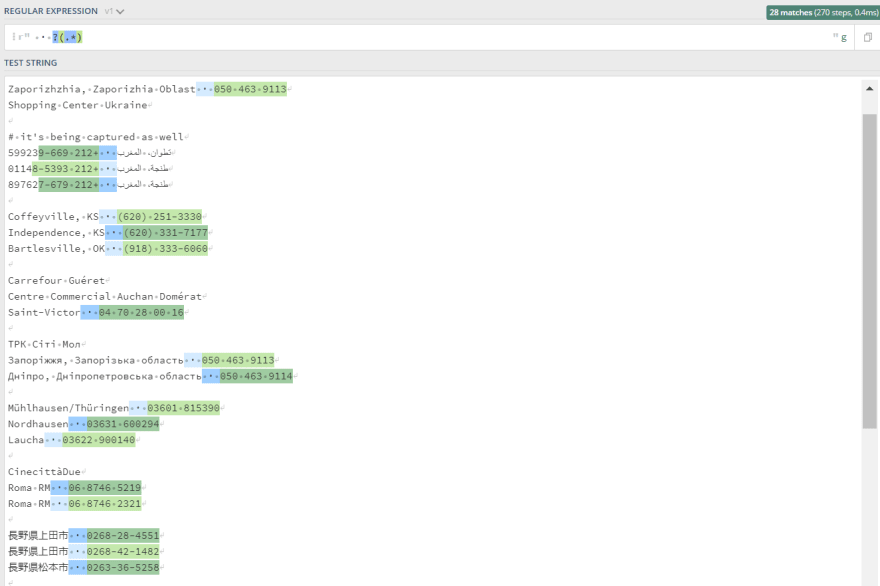
You can learn about regular expressions on regexone, can't recommend it enough, such a great place to learn regex.
import requests, lxml, re, json
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
# phone extracting works with different countries, languages
params = {
"q": "mcdonalds",
"gl": "jp",
"hl": "ja", # japanese
}
response = requests.get("https://www.google.com/search", headers=headers, params=params)
soup = BeautifulSoup(response.text, 'lxml')
local_results = []
for result in soup.select('.VkpGBb'):
title = result.select_one('.dbg0pd span').text
try:
website = result.select_one('.yYlJEf.L48Cpd')['href']
except:
website = None
try:
directions = f"https://www.google.com{result.select_one('.yYlJEf.VByer')['data-url']}"
except:
directions = None
address_not_fixed = result.select_one('.lqhpac div').text
# removes phone number from "address_not_fixed" variable
# https://regex101.com/r/cwLdY8/1
address = re.sub(r' · ?.*', '', address_not_fixed)
phone = ''.join(re.findall(r' · ?(.*)', address_not_fixed))
try:
hours = result.select_one('.dXnVAb').previous_element
except:
hours = None
try:
options = result.select_one('.dXnVAb').text.split('·')
except:
options = None
local_results.append({
'title': title,
'phone': phone,
'address': address,
'hours': hours,
'options': options,
'website': website,
'directions': directions,
})
print(json.dumps(local_results, indent=2, ensure_ascii=False))
------------------------------------------
'''
# Japanese results:
{
"title": "マクドナルド 上田バイパス店",
"phone": "0268-28-4551",
"address": "長野県上田市",
"hours": " ⋅ 営業開始: 6:00",
"options": [
"イートイン",
"店先受取可",
"宅配"
],
"website": "https://map.mcdonalds.co.jp/map/20515",
"directions": "https://www.google.com/maps/dir//%E3%80%92386-0001+%E9%95%B7%E9%87%8E%E7%9C%8C%E4%B8%8A%E7%94%B0%E5%B8%82%E4%B8%8A%E7%94%B0+%E5%AD%97%E9%A6%AC%E9%A3%BC%E5%85%8D%EF%BC%91%EF%BC%98%EF%BC%94%EF%BC%90%EF%BC%8D%EF%BC%91+%E3%83%9E%E3%82%AF%E3%83%89%E3%83%8A%E3%83%AB%E3%83%89+%E4%B8%8A%E7%94%B0%E3%83%90%E3%82%A4%E3%83%91%E3%82%B9%E5%BA%97/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x601dbd18e95fda63:0x6e7cae08b9fb4c6c?sa=X&hl=ja&gl=jp"
}
------------------------------------------
# Arabic results:
{
"title": "McDonald's",
"phone": "",
"address": "Bahía Blanca, Buenos Aires Province",
"hours": " ⋅ سوف يفتح في 7:00 ص",
"options": [
"الأكل داخل المكان",
"خدمة الطلب أثناء القيادة",
"التسليم بدون تلامس"
],
"website": "https://www.mcdonalds.com.ar/",
"directions": "https://www.google.com/maps/dir//McDonald's,+Brown+266,+B8000+Bah%C3%ADa+Blanca,+Provincia+de+Buenos+Aires/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x95edbcb37fd850d3:0x5223e03c35a5110d?sa=X&hl=ar&gl=ar"
}
------------------------------------------
# Arabic results №2 (hl=ar (Arabic), gl=dz (Algeria))
{
"title": "McDonald's",
"phone": "+212 669-599239",
"address": "تطوان، المغرب",
"hours": "مفتوح ⋅ سيتم إغلاقه في 10:00 م",
"options": [
"الأكل داخل المكان",
"خدمة الطلب أثناء القيادة",
"التسليم بدون تلامس"
],
"website": "http://www.mcdonalds.ma/",
"directions": "https://www.google.com/maps/dir//McDonald's%D8%8C+Avenue+9+Avril,+%D8%AA%D8%B7%D9%88%D8%A7%D9%86+93000%D8%8C+%D8%A7%D9%84%D9%85%D8%BA%D8%B1%D8%A8%E2%80%AD/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0xd0b430da777d3cd:0x31a4be8cb9167e69?sa=X&hl=ar&gl=dz"
}
------------------------------------------
# French results:
{
"title": "McDonald's",
"phone": "04 70 28 00 16",
"address": "Saint-Victor",
"hours": "Ouvert ⋅ Ferme à 22:30",
"options": [
"Repas sur place",
"Service de drive",
"Livraison"
],
"website": "http://www.restaurants.mcdonalds.fr/mcdonalds-saint-victor",
"directions": "https://www.google.com/maps/dir//McDonald's,+Zone+Industrielle+de+la+Loue,+03410+Saint-Victor/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x47f0a77a2fb7e253:0x7c68ab4798e1655a?sa=X&hl=fr&gl=fr"
}
------------------------------------------
# Russian results:
{
"title": "Макдоналдс",
"phone": "8 (495) 103-38-85",
"address": "Москва",
"hours": "Открыто ⋅ Закроется в 00:30",
"options": [
"Еда в заведении",
"Еда навынос",
"Бесконтактная доставка"
],
"website": "https://www.mcdonalds.ru/",
"directions": "https://www.google.com/maps/dir//%D0%9C%D0%B0%D0%BA%D0%B4%D0%BE%D0%BD%D0%B0%D0%BB%D0%B4%D1%81,+%D1%83%D0%BB.+%D0%9A%D0%B8%D0%B5%D0%B2%D1%81%D0%BA%D0%B0%D1%8F,+2,+%D0%9C%D0%BE%D1%81%D0%BA%D0%B2%D0%B0,+121059/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x46b54b0efab9de2f:0x2e3336864cc08e8f?sa=X&hl=ru&gl=ru"
}
------------------------------------------
# German results:
{
"title": "McDonald's",
"phone": "03622 900140",
"address": "Laucha",
"hours": "Geöffnet ⋅ Schließt um 00:00",
"options": [
"Speisen vor Ort",
"Drive-in",
"Kein Lieferdienst"
],
"website": "https://www.mcdonalds.com/de/de-de/restaurant-suche.html/l/laucha/gewerbestrasse-1/549&cid=listing_0549",
"directions": "https://www.google.com/maps/dir//McDonald's,+Gewerbestra%C3%9Fe+1,+99880+Laucha/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x47a480ee11b6e809:0x403e2aa4d3d85996?sa=X&hl=de&gl=de"
}
------------------------------------------
# English results:
{
"title": "McDonald's",
"phone": "(620) 251-3330",
"address": "Coffeyville, KS",
"hours": " ⋅ Opens 5AM",
"options": [
"Curbside pickup",
"Delivery"
],
"website": "https://www.mcdonalds.com/us/en-us/location/KS/COFFEYVILLE/302-W-11TH/4581.html?cid=RF:YXT:GMB::Clicks",
"directions": "https://www.google.com/maps/dir//McDonald's,+302+W+11th+St,+Coffeyville,+KS+67337/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x87b784f6803e4c81:0xf5af9c9c89f19918?sa=X&hl=en&gl=us"
}
'''Using Google Local Pack API
SerpApi is a paid API with a free plan.
I would say that the difference is that iterating over rich, structured JSON is better than coding everything from scratch, and you don't need to use regex to find specific data, it's already there ʕ•́ᴥ•̀ʔ
import json
from serpapi import GoogleSearch
params = {
"api_key": "YOUR_API_KEY",
"engine": "google",
"q": "mcdonalds",
"gl": "us",
"hl": "en"
}
search = GoogleSearch(params)
results = search.get_dict()
for result in results['local_results']['places']:
print(json.dumps(result, indent=2, ensure_ascii=False))
-------------------------
'''
# English result:
{
"position": 1,
"title": "McDonald's",
"place_id": "18096022638459706144",
"lsig": "AB86z5UHvsX5Pdo5ua4vplcxlXYG",
"place_id_search": "https://serpapi.com/search.json?device=desktop&engine=google&gl=us&google_domain=google.com&hl=en&lsig=AB86z5UHvsX5Pdo5ua4vplcxlXYG&ludocid=18096022638459706144&q=mcdonalds&tbm=lcl",
"rating": "A",
"links": {
"website": "https://www.mcdonalds.com/us/en-us/location/VA/RICHMOND/7527-STAPLES-MILL-RD/3735.html?cid=RF:YXT:GMB::Clicks",
"directions": "https://www.google.com/maps/dir//McDonald's,+7527+Staples+Mill+Rd,+Richmond,+VA+23228/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x89b115b9ff1b78cd:0xfb21fcb67cd15b20?sa=X&hl=en&gl=us"
},
"phone": "(804) 266-8600",
"address": "Richmond, VA",
"hours": "Closed ⋅ Opens 5:30AM",
"gps_coordinates": {
"latitude": 37.618504,
"longitude": -77.49884
}
}
-------------------------
# Arabic results:
{
"position": 1,
"title": "McDonald's",
"place_id": "2793317375272005807",
"lsig": "AB86z5XgEbNCVDhyL9L0Vp7aqSA4",
"place_id_search": "https://serpapi.com/search.json?device=desktop&engine=google&gl=us&google_domain=google.com&hl=ar&lsig=AB86z5XgEbNCVDhyL9L0Vp7aqSA4&ludocid=2793317375272005807&q=mcdonalds&tbm=lcl",
"rating": "A",
"links": {
"website": "https://www.mcdonalds.com/us/en-us/location/WA/SPOKANE/1617-NORTH-HAMILTON-STREET/36304.html?cid=RF:YXT:GMB::Clicks",
"directions": "https://www.google.com/maps/dir//McDonald's,+1617+N+Hamilton+St,+Spokane,+WA+99202/data=!4m6!4m5!1m1!4e2!1m2!1m1!1s0x549e18c208497f9b:0x26c3db5a6a03b0af?sa=X&hl=ar&gl=us"
},
"phone": "(509) 484-8641",
"address": "1617 N Hamilton St",
"hours": "مغلق ⋅ سوف يفتح في 6:00 ص",
"gps_coordinates": {
"latitude": 47.672504,
"longitude": -117.39688
}
}
'''If you have any questions or something isn't working correctly or you want to write something else, feel free to drop a comment in the comment section or via Twitter at @serp_api.
Yours,
Dimitry, and the rest of SerpApi Team.
36