
22
ampy 執行輸出中文的問題
如果你有使用 ampy 執行 MicroPython 程式, 可能會發現如果你的程式有輸出中文, 就會變成亂碼, 例如執行這個只有 print 的程式:
print('測試')執行結果如下:
>ampy -p com6 run test.py
������如果你將輸出結果轉向到檔案, 像是:
>ampy -p com6 run test.py > ttt.txt再用文字編輯器開啟這個文字檔, 你會發現可以正常看到輸出的文字:
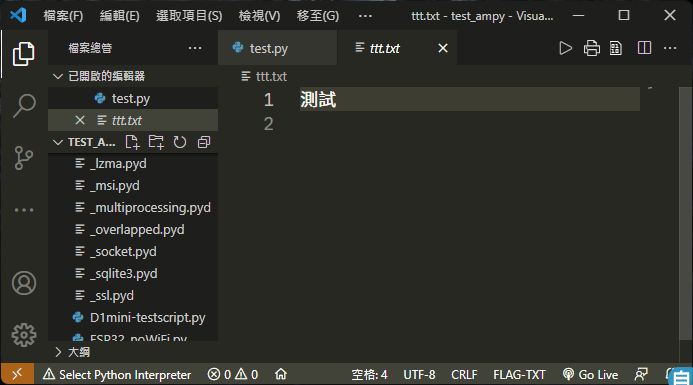
文字編碼也是 UTF-8 沒錯, 這表示程式的輸出是正確的, 只是可能原本單一中文字的多個位元組被切開成一個一個位元組後當成多個字元顯示, 所以變成無法正常顯示的 6 的字元了。
這個問題只會出現在 1.1.0 版的 ampy 上, 如果我們回頭去看原始碼, 會發現在 pyboard.py 中有一個函式如下:
def stdout_write_bytes(b):
b = b.replace(b"\x04", b"")
stdout.write(b)
stdout.flush()其中的參數 b 是一個 bytes 物件, 通常的長度只有 1, 就是從序列埠讀取 MicroPython 程式執行結果的下 1 個位元組, 而 0x04 是 MicroPython 通知結束的特殊數值。這裡為了讓程式執行結果可以經由 USB 傳輸線串流顯示到電腦端, 所以採取了每收到 1 個位元組就立刻清除緩衝區強迫輸出到螢幕上的方式。這個方式對於一般的英數字沒有什麼影響, 可是若是中文字, 在 UTF-8 的編碼下, 至少會有 2 個位元組, 上述作法會把多個位元組拆散, 視為多個字元顯示, 因而造成個別位元組都是無法正常顯示的字元。
要解決這個問題, 最簡單的方式就是把函式中清除緩衝區的哪一行去掉, 改成這樣:
def stdout_write_bytes(b):
b = b.replace(b"\x04", b"")
stdout.write(b)
# stdout.flush()讓位元組連續輸出, 不要硬去清除緩衝區, 系統就不會認為個別位元組是單一字元了。執行結果如下:
>ampy -p com6 run test.py
測試您可能會擔心把清除緩衝區的動作去除, 這樣會不會要累積一大堆輸出結果後才會在畫面上看到結果?那我們也可以這樣做, 依據 UTF-8 編碼的規則, 每收到一個完整的 UTF-8 編碼的字元就清除緩衝區強迫送出字元, 將同一函式改寫如下:
utf8Char = b""
counts = 3
def stdout_write_bytes(b):
global utf8Char, counts
for i in b:
curr = b'' + b
if curr==b'\x04': # end of output
return;
elif curr <= b'\x7f': # 1-byte UTF-8 char
utf8Char = curr
counts = 0
elif b'\xC0' <= curr <= b'\xDF': # 2-bytes UTF-8 char
utf8Char = curr
counts = 1
elif b'\xE0' <= curr <= b'\xEF': # 3-bytes UTF-8 char
utf8Char = curr
counts = 2
elif b'\xF0' <= curr <= b'\xF7': # 4-bytes UTF-8 char
utf8Char = curr
counts = 3
elif b'\x80' <= curr <= b'\xBF': # 1 byte in a UTF-8 char
utf8Char = utf8Char + curr
counts = counts - 1
if counts == 0: # 1 UTF-8 char readed
print(utf8Char.decode('UTF-8'), end="")
counts = 3 # reset count
utf8Char=b''這樣就可以使用 ampy 執行含有中文輸出的 MicroPython 程式了。
22