
41
Blog Page Accessibility Deep Dive
Accessibility Auditing My Portfolio Site - Part 5
Read Part 1 - The Audit, Part 2 - Quick Fixes, Part 3 - Dark Mode Toggle and Part 4 - Blog Preview Component.
This blog will focus on the full blog page on my portfolio site. There is a component displaying previews of all of my blog posts on my main page. Clicking on the "Blog" heading/button there will render a component displaying all of my blogs in their entirety. Similarly, when you click on the heading of one of the blog previews, only that blog will load. When I started writing this part of my accessibility audit series, there was a separate SingleBlog component for rendering one blog with almost the exact same structure and styling as the FullBlog component that rendered all of the blogs.
I'm fixing issues I discovered in part 1 of this series, while auditing, as well as issues I discovered while fixing my site for parts 2, 3, and 4. For good measure, I'm also investigating a few things I wanted to revisit the last time I rewrote this page. As I wrote this, the list of problems grew, some fixes solved problems for headings I hadn't gotten to yet, and I probably reordered the sections 5 times as I went. Because of the sprawling nature of this blog, I've mapped the problems to the headings with their fixes:
Refactor
When I originally wrote my site, because I wrote theonClickhandler that rendered a single blog differently than the rest of myonClickhandlers, I wrote two separate components, a SingleBlog and a FullBlog. I want to refactor these into one component because making updates in two files was tedious the last time I rewrote this page.Markdown or HTML?
The second thing I wanted to revisit - investigating whether a markdown parsing solution is better than an HTML parsing solution for displaying what the DEV API returns. While working on this, I found a security vulnerability!Sections, Articles, and Headings, Oh My
Based on the audit and things I've learned fixing other parts of my site, I want to make sure I only have one<h1>on a page, only return one<section>on my blog page, put each blog in an<article>, and edit my blogs so there are no skipped heading levels.Links on Links on Links
Based on reader feedback from this series, I want to add a link in each<article>to the blog post on DEV for sharing. The audit in part 1 returned errors about empty links in the blog headings from the HTML the DEV API returned, and I thought that was solved by switching to markdown. Turns out, they were merely replaced by "target source does not exist" errors.The CSS Mess
I had noticed my<ul>styling needed help during the audit, and wanted to revisit code block styling after the last time I rewrote this page. After switching to markdown, I'll need to revisit all my blog styling again.No to Reflow
From manual testing, I found I need to update my styling so my blog page is able to get to 400% zoom without causing reflow issues. I also found the page switches to scrolling horizontally in landscape on mobile and I want to prevent that behavior.Text Formatting
During the audit for part 1, I got warnings to make sure<br>tags are not being used for paragraph formatting and that any meaning conveyed by<em>and<strong>must be available to screen readers. At least one automatic tool had a recommendation to use more list elements, and multiple recommended I use<q>or<quoteblock>tags around quotes. Through retesting after switching to markdown, I noticed my<ol>elements were being styled like<ul>s, the links to headings were broken, and new issues had been created by the way I was trying to caption/source images on DEV.The Long Alt-Text
A couple automatic tools gave me errors about long alt-text. I also want to look into how often I'm using words like "gif" because it seems much more often than I would like.Skipping Around
As I've been testing things with a screen reader and keyboard for this blog series, I realized wanted to provide skip links as a means of bypassing blocks of content for my blog preview component and blog page.
The last time I rewrote this page, I noticed that my SingleBlog and FullBlog components were very similar. The only real difference was I passed a blog id to my SingleBlog component to display one blog and my FullBlog component displayed all the blogs by default.
I started in my main file, app.js, and the first thing I needed to update was my chooseComponent() function that all of my navigation buttons use to display one component on the page.
const chooseComponent = (component) => {
if (component.component === "SingleBlog") {
setSingle(true)
setSingleBlogID(component.id)
setSingleShow("FullBlog")
} else if (component === "FullBlog") {
setSingle(true)
setSingleBlogID(0)
setSingleShow(component)
} else {
setSingle(true)
setSingleShow(component)
}
}Then, I removed the SingleBlog component imports from this file and add id={singleBlogID} to my FullBlog component's props. setSingleBlogID(0) returns SingleBlogID to it's default state and allows me to write this check in my useEffect in my FullBlog component:
if (props.id !== 0) {
fetchSingleBlog(props.id)
} else {
fetchBlogs()
}In my blog preview component, the heading button's chooseComponent had to be updated to return "SingleBlog" as well as an id for this to work.
<button className="preview_button" onClick={() => chooseComponent({component: "SingleBlog", id: blog.id})}>{blog.title}</button>After moving my fetchSingleBlog call from the SingleBlog component to the FullBlog component, I'm ready to format what FullBlog returns. I ended up having to update the structure of what is saved in state slightly (e.g. res.data.data instead of res.data), but then it was easy enough to check for the length of state.blogs, and return one or all of the blogs based on that.
if (!state.isLoading && state.blogs !== null) {
let blogList
if (state.blogs.length > 1) {
blogList = state.blogs.map((blog) => {
let blogBody = parse(blog.body_html)
return (
<li key={blog.id} className="blog">
<h1>{blog.title}</h1>
{blogBody}
</li>
)
})
} else {
let blogBody = parse(state.blogs.body_html)
blogList =
<li key={state.blogs.id} className="blog">
<h1>{state.blogs.title}</h1>
{blogBody}
</li>
}
return (
<section aria-label="Full list of Abbey's blog posts" className="full-blog">
<ul>
{blogList}
</ul>
</section>
)
} else if (!state.isLoading && state.error) {
return (
<Error />
)
} else {
return (
<Loading />
)
}Now, all of the updates I'll be doing for this component for the rest of this blog only have to be done in one file.
I wanted to revisit this decision for a couple reasons. First, because of the short deadline I was on, I didn't really have time to look at the markdown parsing solutions available to me. I balked when I saw the reviews saying they could be buggy and usually used dangerouslySetInnerHTML. Second, when I was building it, I was getting fairly regular 429, too many requests, responses from the DEV API because I'm grabbing each blog by id to get the HTML. However, I'm not seeing those anymore.
The DEV API, still in beta, has not updated what it returns, so I take a moment to research React markdown parser options. I quickly discover the solution I've implemented, like most HTML parsing, is open to XSS attacks. I could look at an HTML sanitization package, but instead I'm going to change my lambdas and implement react-markdown.
My blog preview component and singleBlog lambda still work in this context, but I have to refactor my blogPosts lambda. Luckily, this is mostly just removing complexity and making sure the structure of the object returned to my component is the same.
const axios = require('axios')
const API_KEY = process.env.API_KEY
exports.handler = async function (event, context) {
let articles
try {
articles = await axios.get('https://dev.to/api/articles/me', {
headers: {
"Api-Key": API_KEY,
"Content-Type": 'application/json'
}
})
} catch (err) {
console.log(err)
return {
statusCode:err.statusCode || 500,
body: err.message,
headers: {
"Access-Control-Allow-Origin": "https://abbeyperini.dev",
"Access-Control-Allow-Methods": "GET"
}
}
}
return {
statusCode: 200,
body: JSON.stringify({
data: articles.data
}),
headers: {
"Access-Control-Allow-Origin": "https://abbeyperini.dev",
"Access-Control-Allow-Methods": "GET"
}
}
}Next, I update my FullBlog component to import react-markdown and pull the markdown instead of the HTML from what my lambdas return. The excellent news is this is pretty darn easy. I uninstalled html-react-parser and installed react-markdown and the remarkGfm plugin. Then, I put a markdown variable where I previously had a variable called blogBody set to a parsed HTML string. Next, I add a ReactMarkdown component that parses and renders my markdown string where I previously returned blogBody.
let markdown = state.blogs.body_markdown
blogList =
<li key={state.blogs.id} className="blog">
<h1>{state.blogs.title}</h1>
<ReactMarkdown children={markdown} remarkPlugins={[remarkGfm]}></ReactMarkdown>
</li>The bad news is I'll have to revisit all of my blog styling for a third time. Considering the majority of the rest of the blog is mostly about styling fixes, it definitely could have happened at a worse time.
Turns out the myth that having <section>s negates the need to avoid multiple <h1>s on a page persists because the HTML specs say that's true and the browsers never implemented it. First, I updated my main page with <h2>s around my section headings. Then I double check I'm not skipping around in heading hierarchy in any of the content of the sections. I ended up updating about 16 headings.
My landing page has the <h1> with the page title, but it's not rendered with the rest of the content. Adding a visually hidden <h1> page title is now part of this Github issue, which has quickly become its own accessibility project to come back to after this comprehensive audit. Miraculously, this all works without me needing to update any main page CSS.
Next, I make sure my blog pages have one <section> and the blogs are wrapped in <articles> instead of in a list.
Then, it is time to investigate how my blog titles need to be formatted when I write on DEV. I've set my blog and section titles to <h2>s on my site, so anything other than the title (or ridiculously long secondary titles I have a tendency add) will have to start at <h3> and not skip any heading levels. I've been careful about not skipping levels of headings since I last rewrote this page, but I've been starting at <h2>. At this point, I know I don't want to go any lower in hierarchy on DEV because of accessibility on their site, so I'm going to try a regex to replace the octothorps that make headings (e.g. #, ##, ###) in the markdown string.

Before writing a regex, I need to make sure my headings in my blogs are uniform. I open up dev tools on my site and look at the structure returned after the markdown parsing. Not only do I have a few places where heading levels are skipped, but also about half of my blogs don't have spacing between the octothorps and the heading text. Even though DEV's markdown parser recognizes them as headings, react-markdown does not. Luckily, it's not all of them, because I had noticed this problem when I started cross posting blogs from DEV to Hashnode. I ended up editing 13 blogs - making sure they all start at <h2> and no headings are skipped. I also removed headings from a couple places where I was using them to format captions.
Next, the regex solution - I think I only have as low as <h4>, but I add a replace for <h5> just in case. After a little trial and error, including having to reverse the order of the replaces so that everything doesn't end up being an <h6>, my heading replace function looks like this:
function replaceHeadings(markdown) {
let newHeadings
newHeadings = markdown.replace(/\s#{5}\s/g, "\n###### ")
newHeadings = newHeadings.replace(/\s#{4}\s/g, "\n##### ")
newHeadings = newHeadings.replace(/\s#{3}\s/g, "\n#### ")
newHeadings = newHeadings.replace(/\s#{2}\s/g, "\n### ")
return newHeadings
}All I have to do is pass it my markdown string where I format blogs to be returned for rendering, and bam, accessible headings:
blogList = state.blogs.map((blog) => {
let markdown = blog.body_markdown
let replaced = replaceHeadings(markdown)
return (
<article key={blog.id} className="blog">
<h2>{blog.title}</h2>
<ReactMarkdown children={replaced} remarkPlugins={[remarkGfm]}></ReactMarkdown>
</article>
)
})While refactoring, I saw that the DEV url is included in each blog object returned by the API. Now I just need to figure out how I want to display it. I settle on a share button. For now, I'll open the DEV link in a new tab, but I've added copying the link to the user's clipboard and a hover label saying "copied!" to this Github issue. For now, I've got a "Share" button under each blog heading.
<article key={blog.id} className="blog">
<h2>{blog.title}</h2>
<a href={blog.url} target="_blank" rel="noreferrer"><button className="preview_button">Share</button></a>
<ReactMarkdown children={replaced} remarkPlugins={[remarkGfm]}></ReactMarkdown>
</article>I thought switching to markdown solved the the empty heading link warnings, but retesting for the Text Formatting section showed they had merely been replaced by "target source does not exist" errors. On my live site, I can see that the heading links previously worked without a router by generating <a name="heading-title" href="#heading-title"></a>. (For the record, it is recommended that you add an "id" to the heading element or an anchor element that has content, rather than adding a name attribute to an empty anchor before the heading.) I find a google style guide with a way to add an anchor to headings using markdown, and get impressively close to a working regex solution before I realized I should test if it would even work with this markdown parser.
I passed a few types of markdown syntax to my ReactMarkdown component and they didn't work. Turns out react-markdown won't parse heading anchors. I read multiple issues, tried the recommended render functions and components, added a escapeHTML={false} prop and an anchor link around a heading myself, and every time the heading was unaffected, showed the link as part of the heading content, or disappeared. The answer might be installing a plugin, but installing one involves installing multiple, and I've still got quite a few fixes to go, so I've made a new Github issue to come back to later. Luckily, if users really want to use the table of contents, they have that share button to take them to DEV for now.
I was reminded by an error from the same retesting that I need to add my external link icon to my share buttons. All the other links in my blogs are opening in the same tab. I import my <ExternalLink /> component into the button, just like in part 2 of this blog series. To give them unique ids, I've generated ids in my formatting map like this:
let SVGID = "ShareExternalLink" + Math.random().toString(16).slice(2)I left the single blog SVG id as "ShareExternalLink" since it will be the only one on the page.
Time to revisit my blog CSS a third time.

Some of the styling fixes were easy - my heading rules just needed to start at <h2> instead of <h1>. My <ul> styling was broken because I hadn't taken <ol>s into consideration. I also added a left margin to get the list discs in line with the text.
My code block styling was easier to deal with than last time - the <pre> and <code> structure made more sense. After updating the class rules to element selector rules, I had to switch some rules around to give my <pre>s that weren't wrapped in <p>s a background that covered all the lines of code, unbroken. Then, I had to play around a bit with margins and padding until I remembered what I was trying to do with the inline code.
I also noticed a weird behavior with my "Blog" heading/button, found I had accidentally left the heading for my Loading component inside the <div>, and moved it out.
Styling my <img>s wrapped in <p>s without a class stumped me for a while. Why is there no parent CSS selector!? A lot of googling and complaining later, I land on display: block; and margin: auto; which center my images! After this jogs my memory, I also add display: inline-block to my inline formatted code and liked the way it offsets the text from the code.
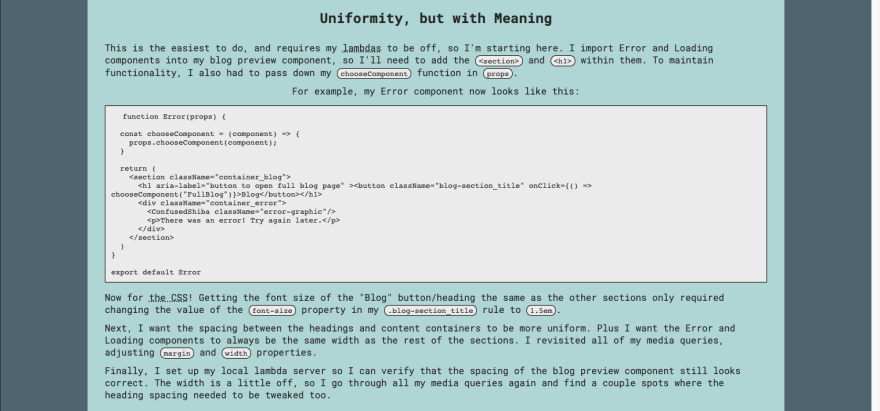
After all my styling is reapplied, I scroll through and end up adding a few things - a <h4> rule, some margins, and a new line to a blog post where the <img> needed to be further away from the text. I'm not super happy with my share button, but I'll use that as motivation to get to that Github issue.
My <pre> blocks are set to 100% width in my last media query. My headings have no width rules. It looks strange when they're all different lengths, and one or both are probably the source of my reflow issues.
First, I find the one width constraint rule for this page that I have in all of my media queries. I find the likely overflow culprits and consolidate their width rules into one. After this is applied, I notice my blog containers are all different sizes, and add a min-width rule to the .blog class rule block in all my media queries. Then I resize my window and find what is still overflowing - those pesky <ul>s and <ol>s! I end up with two rules repeated across media queries that look like this:
.blog pre, .blog p, .blog blockquote, .blog h2, .blog h3, .blog h4, .blog ul, .blog ol {
max-width: 250px;
}.blog {
min-width: 280px;
}I resize my window again, and still see the horizontal scrollbar. Eventually I find it's my links that aren't wrapping! The third rule I added looks like this:
a {
word-wrap: break-word;
overflow-wrap: break-word;
}I zoom in to 400% and voila! No more reflow issues. I scroll through one last time and notice my lists aren't uniformly centered. I end up setting them to a static width 100px less than the max-width rule, and that solves the problem.
In a shocking twist, this page no longer scrolls horizontally in landscape on mobile. I have no idea what made it do that in the first place, but apparently, I've fixed it without pushing any code I've produced while writing this blog.
For this section, I retest with ARC Toolkit and IBM Equal Access Accessibility Checker. While I was checking for skipped headings in my blogs on DEV, I removed line breaks and the italicized lines about when the blog was originally published on Medium. This cut down significantly on the number of warnings about <em> elements. The <q> and <quoteblock> warnings are about places in my blogs where I quote myself, present a hypothetical or mantra, or put quotations around text you would see on the screen or that I'm adding to my site. The places where I quote other people are properly surrounded by <quoteblock>. The "use more list elements" warnings are about places where a lot of links or code blocks appear under an <h3> wrapped in a <p>. They wouldn't make sense as lists, so those are fine.
While I was pondering what the "use more list elements" warnings could be about, I realized my <ol> elements are styled with discs, not numbers. Luckily, all I had to do was move list-style-type: disc; out of my .blog li rule and into a .blog ul rule instead.
I'm getting new errors about using title on an element that isn't interactive. It would seem I added titles to two images by adding them in quotes after the link:

*Knit by Abbey Perini, pattern by Dowland by Dee O'Keefe, yarn is Meeker Street by The Jewelry Box*After reading up on the title attribute, I remove the two titles.
There are still 11 warnings about making sure meaning conveyed by italics is available to screen readers. One is where I italicized a book title. Eight are about places where I provided a source for the comics I used in blogs, and no meaning is lost there. The final two are captions of images. When I searched for how to create captions on DEV, I only saw recommendations to use <figcaption>s, and adding <figure>, <img>, and <figcaption> elements does not work with react-markdown. I inspect these two elements and with the alt-text, no meaning is lost for screen reader users. If anything, they get more context than sighted users. I did notice, however, that one of the captions isn't centered. Our friends display: block; and margin: auto; quickly fixed that.
I am sad react-markdown isn't parsing <kbd> elements, because they're so cute. I tried a few props in my ReactMarkdown element, but they didn't work, so I morosely update my replaceHeadings function to remove the <kbd>s with regexes too.
function replaceHeadings(markdown) {
let newHeadings
newHeadings = markdown.replace(/\s#{5}\s/g, "\n###### ")
newHeadings = newHeadings.replace(/\s#{4}\s/g, "\n##### ")
newHeadings = newHeadings.replace(/\s#{3}\s/g, "\n#### ")
newHeadings = newHeadings.replace(/\s#{2}\s/g, "\n### ")
newHeadings = newHeadings.replace(/<kbd>/g, "")
newHeadings = newHeadings.replace(/<\/kbd>/g, "")
return newHeadings
}I've got warnings about two elements wrapped in <strong> - one is a line from a knitting pattern, just to make it easier to read for sighted users, so no meaning is lost on a screen reader. The other is a note about the useEffect() dependency array, just to make it stand out. For this one, I want to take the recommendation from ARC Toolkit and put it in a heading instead, but an <h2> is a bit huge, so I just make it a new paragraph.
I'm getting warnings about missing <h1>s, but that will be fixed when I get to that Github issue. I'm also getting warnings about duplicate headings. Hopefully users will understand I like to end my blogs with a "Conclusion" section, and this blog series has a lot of "Problem" headings. Plus, this shouldn't be a problem for screen reader users once I add skip links.
I get warnings about using "non-alphanumeric characters" like | in codeblocks, which still need to be read by the screen reader for the code to make sense, so those will be staying as is. I also get warnings about making sure words like "above" and "below" make sense without visual context. With 20 blogs, checking each instance is a bit of a time consuming project, so I'm making a note to revisit this in the next blog in this series. That will also be a better time to cross post the heading and other changes to Hashnode, and Medium if necessary.
I get 11 "alt-text longer than 150 characters" warnings from IBM Equal Access Accessibility Checker. What can I say, I want to make sure screen reader users get all the information. I could come up with a regex solution of some sort to make a D-link or replace alt with an aria-describedby attribute, but I'd rather shorten 11 alt-texts at this point in my accessibility audit journey. Using Word Counter to get a character count and cmd + F in the elements console in dev tools on my site to find the offenders, I am able workshop them all down. You can tell when I'm proud of an image or code project I've made, because I get verbose.
I am floored only two of the meme alt-texts from Object Oriented Programming in Memes were longer than 150 characters. Unfortunately, the polymorphism meme had "image," but I can see why I wanted to delineate where the caption ended and the image of the claymation pirate began.

Not shockingly, a few of the longest alt-texts had "screenshot" in them. Typically when using "screenshot" I want to convey that it is a screenshot of a webpage for context in the blog and I didn't get any warnings about using the word, but I'll think on what I could replace it with while writing alt-text in the future.
During my retest for the previous section, I only got errors for one instance where I used "gif" in alt-text in a blog and a couple places where I used it in my portfolio section on the main page. I have removed all three. I have no excuse for calling the Moira gif a gif in my blog alt-text, but I remember being very proud of the gif walkthroughs I made for projects, and we know how that goes in my alt-text.
I want to add a skip link for my blog preview component and for my FullBlog component when I return all of my blogs. I start by adding CSS classes provided by Carnegie Museums:
/* skip links */
.screenreader-text {
position: absolute;
left: -999px;
width: 1px;
height: 1px;
top: auto;
}
.screenreader-text:focus {
color: black;
display: inline-block;
height: auto;
width: auto;
position: static;
margin: auto;
}Using, CSS-Tricks' guide I start building the HTML. First, yet another regex to make the lowercase ids with hyphens instead of spaces:
function makeID(title) {
title = title.toLowerCase()
let replaced = title.replace(/\s+/g, "-")
replaced = replaced.replace(/#/g, "")
return replaced
}Next, I make the skip links list and add the ids to article headings when I return all the blogs. Because I don't need a skip link when there's one blog, I refactor one return into two:
if (!state.isLoading && state.blogs !== null) {
let blogList
let skipLinks = []
if (state.blogs.length > 1) {
blogList = state.blogs.map((blog) => {
let SVGID = "ShareExternalLink" + Math.random().toString(16).slice(2)
let markdown = blog.body_markdown
let replaced = replaceHeadings(markdown)
let blogID = makeID(blog.title)
let Href = `#${blogID}`
let skipLinkID = blogID + Math.random().toString(16).slice(2)
let skipLink = <li id={skipLinkID}><a href={Href}>{blog.title}</a></li>
skipLinks.push(skipLink)
return (
<article className="blog">
<h2 id={blogID}>{blog.title}</h2>
<a href={blog.url} target="_blank" rel="noreferrer"><button className="preview_button">Share <ExternalLink className="external-link" id={SVGID} focusable="false"/></button></a>
<ReactMarkdown children={replaced} remarkPlugins={[remarkGfm]}></ReactMarkdown>
</article>
)
})
return (
<section aria-label="Full list of Abbey's blog posts" className="full-blog">
<div className="screenreader-text">
Skip directly to a blog:
<ol>
{skipLinks}
</ol>
</div>
{blogList}
</section>
)
} else {
let markdown = state.blogs.body_markdown
let replaced = replaceHeadings(markdown)
return (
<section aria-label="Full list of Abbey's blog posts" className="full-blog">
<article key={state.blogs.id} className="blog">
<h2>{state.blogs.title}</h2>
<a href={state.blogs.url} target="_blank" rel="noreferrer"><button className="preview_button">Share <ExternalLink className="external-link" id="ShareExternalLink" focusable="false"/></button></a>
<ReactMarkdown children={replaced} remarkPlugins={[remarkGfm]}></ReactMarkdown>
</article>
</section>
)
} else if (!state.isLoading && state.error) {
return (
<Error />
)
} else {
return (
<Loading />
)
}I fire up the screen reader and it works! There is probably some tweaking to do, but that's a task for next blog's final testing. Now to apply it to my blog preview component. The next section already has an id="about" attribute, so all I have to do is add the link to the Blog component's return statement:
return (
<section aria-label="Blog Previews" className="container_blog">
<h2 aria-label="button to open full blog page" ><button className="blog-section_title" onClick={() => chooseComponent("FullBlog")}>Blog</button></h2>
<a className="screenreader-text" href='#about'>Skip directly to the next section.</a>
<div className="scroll-cropper">
<ul aria-label="previews of Abbey's blog posts" className="blog-preview">
{blogPreviewList}
</ul>
</div>
</section>
)It works beautifully, but makes me realize that the skip links in my FullBlog component aren't actually becoming visible on focus. Several minutes of CSS shenanigans later, and I add four things:
- a
<p>tag that should have been around "Skip directly to a blog:" in the first place -
tabIndex="0"to that<p>tag -
role="navigation"so thattabIndex="0"is acceptable - the
:focus-withinpseudo selector to the CSS rule that originally only had.screenreader-text:focus
The result is beautiful:

This blog in particular and the series as a whole has been a massive endeavor. I took a break for a few days after part 4 because I sorely needed it. Still, at this point I've written over 11,000 words about accessibility auditing and coded a long list of fixes in 20 days across 5 blogs. I typically only manage a few hundred to 2,000 words a month. While I am looking forward to wrapping this series up, it has been nice to get back to frontend code for the first time in a while.
At some point after this blog series and the Github issues, I'd like to come back and refactor my CSS to use far fewer margins. I'll be looking into flex-basis and might even switch to using CSS grid. I should also come up with a solution for my local lambda server that doesn't involve hardcoded links. (You can read about how it ended up that way in the walkthrough.) GitGuardian is saying I committed my DEV API key even though I tried really hard not to, so I revoked the one I was working with in this blog and replaced it when I deployed.
I would be remiss if I didn't thank @kirkcodes for being a sounding board and Virtual Coffee November Challenge accountibilibuddy for this entire roller coaster.
41