
22
Why Ignoring Response Codes is Not a Good Strategy
On a dark, dismal day in Melbourne, with rain pouring down our office windows, our team was contemplating whether or not to run AWS S3 and CloudFront performance tests. Finally, we decided that running a performance test is a good idea.
The objectives of the test was as follows:
- Identify any configuration related issues with CloudFront and S3.
- Determine whether these services can handle the anticipated load.
You may be wondering why there is a need when CloudFront can manage 100,000 requests/sec per distribution and S3 can handle 5500 GET requests/sec. So did we, until we ran into a problem that none of us had expected. If left uncorrected, it would have had an impact on end-user experience (and sales).
To test this scenario:
- Static content (Product images, JS, CSS, etc) from our existing production copied to the new infrastructure.
- Existing CDN logs from production used to design the application simulation model (ASM) to test the new infrastructure.
- Static content URL's data extracted from access logs for load testing. Replaying static content URL's to test CloudFront & S3 based on the ASM.
- Test scenario created in JMeter
- Load generated and analysis done through Octoperf.
The HTTP response code pie chart generated at the end of the test is shown below. Except for 7.6% HTTP 404 responses and the remaining 92.4% HTTP 200 responses, nothing out of the ordinary.
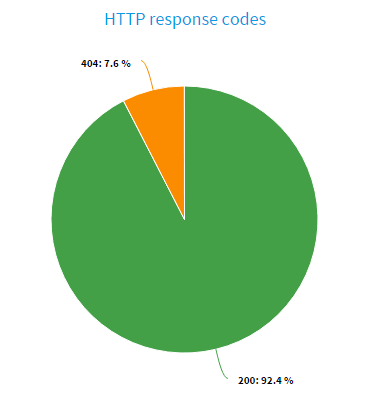
At this point, I saw that I was not seeing 7.5% 404s for static content in our production. Furthermore, the data utilized in testing is an exact replica of the data used in production. As a result, there is no reason for such a high failure rate.
I informed the team of my discovery, and within an hour of our investigation, we had located the fundamental cause of the problem. The fundamental issue was how Windows and Linux operating systems handled file structure.
The current production architecture is based on Windows OS. Because the Windows file system is not case sensitive, it treats both upper and lower case names as the same file. Unlike the Linux file system (S3 bucked installed), which is case sensitive.
From the perspective of the customer, this means that they will obtain a 404 for product photos (as an example). This is because the requested picture URL path resolves to an invalid location in the S3 bucket. For example, the following is a response from Cloudfront to one of the static requests. Take note of the "N" in the file path; the actual folder in the S3 bucket ends with "n," not "N."

Because the Windows file system is not case sensitive, it resolves to an existing path.
Take away from this post are:
1. Don't neglect Non HTTP 200 response codes during your study. They might reveal a lot about the state of your system.
2. There is some validity in leveraging production data to perform performance testing on your system.
3. You do not always need to execute an end-to-end test. Understand the test's aim and build your tests accordingly.
4. Compare your results to existing statistical data if you have it.
Thanks for reading!
If you enjoyed this article feel free to share on social media 🙂
Github repo: hseera
22