
22
GANs for Super-Resolution
The task of estimating a high-resolution image from its low-resolution counterpart is referred to as super-resolution. This has a wide variety of uses, including (but not limited to) the medical field for low radiation digital X-ray mammography, upscaling microscopy images, field-surface topography refinement etc.
Typical approaches to super-resolution attempt to minimize the difference between the upscaled image and the original high-resolution sample.
The upscaled image is that which has been interpolated from its low resolution counterpart.
The problem is framed as a supervised learning problem, where ground truth is taken as the original image, and the prediction is the upscaled image. This technique has been very succesful at resolving low-frequency features, since the resulting upscaled image typically has a high signal-to-noise ratio (SNR). There are a few general categories within which super-resolution techniques lie, which I won't go into in this post. See the attached links if you like for more details
Prediction-based
Blind Super-Resolution With Iterative Kernel Correction
CNN-Based -
Deep networks for image super-resolution with sparse prior, upscaling filters and embeddings learn
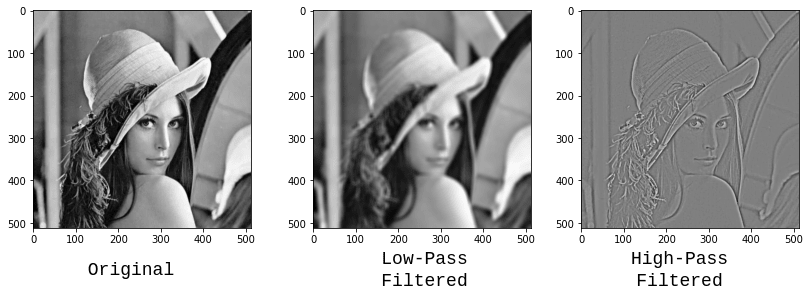
Classical methods however, typically lack finer details since most high-frequency data is not preserved, resulting in significant perceptual losses during the process (i.e. the resulting image, while high-resolution, is not photo-realistic). High-frequency data are typically the fine details in textures, which characterize objects such as human skin, animal fur, or any other visual feature which is relatively small.
The pictures below show features preserved during high-pass and low-pass filtering. Notice how in the high-pass filter, the edges are neatly preserved, however the finer details (skin, hair, texture in the hat and more) are lost
The generative adversial network was first proposed in a 2014 paper. The idea was to have two separate neural networks called the generator G and the discriminator D. The generator network would attempt to draw images without explicit input to mirror images found in a dataset.
In other words, it would attempt to approximate the distribution of data (as images) by building a latent representation of the original input data within its layers. The discriminator network would is trained in a supervised manner to distinguish between images generated by the generator network, and images originally found in the dataset. More formally, the training procedure is as follows:
- Generator network produces images, taking a random vector as its input and outputs its best guess at what actual images found in the dataset should look like
- The discriminator network is trained in a supervised manner to distinguish between real-world images and images produced by the generator
- Both networks are connected sequentially, with the discriminator network's weights frozen. Training now occurs, where only the generator's weights are updated. The output from the discriminator (connected in series with the generator), is used to guide the weight-updating process of the generator network, where the goal is to consistently 'fool' the discriminator into thinking that generator images are real
- This process continues iteratively until the desired metric is achieved (or output images from the generator look 'real enough'
The diagram below is from a 2017 CVPR Paper, showing the generator and discriminator networks as used for super-resolution. The generator network (upper diagram) is connected behind the discriminator network for the purposes of training as described in the training procedure above.

In the description of how a GAN is used to produce a high-resolution image, I didn't cover exactly how the discriminator network distinguishes between real and generated (upscaled) images. It turns out that there have been many different ideas on what the ideal error function should be for the task of super resolution.
The classic Mean-Squared Error has recently come under fire in the research community for its non-monotonic increase with respect to actual average error, in addition to other problems. However, this is most plainly manifest in images produced by GANs trained to minimize the MSE of its output when referenced to the real-world image.
MSE struggles to handle high uncertainty in high-frequency details such as texture, and results in overly smooth images with poor perceptual quality

This is where the perceptual loss comes in, which is calculated between feature mappings within convolutional layers, and further normalised by the area of the feature map. The net error for a given pair of images (original and upscaled) is the sum of differences between feature representations of the upscaled image and the reference (high-resolution) image.
In practice, the perceptual loss is taken as a sum of content loss and adversarial loss. The content loss measures direct differences between mappings at various convolutional layers for the real (high-resolution) and upscaled image. It is a quantitative measurement at multiple convolutional layers of the similarity between the real and upscaled image.
The adversarial loss is the negative log-probability of a reconstructed image being a natural high-resolution image. In other terms, the likeliness of the image under scrutiny not being produced by the generator. This forces the generator to produce images which fall into the domain of the original input image set. (See this paper for full detail in how the loss above is calculated and the more detailed justification for such)
Super-resolution has a wide array of applications both in the fields of research and industry. Recent efforts have been made to increase the quality of the images produced by a super-resolution model. The GAN for super-resolution and the intuitive perceptual loss function as outlined in this blog post is one of the most recent applications of GANs. Its main advantage lies in the increased spatial resolution of high-frequency signals, resulting in more real-to-life looking images.
However, there are a few notable drawbacks such as increased training times as the depth of the neural networks become deeper. Additionally, the content loss as outlined above is not a one-size-fits-all solution, as the application of the method heavily steers what the desired output images should be.
It will be quite exciting to see new advances in the upcoming years in this field.
22