
18
AWS Well-Architected Framework | AWS Whitepaper Summary
Hi folks , Today I will go through with one of the most important whitepapers in AWS
Original One
The AWS Well-Architected Framework helps you understand the pros and cons of decisions you make while building systems on AWS. By using the Framework, you will learn architectural best practices for designing and operating reliable, secure, efficient, and cost-effective systems in the cloud. It provides a way for you to consistently measure your architectures against best practices and identify areas for improvement.
AWS also provides a service for reviewing your workloads at no charge. The AWS Well-Architected Tool (AWS WA Tool) is a service in the cloud that provides a consistent process for you to review and measure your architecture using the AWS Well-Architected Framework. The AWS WA Tool provides
recommendations for making your workloads more reliable, secure, efficient, and cost-effective
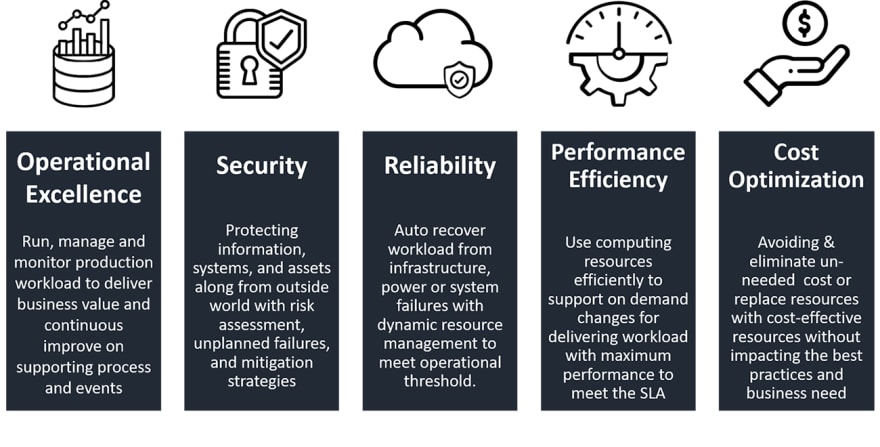
The AWS Well-Architected Framework is based on five pillars —
- Operational excellence The ability to support development and run workloads effectively, gain insight into their operations, and to continuously improve supporting processes and procedures to deliver business value
- Security The security pillar describes how to take advantage of cloud technologies to protect data, systems, and assets in a way that can improve your security posture.
- Reliability The reliability pillar encompasses the ability of a workload to perform its intended function correctly and consistently when it’s expected to. This includes the ability to operate and test the workload through its total lifecycle.
- Performance efficiency The ability to use computing resources efficiently to meet system requirements, and to maintain that efficiency as demand changes and technologies evolve.
- Cost optimization The ability to run systems to deliver business value at the lowest price point
- Sustainability a Pillar to help organizations learn, measure, and improve workloads using environmental best practices for cloud computing
The Operational Excellence pillar includes the ability to support development and run workloads effectively, gain insight into their operations, and to continuously improve supporting processes and procedures to deliver business value
1.Perform operations as code
2.Make frequent, small, reversible changes
3.Refine operations procedures frequently
4.Anticipate failure
5.Learn from all operational failures
There are four best practice areas for operational excellence in the cloud:
1.Organization
- Your teams need to have a shared understanding of your entire workload and shared business goals to set the priorities that will enable business success.
- Evaluate internal and external customer needs involving key stakeholders, including business, development, and operations teams, to determine where to focus efforts.
- Evaluating customer needs will ensure that you have a thorough understanding of the support that is required to achieve business outcomes.
- Understanding the business value of each component, process, and procedure, of why those resources are in place or activities are performed, and why that ownership exists will inform the actions of your team members.
- Define agreements between teams describing how they work together to support each other and your business outcomes.
- Provide support for your team members so that they can be more effective in taking action and supporting your business outcomes.
- Empower team members to take action when outcomes are at risk to Provide timely, clear, and actionable communications of known risks and planned events so that team members can take timely
- If there are external regulatory or compliance requirements that apply to your organization, you should use the resources provided by AWS Cloud Compliance to help educate your teams so that they can determine the impact on your priorities.
- You should use the resources provided by AWS Support (AWS Knowledge Center, AWS Discussion Forums, and AWS Support Center) and AWS Documentation to educate your teams.
2.Prepare
When you understand your workloads and their expected behaviors, capture a broad set of information to enable situational awareness (for example, changes in state, user activity, privilege access, utilization counters), knowing that you can use filters to select the most useful information over time.
These accelerate beneficial changes entering production:
- Limit issues deployed
- Enable rapid identification and remediation of issues introduced through deployment
- Adopt approaches that provide fast feedback on quality and enable rapid recovery from changes that do not have desired outcomes.
- Be aware of planned activities in your environments so that you can manage the risk of changes impacting planned activities.
- Understand the benefits and risks to make informed decisions to allow changes to enter production.
3.Operate
- Successful operation of a workload is measured by the achievement of business and customer outcomes.
- Define expected outcomes,
- Determine how success will be measured
- Identify metrics that will be used in those calculations to determine if your workload and operations are successful.
- Use collected metrics to determine if you are satisfying customer and business needs, and identify areas for improvement.
Efficient and effective management of operational events is required to achieve operational excellence.
4.Evolve
You must learn, share, and continuously improve to sustain operational excellence. Include feedback loops within your procedures to rapidly identify areas for improvement and capture learnings from the execution of operations.
Analyze trends within lessons learned and perform cross-team retrospective analysis of operations metrics to identify opportunities and methods for improvement.
Successful evolution of operations is founded in: frequent small improvements; providing safe environments and time to experiment, develop, and test improvements; and environments in which learning from failures is encouraged. Operations support for sandbox, development, test, and production environments, with increasing level of operational controls, facilitates development and increases the predictability of successful results from changes deployed into production
Check out this Session also
The Security pillar encompasses the ability to protect data, systems, and assets to take advantage of cloud technologies to improve your security
1.Implement a strong identity foundation (least privilege, separation of duties, no long-term static credentials)
2.Enable traceability (Monitor, alert, and audit actions)
3.Apply security at all layers
4.Automate security best practices
5.Protect data in transit and at rest
6.Keep people away from data
7.Prepare for security events
There are six best practice areas for security in the cloud:
1.Security
- You must apply overarching best practices to every area of security.
- Staying up to date with AWS and industry recommendations and threat intelligence
- Automate security processes, testing, and validation
2.Identity and Access Management
- You should define principals (that is, accounts, users, roles, and services that can perform actions in your account)
- Build out policies aligned with these principals
- Implement strong credential management
- You should apply granular policies in IAM Service
- Apply strong password practices
- Use temporary credentials
- Credentials must not be shared between any user or system
- Follow least-privilege approach
3.Detection
- Use detective controls to identify a potential security threat or incident
- Use internal auditing, an examination of controls
- Automate alerting notifications based on defined conditions
- CloudTrail logs, AWS API calls, and CloudWatch provide monitoring of metrics with alarming, and AWS Config provides configuration history
- Use GuardDuty to detect malicious or unauthorized behavior
4.Infrastructure Protection
Any workload that has some form of network connectivity, whether it’s the internet or a private network, requires multiple layers of defense to help protect from external and internal network-based threats.
5.Data Protection
- You can encrypt your data and manage keys
- Detailed logging that contains important content, such as file access and changes, is available
- Versioning, which can be part of a larger data lifecycle management process
- AWS never initiates the movement of data between Regions
5.Incident Response
- Detailed logging is available that contains important content, such as file access and changes
- Events can be automatically processed and trigger tools that automate responses through the use of AWS APIs
Ensure that you have a way to quickly grant access for your security team, and automate the isolation of instances as well as the capturing of data and state for forensics
The AWS Shared Responsibility Model enables organizations that adopt the cloud to achieve their security and compliance goals. Because AWS physically secures the infrastructure that supports our cloud services, as an AWS customer you can focus on using services to accomplish your goals.
Is the ability of a workload to perform its intended function correctly and consistently when it’s expected to.
- Automatically recover from failure
- Test recovery procedures
- Scale horizontally to increase aggregate workload availability
- Stop guessing capacity
- Manage change in automation
There are four best practice areas for reliability in the cloud:
1.Foundations
It’s the responsibility of AWS to satisfy the requirement for sufficient networking and compute capacity service quotas (which are also referred to as service limits). These quotas exist to prevent accidentally provisioning more resources than you need and to limit request rates on API operations so as to protect services from abuse
2.Workload Architecture
AWS SDKs take the complexity out of coding by providing language-specific APIs for AWS services. These SDKs, plus the choice of languages, allow developers to implement the reliability best practices listed here
Your workload must operate reliably despite data loss or latency in these networks
3.Change Management
- Changes like (spikes in demand, feature deployments and security patches) must be anticipated
- You can monitor the behavior of your workload and take action like add additional servers as a workload gains more users
- You can control who has permission to make workload changes and audit the history of these changes
- Controls on change management ensure that you can enforce the rules that deliver the reliability you need.
4.Failure Management
- Workloads must be able to both withstand failures and automatically repair issues
- With AWS , when a particular metric crosses a threshold, you can trigger an automated action to remedy the problem
- You can replace failed resources without wasting time to fix it
- Regularly back up your data and test your backup files
- Actively track KPIs, as well as the recovery time objective (RTO) and recovery point objective (RPO)
- Your recovery processes should be as well exercised as your normal production processes
Is the ability to use computing resources efficiently to meet system requirements, and to maintain that efficiency as demand changes and technologies evolve
- Democratize advanced technologies (Rather than asking your IT team to learn about hosting and running a new technology, consider consuming the technology as a service)
- Go global in minutes (Multiple AWS Regions)
- Use serverless architectures
- Experiment more often
- Consider mechanical sympathy i.e.: Understand how cloud services are consumed
There are four best practice areas for performance efficiency in the cloud:
1.Selection
- Use a data-driven approach to select the patterns and implementation for your architecture and achieve a cost effective solution
- The implementation of your architecture will use the AWS services that are specific to the optimization of your architecture's performance
- Here we will discuss the four main resource types to consider (compute, storage, database, and network).
Compute
- We have 3 types (Instances, Containers and Functions)
- The optimal compute solution for a workload varies based on application design, usage patterns, and configuration settings
- You can use different compute solutions for various components
Storage
- Cloud storage is typically more reliable, scalable, and secure
- Storage is available in three forms: object, block, and file
- The optimal storage solution for a system varies based on the kind of access method (block, file, or object), patterns of access (random or sequential), required throughput, frequency of access (online, offline, archival), frequency of update (WORM, dynamic), and availability and durability constraints. Well-architected systems use multiple storage solutions and enable different features to improve performance and use resources efficiently.
Database
- The cloud offers purpose-built database services that address different problems presented by your workload
- You have relational, key-value, document, in-memory, graph, time series, and ledger databases
- You don’t need to worry about database management tasks such as server provisioning, patching, setup, configuration, backups, or recovery
- The optimal database solution for a system varies based on requirements for availability, consistency, partition tolerance, latency, durability, scalability, and query capability
Network
- You must determine the workload requirements for bandwidth, latency, jitter, and throughput
- On AWS, networking is virtualized and is available in a number of different types and configurations
- You must consider location when deploying your network. You can choose to place resources close to where they will be used to reduce distance
- By taking advantage of Regions, placement groups, and edge services, you can significantly improve performance
2.Review
- You must ensure that workload components are using the latest technologies and approaches to continually improve performance
- You must continually evaluate and consider changes to your workload components
- Use Machine learning and artificial intelligence (AI) will enable you to innovate across all of your business workloads
3.Monitoring
- You must monitor its performance so that you can remediate any issues before they impact your customers
- Amazon CloudWatch is your hero!
- AWS X-Ray helps developers analyze and debug production
4.Tradeoffs
You could trade consistency, durability, and space for time or latency, to deliver higher performance.
As you make changes to the workload, collect and evaluate metrics to determine the impact of those changes. Measure the impacts to the system and to the end-user to understand how your trade-offs impact your workload. Use a systematic approach, such as load testing, to explore whether the tradeoff improves performance.
Is the ability to run systems to deliver business value at the lowest price point
- Implement Cloud Financial Management
- Adopt a consumption model (Pay only for the computing resources that you require)
- Measure overall efficiency (Business output Vs Cost)
- Stop spending money on undifferentiated heavy lifting (AWS will do!)
- Analyze and attribute expenditure (This helps measure return on investment (ROI))
There are five best practice areas for cost optimization in the cloud:
1.Practice Cloud Financial Management
- You can use Cost Explorer, and optionally Amazon Athena and Amazon QuickSight with the Cost and Usage Report (CUR), to provide cost and usage awareness throughout your organization
- AWS Budgets provides proactive notifications for cost and usage
- Implement cost awareness in your organization
2.Expenditure and usage awareness
- Accurate cost attribution allows you to know which products are truly profitable, and allows you to make more informed decisions about where to allocate budget
- You create an account structure with AWS Organizations for cost and usage
- You can also use resource tagging to apply business and organization information to your usage and cost
- Use AWS Cost Explorer for visibility into your cost and usage
- Create customized dashboards and analytics with Amazon Athena and Amazon QuickSight
- Controlling your cost with AWS Budgets
- You can use cost allocation tags to categorize and track your AWS usage and costs
3.Cost-effective resources
- Use the appropriate instances and resources for your workload is key to cost savings
- Use managed services to reduce costs
- AWS offers a variety of flexible and cost-effective pricing options to acquire instances from Amazon EC2 (On-Demand Instances/ Savings Plans/ Reserved Instances/ Spot Instances)
- Use CloudFront to minimize data transfer, or completely eliminate costs
- Utilizing Amazon Aurora on RDS to remove expensive database licensing costs
- Use AWS Trusted Advisor to regularly review your AWS usage
4.Manage demand and supply resources
- You can supply resources to match the workload demand at the time they’re needed, this eliminates the need for costly and wasteful over Resources provisioning
- Auto Scaling using demand or time-based approaches allow you to add and remove resources as needed
- You can use Amazon API Gateway to implement throttling, or Amazon SQS to implementing a queue in your workload. These will both allow you to modify the demand on your workload components.
5.Optimize over time
- Implementing new features or resource types can optimize your workload incrementally
- You can also replace or add new components to the workload with new services
- You must Regularly review your workload
Recently AWS introduced a new AWS Well-Architected Sustainability Pillar to help organizations learn, measure, and improve workloads using environmental best practices for cloud computing.
Sustainable development
can be defined as “development that meets the needs of the present without compromising the ability of future generations to meet their own needs.” Your business or organization can have negative environmental impacts like direct or indirect carbon emissions, unrecyclable waste, and damage to shared resources like clean water
When building cloud workloads, the practice of sustainability is understanding the impacts of the services used, quantifying impacts through the entire workload lifecycle, and applying design principles and best practices to reduce these impacts
Design principles for sustainability in the cloud
Apply these design principles when architecting your cloud workloads to maximize sustainability and minimize impact.
Understand your impact: Measure the impact of your cloud workload and model the future impact of your workload. Include all sources of impact, including impacts resulting from customer use of your products, and impacts resulting from their eventual decommissioning and retirement
Establish sustainability goals: For each cloud workload, establish long-term sustainability goals such as reducing the compute and storage resources required per transaction. Model the return on investment of sustainability improvements for existing workloads, and give owners the resources they need to invest in sustainability goals.
Maximize utilization: Right-size workloads and implement efficient design to ensure high utilization and maximize the energy efficiency of the underlying hardware. Two hosts running at 30% utilization are less efficient than one host running at 60% due to baseline power consumption per host
Anticipate and adopt new, more efficient hardware and software offerings: Support the upstream improvements your partners and suppliers make to help you reduce the impact of your cloud workloads
Use managed services: Sharing services across a broad customer base helps maximize resource utilization, which reduces the amount of infrastructure needed to support cloud workloads. For example, customers can share the impact of common data center components like power and networking by migrating workloads to the AWS Cloud and adopting managed services, such as AWS Fargate for serverless containers, where AWS operates at scale and is responsible for their efficient operation
Reduce the downstream impact of your cloud workloads: Reduce the amount of energy or resources required to use your services. Reduce or eliminate the need for customers to upgrade their devices to use your services. Test using device farms to understand expected impact and test with customers to understand the actual impact from using your services.
Finally , Thanks for your patient to read this summary and I Hope you saw it useful
18