
22
Monitoring Systems with Canaries
You launched your service and rapidly onboarding customers. You're moving fast, repeatedly deploying one new feature after another. But with the uptick in releases, bugs are creeping in and you're finding yourself having to troubleshoot, rollback, squash bugs, and then redeploy changes. Moving fast but breaking things. What can you do to quickly detect issues — before your customers report them?
Canaries.
In this post, you'll learn about the concept of canaries, example code, best practices, and other considerations including both maintenance and financial implications with running them.

Back in early 1900s, canaries were used by miners for detecting carbon monoxide and other dangerous gases. Miners would bring their canaries down with them to the coalmine and when their canary stopped chirping, it was time for the everyone to immediately evacuate.
In the context of computing systems, canaries perform end-to-end testing, aiming to exercise the entire software stack of your application: they behave like your end-users, emulating customer behavior. Canaries are just pieces of software that are always running and constantly monitoring the state of your system; they emit metrics into your monitoring system (more discussion on monitoring in a separate post), which then triggers an alarm when some defined threshold breaches.
Canaries answer the question: "Is my service running?" More sophisticated canaries can offer a deeper look into your service. Instead of canaries just emitting a binary 1 or 0 — up or down — they can be designed such that they emit more meaningful metrics that measure latency from the client's perspective.
If you don't have any canaries running that monitor your system, you don't necessarily have to start with rolling your own. Your first canary can require little to no code. One way to gain immediate visibility into your system would be to use synthetic monitoring services such as BetterUptime or PingDom or StatusCake. These services offer a web interface, allowing you to configure HTTP(s) endpoints that their canaries will periodically poll. When their systems detect an issue (e.g. TCP connection failing, bad HTTP response), they can send you email or text notifications.
Or if your systems are deployed in Amazon Web Services, you can write Python or Node scripts that integrate with CloudWatch (click here for Amazon CloudWatch documentation).
But if you are interested in developing your own custom canaries that do more than a simple probe, read on.
Remember, canaries should behave just like real customers. Your customer might be a real human being or another piece of software. Regardless of the type of customer, you'll want to start simple.
Similar to the managed services describe above, your first canary should start with emitting a simple metric into your monitoring system, indicating whether the endpoint is up or down. For example, if you have a web service, perform a vanilla HTTP GET. When successful, the canary will emit http_get_homepage_success=1 and under failure, http_get_homepage_success=0.
Imagine you have a simple key/value store system that serves as a caching layer. To monitor this layer, every minute our canary will: 1) perform a write 2) perform a read 3) validate the response.
while(True):
successful_run = False
try:
put_response = cache_put('foo', 'bar')
write_successful = put_response == 'OK'
Publish_metric('cache_engine_successful_write', write_successful)
value = cache_get('foo')
successful_read = value = 'bar'
publish_metric('cache_engine_successful_read', is_successful_read)
canary_successful_run = True
Except as error:
log_exception("Canary failed due to error: %s" % error)
Finally:
Publish_metric('cache_engine_canary_successful_run', int(successful_run))
sleep_for_in_seconds = 60
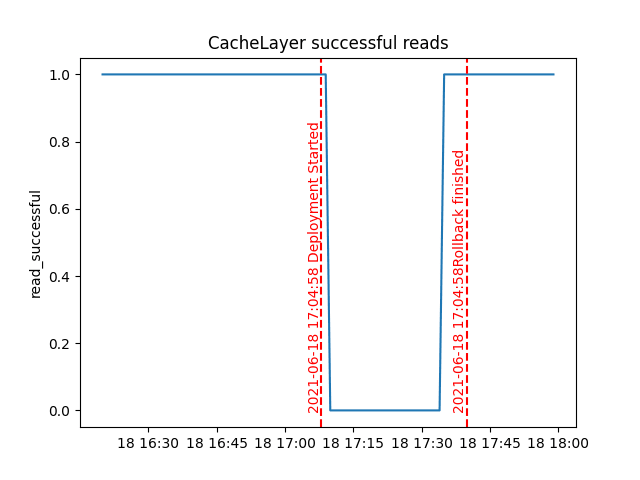
sleep(sleep_for_in_seconds)With this canary in place emitting metrics, we might then choose to integrate the canary with our code deployment pipeline. In the example below, I triggered a code deployment (riddled with bugs) and the canary detected an issue, triggering an automatic rollback:
The above code example was very unsophisticated and you'll want to keep the following best practices in mind:
- The canaries should NOT interfere with real user experience. Although a good canary should test different behaviors/states of your system, they should in no way interfere with the real user experience. That is, their side effects should be self contained.
- They should always be on, always running, and should be testing at a regular intervals. Ideally, the canary runs frequently (e.g. every 15 seconds, every 1 minute).
- The alarms that you create when your canary reports an issue should only trigger off more than one datapoint. If your alarms fire off on a single data point, you increase the likelihood of false alarms, engaging your service teams unnecessarily.
- Integrate the canary into your continuous integration/continuous deployment pipeline. Essentially, the deployment system should monitor the metrics that the canary emits and if an error is detected for more then N minutes, the deployment should automatically roll back (more of safety of automated rollbacks in a separate post)
- When rolling your own canary, do more than just inspect the HTTP headers. Success criteria should be more than verifying that the HTTP status code is a 200 OK. If your web services returns payload in the form of JSON, analyze the payload and verify that it's both syntactically and semantically correct.
Of course, canaries are not free. Regardless of whether or not you rely on a third party service or roll your own, you'll need to be aware of the maintenance and financial costs.
A canary is just another piece of software. The underlying implementation may be just few bash scripts cobbled together or full blown client application. In either case, you need to maintain them just like any other code package.
How often is the canary running? How many instances of the canary are running? Are they geographically distributed to test from different locations? These are some of the questions that you must ask since they impact the cost of running them.
When building systems, you want a canary that behaves like your customer, one that allows you to quickly detect issues as soon as your service(s) chokes. If you are vending an API, then your canary should exercise the different URIs. If you testing the front end, then your canary can be programmed mimic a customer using a browser using libraries such as selenium.
Canaries are a great place to start if you are just launching a service. But there's a lot more work required to create an operationally robust service. You'll want to inject failures into your system. You'll want a crystal clear understanding of how your system should behave when its dependencies fail. These are some of the topics that I'll cover in the next series of blog posts.
Let's connect and talk more about software and devops. Follow me on Twitter: @memattchung
22