
23
Analisando dados do dataset TMDB 5000 e do MovieLens.
Analisando os dados do dateset TMDB 5000 e do MovieLens.
Nessa análise foi realizado o carregamento dos dados, análise das distribuições, limpezas dos dados que possuem informações estranhas, aplicações de testes, e depois realizar análises das médias e das notas de todos os filme ou filmes específico.
Analisaremos esses dados tanto visualmente, quanto através de estatísticas como z-test, t-test, wilcoxon e gerando intervalo de confiança quando apropriado.
As bibliotecas utilizadas durante a análise foram Stats Models, Scipy, Pandas, Seaborn e Matplotlib.
# Importando a biblioteca Pandas
import pandas as pd
# Lendo o arquivo
tmdb = pd.read_csv('tmdb_5000_movies.csv')
- Budget: Orçamento. Quanto foi gasto para produzir o filme.
- Genres: Gênero do filme.
- homepage: A página do filme.
- id: O Id do filme.
- keywords: Palavras-chave dos filmes.
- original_language: A língua original do filme.
- original_title: O título original do filme.
- overview: Uma descrição.
- popularity: Nota de popularidade onde o próprio TMDB calcula.
- production_companies: Empresas que produziram.
- production_countries: País que produziu.
- release_date: Data de lançamento.
- revenue: Faturamento do filme.
- runtime: Tempo de duração do filme (minutos).
- spoken_languages: Línguas faladas.
- status: Se o filme foi lançado ou não.
- tagline: Uma chamada do filme (propaganda).
- title: O título do filme.
- vote_average: Nota média dos votos.
- vote_count: Quantas votos o filme recebeu.
Para começar a análise, vamos visualizar a média mínima e a média máxima com a função describe():
# Descrevendo o dataset
tmdb.describe()
Perceba que a média (vote_average) vai entre o 0 (min) e 10 (max). Vamos plotar o histograma para visualizar melhor a distribuição das médias:
ax = sns.displot(tmdb.vote_average, kde=True)
ax.set(xlabel = "Nota Média", ylabel = "Densidade")
ax.fig.suptitle("Média de votos em filmes no TMDB 5000")
Visualizando a distribuição com boxplot:
ax = sns.boxplot(x = tmdb.vote_average)
ax.set(title = "Distribuição de nota média dos filmes do TMDB 5000", xlabel = "Nota média do filme")
Observação: Nas visualizações acima percebe-se que existe notas estranhas, uma quantidade de filmes razoáveis cuja a média é 0, e outras quantidades também razoáveis cuja a média é 10; será que no mundo real, temos filmes cuja a média é 0?
Fazendo um simples analogia para entender melhor: na escola ou na faculdade existe a chance de zerar a prova? Sim! Mas qual a chance com 5 provas a média ser 0? A chance é mínima! Em qualquer uma dessas 5 provas tirar pelo menos uma nota 0.1, a média será maior do que 0. Então, olhando para o gráfico existe uma certa quantidade de média 0, e será mesmo que todas as pessoas que votou nesse filme deu nota 0? Vamos então, olhar para esses filmes:
tmdb.query("vote_average == 0").iloc[:, [0, 3, 8, 13, 18, 19]].head()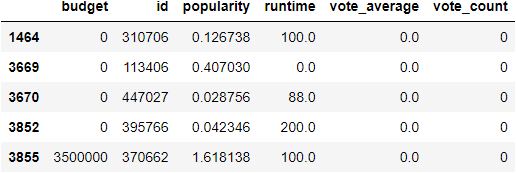
Olhando para a variável vote_average existe dados igual a 0, ou seja, simplesmente ninguém votou nesses filmes! Então, para não atrapalhar nossas análises, vamos eliminar os filmes que tem 0 votos, e aceitar apenas os filmes com mais ou igual a 10 votos:
tmdb.query("vote_count >= 10")
tmdb_com_mais_de_10_votos = tmdb.query("vote_count>= 10")Olhando novamente a descrição (describe()) dos filmes com 10 ou mais votos:
tmdb_com_mais_de_10_votos.describe()
Percebe-se que a média mínima dos votos agora está 1.9, ou seja, alguém deu uma nota para esse filme diferente de zero. Observa-se também que a média máxima dos votos ficou com 8.5, mas por quê?
Nos dados originais tmdb.query("vote_count == 10") os filmes com a média 10 tinha recebido apenas 1 ou 2 votos.
Visualizando a distribuição dos dados no tmdb 5000 dentre os filmes com mais 10 ou mais votos:
ax = sns.displot(tmdb_com_mais_de_10_votos.vote_average, stat="count", kde = False)
ax.set(title = "Média de votos em filmes no TMDB 5000 dentre os filmes com 10 ou mais votos",
xlabel = "Nota média",
ylabel = "Frequência")
Observação: Não existe filme com média 0 ou média 10.
Visualizando agora com os parâmetros stat = "density" e kde = True:

Temos uma curva razoavelmente simétrica, mas repare que o gráfico está sendo "puxado" mais para esquerda (0), do que para o lado direito. Em estatística lembra uma curva normal, que teria uma média simétrica. Percebe-se que no lado direito temos o limite superior (10) bem próximo, ou melhor, está mais próximo do que o o limite inferior (0), então, existe um espaço para que as pessoas deem mais votos para o lado esquerdo baseado na média.
Boxplot:

Até agora, analisamos visualmente a distribuição da nota média dos filmes no TMDB 5000 e vimos que se aproxima de uma distribuição normal. Será que isso bate com os dados do MovieLens? Então, agora vamos analisar o dataset do MovieLens.
notas = pd.read_csv('ratings.csv')
notas.head()
Neste caso, não temos a média dos filmes e sim, a nota que foi dada. Porém, calcularemos a média dos filmes:
nota_media_por_filme = notas.groupby('movieId').mean()['rating']
nota_media_por_filme.head()
Mas... Queremos ver a distribuição de todas as notas? Vamos dar uma olhada:
ax = sns.displot(nota_media_por_filme.values, kde = True, stat='density')
ax.set(title = "Média de votos em filmes no MovieLens 100k",
xlabel = 'Nota média',
ylabel = 'Densidade')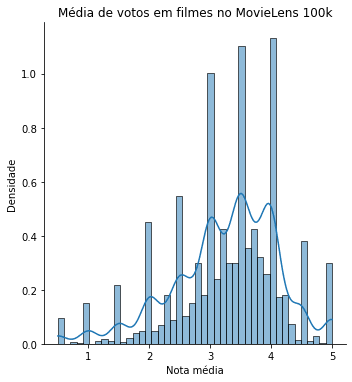
Percebe-se, que as notas aqui vão de 0 a 5, e novamente temos alguns filmes com média 5, e nenhum com média 0. Então, temos alguns filmes com poucos votos. Vamos olhar quantas vezes apareceram:
quantidade_de_votos_por_filme = notas.groupby('movieId').count()
quantidade_de_votos_por_filme.head()
Pegando os filmes que tenham mais do que 10 votos:
filmes_com_pelo_menos_10_votos = quantidade_de_votos_por_filme.query('rating >= 10').index
pd.DataFrame(filmes_com_pelo_menos_10_votos).head()
Agora vamos pegar a nota média por filme e selecionar somente os valores cuja o index esteja no filmes_com_pelo_menos_10_votos:
nota_media_dos_filmes_com_pelo_menos_10_votos = nota_media_por_filme.loc[filmes_com_pelo_menos_10_votos]
pd.DataFrame(nota_media_dos_filmes_com_pelo_menos_10_votos).head()
Visualizando graficamente:
ax = sns.displot(nota_media_dos_filmes_com_pelo_menos_10_votos.values, kde = True, stat='density')
ax.set(title = "Média de votos em filmes no MovieLens 100k com 10 ou mais votos",
xlabel = 'Nota média',
ylabel = 'Densidade')
Novamente limpamos os dados (extremos da esquerda e direita) e podemos comparar visualmente com o dataset do TMDB 5000 e percebe que a visualização ficou similar.
Boxplot do resultado:
ax = sns.boxplot(x = nota_media_dos_filmes_com_pelo_menos_10_votos.values)
ax.set(title = "Distribuição de nota média dos filmes do MovieLens 100k dentre os filmes com 10 ou mais votos",
xlabel = "Nota média do filme")
O lado esquerdo está um pouco mais "gordinho" do que o lado direito. As distribuições de votos (TMDB e MovieLens) significa que as pessoas se comportam de uma maneira similar.
Porém, é difícil olhar para um filme específico, como por exemplo, Toy Story com média 3.9, o que isso quer dizer sobre o filme? Como entra essa informação na distribuição das médias? É um filme bom ou ruim? Parece ser bom, mas o quão bom ele é? Está nos 5%? 10%? Ou, um filme que tem média 3, quão ruim ou quão bom ele é? Vamos entender como um filme específico se encaixa (uma nota específica) na distribuição.
Para entender melhor, vamos visualizar de forma acumulativa:
ax = sns.histplot(nota_media_dos_filmes_com_pelo_menos_10_votos.values,
cumulative = True,
kde = True,
stat = 'density')
ax.set(xlabel="Nota média", ylabel="% acumulada de filmes")
ax.set_title("Média de votos em filmes no Movielens 100k com 10 ou mais votos")
50% dos filmes tem nota 3.5 para baixo, então se o Toy Story tem média 3.9, significa que está no topo de 20%, acima de 80% dos filmes!
Visualizando a distribuição acumulativa dos dados no TMDB 5000:
ax = sns.histplot(tmdb_com_mais_de_10_votos.vote_average,
cumulative = True,
kde = True,
stat = 'density')
ax.set(xlabel="Nota média", ylabel="% acumulada de filmes")
ax.set_title("Média de votos em filmes no TMDB 5000 com 10 ou mais votos")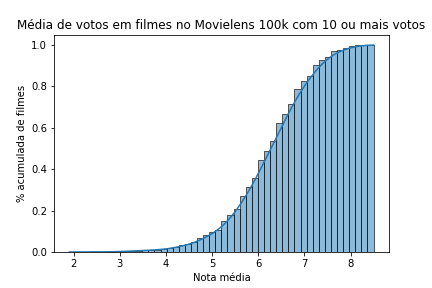
Visualizamos a distribuição que montamos baseado nos dados empíricos dos datasets (TMDB e MovieLens), dado esse conjunto de votos que analisamos, quais são as outras variáveis que podemos visualizar?
Analisaremos agora o número de votos (vote_count):
ax = sns.histplot(tmdb_com_mais_de_10_votos.vote_count, kde = True, stat = 'density')
ax.set(title = 'Número de votos em filmes do TMDB 5000 com 10 ou mais votos',
xlabel = 'Número de votos',
ylabel = 'Densidade')
ax.figure.set_size_inches(12, 6)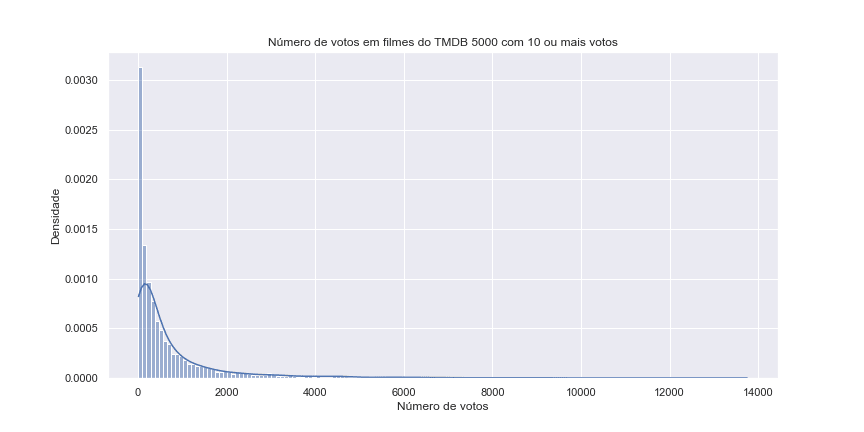
Quantas pessoas assistem os filmes? Se o filme for muito popular, muitas pessoas irão assistir, mas são poucos os filmes que são muito popular, a maior parte dos filmes pouca gente assiste, então pouca gente vota! Muitos filmes com poucos votos, e poucos filmes com muitos votos, e parece cair (lado direito) de uma maneira exponencial!
Vamos dar uma olhada no orçamento:
Observação: Como o orçamento não interfere nos votos, serão analisado todos os filmes. No dataset existem alguns filmes que estão com orçamento = 0, então, filtraremos filmes com orçamento maior que 0.
ax = sns.histplot(tmdb.query('budget > 0').budget, kde = True, stat = 'density')
ax.set(title = 'Gastos em filmes do TMDB 5000',
xlabel = 'Budget (Gastos)',
ylabel = 'Densidade')
ax.figure.set_size_inches(12, 6)
Observe que a distribuição também cai bem rápido.
Além do orçamento, temos o campo de popularidade (popularity):
ax = sns.histplot(tmdb.popularity, kde = True, stat = 'density')
ax.set(title = 'Popularidade em filmes no TMDB 5000',
xlabel = 'Popularidade',
ylabel = 'Densidade')
ax.figure.set_size_inches(20, 12)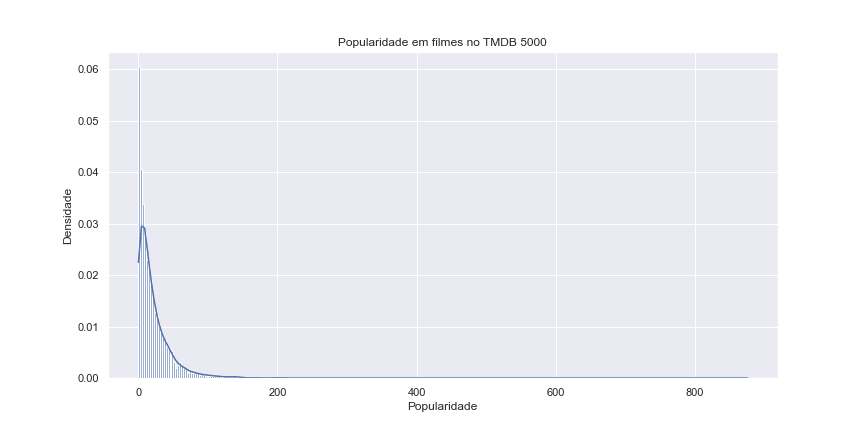
Agora, runtime (Tempo de duração de um filme).
Observação: No campo runtime, existe alguns dados NaN (Not a Number) e está tentando converter para inteiro. Diferentemente de antes onde tínhamos alguns casos estranhos de número de 0, ou para nossa análise não fazia sentido.
E para verificar se existe valores nulos usaremos a função pd.isnull() e vamos somar esses valores com a função pd.count():
tmdb.runtime.isnull().sum()Logo em seguida vamos jogar fora os valores nulos e plotar o gráfico:
ax = sns.histplot(tmdb.runtime.dropna(), kde = True, stat = 'density')
ax.set(title = 'Tempo de duração em filmes no TMDB 5000',
xlabel = 'Tempo de duração',
ylabel = 'Densidade')
ax.figure.set_size_inches(12, 6)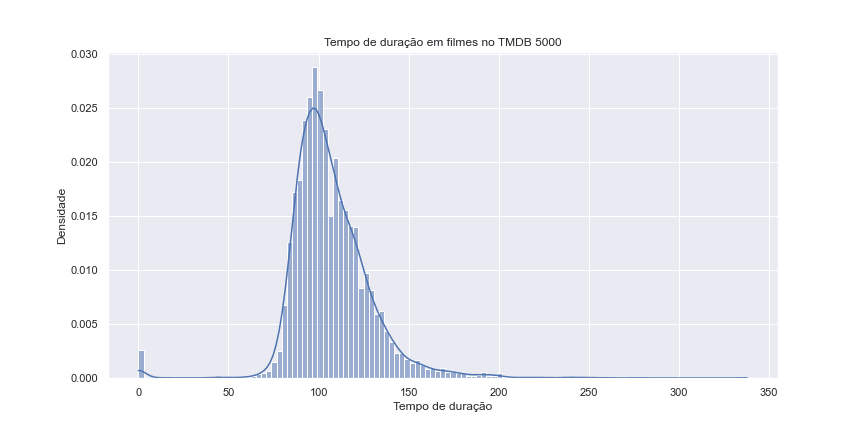
Como podemos ver, existe alguns filmes com duração igual a 0. Vamos olhar:
tmdb.query('runtime == 0')E além de jogar fora os vazios, faremos um query onde o runtime seja maior que 0:
ax = sns.histplot(tmdb.query('runtime > 0').runtime.dropna(), kde = True, stat = 'density')
ax.set(title = 'Tempo de duração em filmes no TMDB 5000',
xlabel = 'Tempo de duração',
ylabel = 'Densidade')
ax.figure.set_size_inches(12, 5)
Podemos ver de forma acumulativa:
ax = sns.histplot(tmdb.query('runtime > 0').runtime.dropna(), kde = True, stat = 'density', cumulative = True)
ax.set(title = 'Tempo de duração em filmes no TMDB 5000',
xlabel = 'Tempo de duração',
ylabel = '% de filmes')
ax.figure.set_size_inches(12, 5)
40% dos filmes que estão no conjunto de dados do TMDB tem menos do que 100 minutos de duração e 80% dos filmes, tem menos do que quantos? Isso é, os tops 20% em tempo de duração tem quantos minutos? Tem mais de duas horas, então os filmes ter mais de duas horas ocorre em 20% dos casos, olhando visualmente.
Onde está a separação dos tops 20%? Isso é o que chamamos de quantile:
tmdb.query('runtime > 0').runtime.dropna().quantile(0.8)O resultado é 121.0 minutos, muito próximo da aproximação visual.
Vamos pegar um cenário.
Supomos que ao final de um filme, uma família com 3 pessoas deram notas de 1 a 5; e ao assistirem um filme ruim, as 3 pessoas deram 1 + 1 + 1 = 3, logo, a média será 1. É importante notarmos que cada um dos registros dessa amostra não é independentes dos outros, afinal, todas essas pessoas fazem parte da mesma família, assistiram o filme juntos e deram notas imediatamente após assistirem ao filme. Portanto, esses dados são muito tendenciosos.
Imagine, então, que o Igor dá uma nota 1 a cada 5 filmes que assiste. Dessa forma, são 20% de chances de um algum filme receber uma nota 1. Já outra pessoa, também dá uma nota 1 cada 5 filmes assistidos; e outra pessoa, não relacionada, repete o mesmo padrão. Se juntarmos as suas probabilidades com as do Igor, existem aproximadamente 4 chances em 100 (4%) dos dois terem dado nota 1 a um mesmo filme. Se incluirmos também a probabilidade daquela terceira pessoa, são 8 chances em 1000 (aproximadamente 1%) de todas as pessoas do conjunto derem nota 1 ao mesmo filme. Porém, essa é uma situação movida apenas por sorte (ou, talvez, azar).
Portanto, temos que tomar cuidado não só com independência da amostra e outras características dos nossos dados, mas também com o tamanho da amostra.
Vamos começar exibindo a média dos 5 primeiros registros:
nota_media_dos_filmes_com_pelo_menos_10_votos[0:5].mean()3.5259741603585653
Podemos, então, criar um For que abranja todo o nosso conjunto:
for i in range(1, len(nota_media_dos_filmes_com_pelo_menos_10_votos)):Depois, calcularemos as médias resultantes da entrada de cada registro no conjunto - ou seja, a média do primeiro elemento, dos dois primeiros elementos, dos três primeiros elementos, e assim por diante.
for i in range(1, len(nota_media_dos_filmes_com_pelo_menos_10_votos)):
nota_media_dos_filmes_com_pelo_menos_10_votos[0:i].mean()Criaremos uma variável medias que receberá como argumento uma lista (list()). Com medias.append(), passaremos o retorno da nossa iteração para essa variável, e a exibiremos na tela:
medias = list()
for i in range(1, len(nota_media_dos_filmes_com_pelo_menos_10_votos)):
medias.append(nota_media_dos_filmes_com_pelo_menos_10_votos[0:i].mean())
mediasVamos plotar essas médias em um gráfico para que possamos analisar o seu comportamento. Para isso, importaremos o matlplotlib e passaremos medias para a função plt.plot():
import matplotlib.pyplot as plt
medias = list()
for i in range(1, len(nota_media_dos_filmes_com_pelo_menos_10_votos)):
medias.append(nota_media_dos_filmes_com_pelo_menos_10_votos[0:i].mean())
plt.plot(medias)
Perceba que, no começo, a média tem quedas e elevações constantes. Porém, em determinado momento do conjunto (por volta dos 1000 registros), a distribuição parece se estabilizar, mantendo-se quase constante.
Isso acontece pois, quando temos poucos elementos, cada novo registro no conjunto faz uma diferença bastante significante. Porém, conforme a amostra vai se tornando mais populada, os novos valores passam a interferir menos no resultado final.
Isso significa que, se tivéssemos uma amostra muito pequena, ou mal escolhida, poderíamos ter chegado a resultados diferentes e que levassem a outras interpretações a respeito desses dados. Com 580 filmes, por exemplo, temos uma média de 3.52, um valor mais alto que a média final de 3.43.
Repare também, que esses filmes estão em uma ordem super específica (ordem do dataset), e não sabemos se essa ordem tem alguma característica oculta que possa estar afetando essa distribuição. Vamos testar isso aleatorizando a ordem do nosso conjunto.
import numpy as np
np.random.seed(75243)
temp = nota_media_dos_filmes_com_pelo_menos_10_votos.sample(frac=1)
medias = [temp[0:i].mean() for i in range(1, len(temp))]
plt.plot(medias)
Dessa vez, nosso gráfico começa com valores altos, diminui bastante e então progride de maneira mais estável, tornando-se muito menos sensível à entrada de novas médias.
Vamos tentar entender, então, qual o intervalo de confiança que temos para as médias dos nossos filmes. Isso não quer dizer que todos os filmes do mundo terão uma média 3.43, que é a média dos filmes do TMDB 5000 que apresentam pelo menos 10 votos, mas queremos criar uma generalização, a partir dessa amostra, sobre os filmes que existem no mundo.
O objetivo, então, é utilizarmos o Teste Z para encontrarmos um intervalo de confiança que abrangerá não só os filmes da nossa amostra, mas também aqueles fora dela. Para isso, usaremos a função zconfint() (que se refere ao intervalo de confiança no Teste Z), passando como parâmetro os nossos dados (nota_media_dos_filmes_com_pelo_menos_10_votos). O parâmetro alpha, que é o valor de p, já é previamente configurado como 0.05 (5%).
from statsmodels.stats.weightstats import zconfint
zconfint(nota_media_dos_filmes_com_pelo_menos_10_votos)(3.4112459477469557, 3.452854733323563)
Então, dado o conjunto de dados, e acreditando que é um conjunto suficiente (uma amostra grande) para aplicar esse tipo de teste, vou ter um intervalo de confiança entre 3.41 e 3.45 para os filmes em geral, não só para a minha amostra.
Mas existem outros tipos de testes, como o Teste T, e existem diferenças primordiais entre eles. Ambos exigem algumas características na nossa distribuição ou nos nossos dados, mas, em linhas gerais, utilizamos o Teste Z quando temos um conjunto maior, e o Teste T quando esse conjunto é menor.
Como nossa amostra pode ser considerada grande, executaremos o Teste T apenas para verificarmos o resultado. Nesse caso, o processo é um pouquinho mais trabalhoso, pois teremos que descrever os nossos dados de forma estatística com o DescrStatsW.
from statsmodels.stats.weightstats import DescrStatsW
descr_todos_com_10_votos = DescrStatsW(nota_media_dos_filmes_com_pelo_menos_10_votos)
descr_todos_com_10_votos.tconfint_mean()(3.41123483922938, 3.4528658418411386)
Repare que esse intervalo de confiança é muito parecido com aquele que encontramos com o Teste Z! Claro, cada teste é utilizado em situações distintas, de acordo com a necessidade. Ainda existem diversos outros tipos de teste, que você irá conhecer se aprofundando nos estudos de estatística.
Agora, vamos analisar um filme específico no nosso conjunto - neste caso, o primeiro registro do dataset-, comparando sua média com os outros valores que obtemos. Para isso, subiremos o arquivo movies.csv e o importaremos com o Pandas. Como queremos somente o primeiro filme, faremos uma query() selecionando-o por seu movieId:
filmes = pd.read_csv("movies.csv")
filmes.query("movieId==1")
notas1 = notas.query('movieId == 1')
notas1.head()Vamos plotar esses dados em um histograma, passando para a função distplot() a nossa variável e a coluna rating:
ax = sns.histplot(notas1.rating, kde = True, stat = 'density')
ax.set(title = 'Distribuição das notas para o Toy Story',
xlabel = 'Nota',
ylabel = 'Densidade')
Como esses valores não estão distribuídos de forma contínua, plotaremos também o boxplot do conjunto:
ax = sns.boxplot(x = notas1.rating)
ax.set(title = 'Distribuição das notas para o Toy Story',
xlabel = 'Nota')
Visualmente, a mediana 4 do Toy Story já é bastante superior à mediana 3,5 que tínhamos na distribuição das notas médias dos filmes do MovieLens com 10 ou mais votos. Porém, será que essa percepção se sustenta na realidade? Afinal, pode ser que os nossos dados estejam enviesados por motivos que já apresentamos anteriormente - por exemplo, usuários de uma mesma família e que assistiram ao filme juntos terem dado as mesmas notas.
Vamos calcular a média de notas do Toy Story:
notas1.rating.mean()3.9209302325581397
Realmente, a média dos dados que coletamos é maior do que a média dos filmes com pelo menos 10 votos, que era 3.43. Mas será que essa diferença é real? Ou ela é fruto do acaso?
Para termos uma análise mais objetiva dessa média, já que temos mais de 30 registros no nosso conjunto, podemos aplicar o Teste Z:
zconfint(notas1.rating)(3.8093359183563402, 4.032524546759939)
Também podemos realizar outro teste com as nossas médias, tentando afirmar que a nota média do Toy Story na verdade é a nota média que encontramos para os filmes com pelo menos dez votos. Para isso, importaremos, do módulo Statsmodels, o ztest. Esse teste nos devolverá um pvalue que nos informará se, no mundo real, a média desse filme seria ou não igual a 3.4320503405352603 (a nota média do TMDB).
from statsmodels.stats.weightstats import ztest
ztest(notas1.rating, value = 3.4320503405352603)(8.586342305916716, 8.978190401886942e-18)
O ztest() nos devolve duas variáveis: o valor estatístico e o pvalue. Repare que este último é um valor bastante baixo, e bem menor que o nosso 0.05 (o alpha). Portanto, podemos descartar a hipótese de que, no mundo real, a média do Toy Story é igual a 3.4320503405352603 (também chamada de hipótese nula).
Nesse momento, nossa conclusão é que o filme Toy Story realmente tem uma média diferente da média de todos os filmes.
Anteriormente, nós analisamos o comportamento da média de um filme conforme novos registros eram adicionados ao conjunto. Agora, vamos repetir esse processo para o Toy Story, plotando as diversas notas desse filme.
np.random.seed(75241)
temp = notas1.sample(frac=1).rating
medias = [temp[0:i].mean() for i in range(1, len(temp))]
plt.plot(medias)
Perceba que, conforme esse conjunto vai se tornando maior, menos as novas amostras influenciam na média total - já que, visualmente, nossa distribuição se assemelha a uma normal.
Vamos analisar como isso influencia nos nossos testes, calculando o Teste Z para cada um dos valores da amostra:
def calcula_teste(i):
media = temp[0:i].mean()
stat, p = ztest(temp[0:i], value = 3.4320503405352603)
return (i, media, p)
medias = [calcula_teste(i) for i in range(2, len(temp))]
medias[(2, 4.5, 0.032687621135204896), (3, 4.0, 0.3252543510880489), (4, 3.875, 0.29952196979944745), (5, 3.9, 0.15826781784711086), (6, 3.9166666666666665, 0.07406936464331344), (7, 3.9285714285714284, 0.03058372185045264), (8, 4.0625, 0.008546846816661634), (9, 3.9444444444444446, 0.034351369792154834), (10, 3.6, 0.6797757440816464), (11, 3.590909090909091, 0.6661040559180447), (12, 3.5, 0.8452594429449549), (...)]
Agora, vamos imprimir a média, que é a segunda coluna do nosso conjunto. Para isso, transformaremos o retorno de medias em um array do numpy, e passaremos essa variável para a função plt.plot(), pegando apenas a segunda coluna (1):
medias = np.array([calcula_teste(i) for i in range(2, len(temp))])
medias
plt.plot(medias[:,1])
Como a função calcula_teste(i) está retornando outros valores além da média, mudaremos o nome da variável medias para valores. No eixo x do nosso gráfico, passaremos valores[:,0] para pegarmos o índice que figura na primeira coluna do nosso conjunto:
valores = np.array([calcula_teste(i) for i in range(2, len(temp))])
medias
plt.plot(valores[:,0],valores[:,1])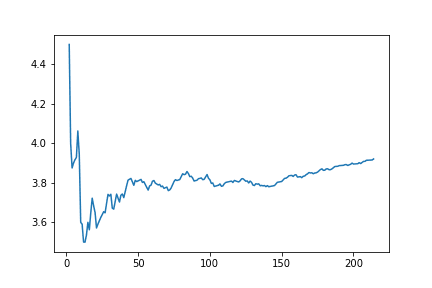
Podemos plotar também a variação do p_value:
plt.plot(valores[:,0],valores[:,1])
plt.plot(valores[:,0],valores[:,2])
Perceba que, antes de chegarmos a 50 amostras, o p value é bastante instável. Lembre-se que estamos analisando esse p value de acordo com o valor 0.05 (5%). Então, utilizaremos a função plt.hlines() para delimitarmos uma linha referencial ao longo do eixo y do nosso gráfico.
Para isso, passaremos 0.05 como valor de y; 2 como valor de xmin, len(temp) como valor de xmax; e r como valor de colors (de modo que a linha traçada seja vermelha).
plt.plot(valores[:,0],valores[:,1])
plt.plot(valores[:,0],valores[:,2])
plt.hlines(y = 0.05, xmin = 2, xmax = len(temp), colors = 'r')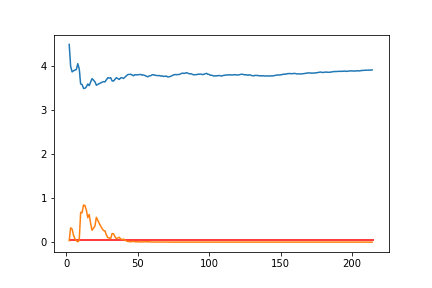
Nessa situação, poderia-se afirmar, a partir do Teste Z:
- que não há evidências para descartar a hipótese nula
- que não há dados suficientes para tirar essa conclusão
Será que é possível imprimirmos um intervalo de confiança entre duas distribuições? No caso, pegaremos a distribuição das notas do filme Toy Story e das notas de todos os filmes. Em seguida, verificaremos quão diferentes elas são:
zconfint(notas1.rating, notas.rating)(0.2799245129192442, 0.5588219849631111)
O resultado significa que a média de notas1.rating é entre 0.279 e 0.558 mais alta que notas.rating. Também podemos imprimir o p-value dessa comparação:
print (ztest(notas1.rating, notas.rating))
zconfint(notas1.rating, notas.rating)(5.894327101501841, 3.762112778881965e-09)
(0.2799245129192442, 0.5588219849631111)
Repare que o p value é menor do que 0.05. Portanto, estatisticamente, existe uma diferença significante, que está representada dentro do intervalo de confiança que calculamos anteriormente.
Também é possível fazer esse tipo de comparação como Teste T. O módulo scipy.stats possui uma função que permite realizar esse teste com dois conjuntos diferentes, chamada ttest_ind(). Para utilizá-la, basta passarmos notas.rating e notas1.rating como parâmetro:
from scipy.stats import ttest_ind
ttest_ind(notas.rating, notas1.rating)Ttest_indResult(statistic=-5.894327101501841, pvalue=3.774003138720876e-09)
Repare que nosso p value é muito parecido com o do Teste Z, já que nossas distribuições se assemelham muito a uma normal e temos um conjunto de dados bastante populado.
Com a ajuda do boxplot, podemos visualizá-las as distribuições notas1.rating e notas.rating, j´que um histograma nesse caso ficaria um pouco poluído.
import matplotlib.pyplot as plt
plt.boxplot([notas.rating, notas1.rating], labels=["Todas as notas", "Toy Story"])
plt.title("Distribuição das notas de acordo com filmes")
Visualmente, é possível percebermos que a média parece mais alta na distribuição das notas do Toy Story. Devemos nos lembrar, também, que nessa plotagem não conseguimos analisar a quantidade de elementos - um fator que é levado em consideração quando analisamos dados estatísticos.
filmes.query('movieId in [1, 593, 72226]')
Com notas.query(), vamos separar as notas de cada um desses filmes. Em seguida, passaremos essas notas para a função plt.boxplot, atribuindo as respectivas legendas:
notas1 = notas.query("movieId == 1")
notas593 = notas.query("movieId == 593")
notas72226 = notas.query("movieId == 72226")
plt.boxplot([notas1.rating, notas593.rating, notas72226.rating], labels=["Toy Story", "Silence of the Lambs,", "Fantastic Mr. Fox"])
plt.title("Distribuição das notas de acordo com filmes")
Nos boxplots gerados, já poderemos perceber, visualmente, que tanto Toy Story quanto Silence of the Lambs possuem uma mediana 4. Já o filme Fantastic Mr. Fox tem uma mediana um pouco mais elevada, mas que não conseguimos apreender a olho.
notas72226.describe()4.250000
Assim, saberemos que a mediana de Fantastic Mr. Fox é, na realidade, 4.25. Outra análise possível, a partir da nossa visualização, é que as notas de Silence of the Lambs são melhores que as do Toy Story. Porém, várias informações estão sendo desprezadas nessa análise, como a quantidade de votos que esses filmes tiveram.
Também podemos gerar um boxplot por meio do seaborn. Para isso, teremos que passar três parâmetros distintos:
data, que receberá um notas.query() com as movieId dos três filmes sendo analisados
x, que será nossa coluna movieId
y, que será nossa coluna rating
Dessa forma, o sns.boxplot() é interessante quando nossos dados podem ser facilmente separados por colunas. No caso do plt.boxplot(), temos que separar esses dados manualmente.
sns.boxplot(x = "movieId", y = "rating", data = notas.query("movieId in (1, 593, 72226)"))
Agora vamos realizar nossos testes estatísticos. A ideia é estipularmos qual desses filmes é melhor, não só nos nossos conjuntos de dados, mas também extrapolando para todas as pessoas que viram esses filmes na vida real. Para isso, usaremos o DescrStatsW(). Começaremos comparando Toy Story e Silence of the Lambs:
descr_1 = DescrStatsW(notas1.rating)
descr_593 = DescrStatsW(notas593.rating)
comparacao = descr_1.get_compare(descr_593)
comparacao.summary()coef std err t P>|t| [0.025 0.975]
subset #1 -0.2404 0.077 -3.132 0.002 -0.391 -0.090
De acordo com nossos resultados, existe uma diferença estatisticamente válida entre esses conjuntos. Como reportaríamos essa diferença? Um exemplo:
"Aplicando o Teste Z com alpha = 0.05, encontramos uma diferença estatística entre os filmes Toy Story e Silence of the Lambs, com um p-value igual a 0.02 e um intervalo de confiança entre -0.391 e -0.090".
Vamos aplicar o mesmo teste para os filmes Silence of the Lambs e Fantastic Mr. Fox. Antes de tudo, repare que, no caso do primeiro, temos um número maior de notas altas (5).
descr_72226 = DescrStatsW(notas72226.rating)
descr_593 = DescrStatsW(notas593.rating)
comparacao = descr_72226.get_compare(descr_593)
comparacao.summary()coef std err t P>|t| [0.025 0.975]
subset #1 -0.0780 0.208 -0.374 0.708 -0.488 0.332
Dessa vez, nosso p value não indica uma diferença significante (pois não é menor do que 0.05), e o intervalo inclui tanto a chance do filme ser pior, quanto a chance dele ser melhor. Repetindo esse processo, vamos comparar os filmes Toy Story e Fantastic Mr. Fox:
comparacao = descr_1.get_compare(descr_72226)
comparacao.summary()coef std err t P>|t| [0.025 0.975]
subset #1 -0.1624 0.206 -0.788 0.431 -0.568 0.243
Da mesma forma, não temos uma diferença significativa, e o intervalo também inclui aquelas duas possibilidades. Portanto, a única diferença que encontramos nos nossos dados foi entre os filmes Toy Story e Silence of the Lambs - na qual o último filme é melhor (talvez um pouco melhor, talvez razoavelmente melhor).
Agora, vamos analisar quantas notas cada um desses filmes possui:
notas.query("movieId in (1, 593, 72226)").groupby("movieId").count()
Repare que os filmes Toy Story e Silence of the Lambs possuem uma quantidade substancial de notas, enquanto Fantastic Mr. Fox possui apenas 18 notas. Por isso, é mais interessante utilizarmos o Teste T quando formos trabalhar com os dados desse filme.
Rodar o teste sem a certeza de que poderíamos utilizá-lo acabou influenciando na nossa leitura. Portanto, devemos sempre explorar os nossos dados de forma a garantir que os testes sejam executados corretamente.
Se repetirmos nossos testes com use_t=True nos momentos em que descr_72226 aparece, o p value continuará indicando que, nessa situação, a diferença não é significante. Porém, devemos sempre tomar cuidado com a maneira que atuamos na estatística.
Como é que podemos garantir que os dados das nossas notas se comportam como uma distribuição normal?
mportaremos o normaltest(), que pode receber os dados (notas1.rating) e outras características opcionais. Ele nos devolve a estatística (stats) e o p value, que no caso é o valor que estamos interessados.
from scipy.stats import normaltest
stat, p = normaltest(notas1.rating)
pTeremos um p-value de 0.00011053430732728716 - ou seja, menor do que 0.05. Como essa função testa a hipótese nula de que o conjunto de dados venha de uma distribuição normal, um resultado menor que 0.05 indica que não estamos trabalhando com uma distribuição normal.
Isso também significa que não poderíamos aplicar o Teste T ou o Teste Z, mas sim testes que funcionam com outros tipos de distribuição.
Para compararmos os conjuntos que separamos anteriormente (por exemplo, notas1 e notas593), utilizaremos a função ranksums(), que também é encontrada no módulo scipy.stats. Essa função consiste no teste Wilcoxon, que faz uma análise baseada em ranqueamento.
from scipy.stats import ranksums
_, p = ranksums(notas1.rating, notas593.rating)
p0.0003267718756440693
Nesse caso, o p-value é significativo, descartando a hipótese nula. No ranksums(), a hipótese nula é de que as duas amostras vieram da mesma distribuição. Já a hipótese alternativa, que admitiremos nesse caso (já que o p-value foi bem pequeno), é a de que os valores de uma amostra têm uma tendência a serem maiores que os da outra amostra.
Repare que, quando trabalhamos com Teste T e Teste Z estávamos nos referindo às médias - o que fazia sentido em uma distribuição normal. Porém, em uma distribuição não paramétrica, não usamos as médias, mas sim amostras aleatórias de cada conjunto testado.
Ou seja, se pegarmos notas aleatórias para Toy Story e Silence of the Lambs, as notas deste último, em geral, são maiores. Análises como essa, junto com as médias, os boxplots, os histogramas e outras informações que aprendemos a testar anteriormente, nos permitem concluir quando um filme é melhor que outro.
23