
35
Data Mesh on AWS
This article is one of series of articles on Data Lake:
In this article we provide a set of propositions to help you to apply Data Mesh principles on AWS. Alongside, we show not only theory but also a set of technical and organizational examples to help to build understanding of the concepts.
You may have heard of a Data Mesh before but do you know what stands behind this concept? In simplest words, it's a mix of DDD and microservices approaches in a context of data. Let's decouple those concepts here briefly, so that it would be easier for us to understand the principles and apply them easily.
Domain Driven design is "an approach to software development that centers the development on programming a domain model that has a rich understanding of the processes and rules of a domain" ref. The idea is simple and reaffirms Conway's law, so that it allows for modelling, building and changing systems. It ensures the solution is optimal for the business function.
When creating a system in accordance with DDD, it's necessary to be aware of the so-called Bounded Context. When moving to a project setting, you generally try to keep as few domains that are necessary to realize your goal and have systems that converge the domains. Having a small number of domains is to optimize business costs, whereas the second will help to achieve goals of DDD.
What are microservices? In simplest words it "is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API" ref. It is a design that avoids creating a single unmaintainable monolith, so that the system is able to deliver valuable features in the long run and keeps costs at bay.
How to split the functionalities in microservices approach? DDD can be helpful here. Teams can be created around domains and services can be created around the domains as well. To support the development teams, separate infrastructure teams can be established to help the teams with frameworks, libraries and infrastructure setup, so that a development team is able to quickly deliver functionalities. Having a supportive team also helps developers to take full ownership of functionalities.
Let's see now how the Data Mesh applies those practices in a realm of data with the 5 principles.
As with DDD, the data needs to be decentralized to achieve distribution of responsibility to people who are closest to it. It should be avoided to have a separate team that manages the data on S3, that has no idea what the contents of the data are. It's the team that creates the data should be managing it. If a team does not have proper capabilities to put the data, a data infrastructure team should provide them tools to do so, without having the infra team being involved in the domain.
Here we need to mention the topic of moving the data away from the services and storage. Why? There is a logical dichotomy: Data systems are about exposing data. Services are about hiding it. What does this mean? In order to build a good system, it's necessary to draw a boundary between your data and your services. You may want to decouple data and compute although it must be ensured the methods of delivery within a domain will not create any friction, that is deployments between working teams (data and apps teams) can be as independent as possible.
From a cloud perspective, domain ownership does not imply making each team have a separate account. Teams can work on a shared infrastructure as long as they bear responsibility for the data.
Have you heard the phrase Products over Projects, that software should always be treated as a product and not as a project? Software projects are popular ways of funding development although with many projects, after a while you end up with a set of incohesive systems. The same happens to your data. After a series of projects that make changes to your data that is shared with other teams, the data can often become unreadable. Imagine a Word document that had 100 pages at the beginning but after multiple years has 500 pages and you need to pass this documentation to a new development team. The amount of effort to decipher the information and amount of meetings to discuss documentation can render any future project too expensive. That's why you should treat your data as a product as well.
That's why it's important to have a metadata system in place, easily accessible to others, kept up to date and without "project specific" deviations.
A question can arise if we should use well defined data exchange models, like ones from Object Management Group, Energistics etc? Although those data models are good when setting up integrations between a high number of organizations, if used internally, that will generate friction. It is better to use data models designed specifically for business needs, even consumer packaged goods (CPG) industry can benefit from the Data Mesh.
How to make teams be able to push data to S3/Kinesis/Kafka, populate metadata in Glue Data Catalog/Atlas/Confluent Schema Registry and have time to work on their own domain? It's mandatory to have a set of managed tools, so that even teams that are not proficient in a given tech are able to provision their infra and deliver data products.
In the cloud, tools like Terraform, CDK or a self crafted set of scripts and services helps to achieve this goal.
How to ensure high interoperability of the data shared by potentially various teams of people even if they use common tools? It's necessary to enforce decisions to achieve that, otherwise you may end up in a data swamp. Definitions of what constitutes a good data quality, how security is defined or how to comply with regulations are parts of the federated governance.
Governance is always the hardest part of any system, especially if you don't want to put a lot of constraints on the teams. There are tools in place to govern the decentralized data, that can help with at least the initial setup. Example on AWS is Lake Formation.
Enterprises or large institutions would love to transform into data-driven organizations. It's a new dream that has been pursued. So the Big Data and Data Lake bring hope for enterprises and also developers for achieving those goals. However, given the structure of organization, which is usually vast and often hard to comprehend, the same Data Lake called as a saviour, becomes the bottleneck. When you think of a data lake, you might automatically think of centralization of data repository to a single source of truth. That's when our story begins.
But before that, let's assess some examples of potentially real world situations when data mesh principle might or might not be applied.
The Power United company has difficulty producing reports to their stakeholders in a timely manner. They want to be able to access the data easily and consistently. Currently, the spreadsheet is all over the place. No data repository. So they bought a big data platform and hired data engineers to bring all the data into a single repository, so that everyone can request reports and dashboards from the data engineering team. The data team will ask each data owner to provide the data and once the data is in place, they will ingest the data, create a pipeline etc. They will have proper meetings for the status update and integration between each team if there are changes. What do you think of this, is it good or bad?
In each department at Dough First, there is a data team that maintains all the data inside the unit. They have their own data analyst, scientist and engineer that work closely with the apps team inside the department. They have the proper governance inside the team. Every department has its own processes and tools. If they need data from another unit, they will set up a procedure and workflow that will be sent into another department. The data then will be exported based on the request, and then they will have their own copy for that data for their analytical purposes. If something happens, the teams organize another set of meetings to align. No shared database or whatsoever is in place as they don't want to share their production database.
Kyle the new CFO needs to learn about his company Light Corp as they will soon go public. CFO asks IT about where the data, reporting etc. Jon the CDO gives access to Kyle for the company dashboard in their data platform that gives the overview of overall performance, key performance and company metrics.
He then tries to make some analysis and needs some more data. Jon teaches him how to search the data sets in a data platform so that he can find the data easily. The data also have a quality score, freshness and data is well documented on the platform.
Kyle finds some interesting anomaly and needs to get more data on the found case. He then requests additional data from the owner on the data platform and has the request responded instantaneously, without a meeting to ask for the proper access level and clearance. Every request is done and approved from the platform.
Kyle finally can visualize the data in the platform easily. In the first weekly management meeting, everyone just opens the dashboard without using PowerPoint and they are able to understand what's happening and what's next based on looking at the dashboard. They are also able to drill down and conduct interesting discussions based on their findings.
After the first executive meeting, Kyle found some interesting anomalies in their pricing model. Seems that it can be improved for targeting the specific customer for the experience and brand loyalty. He asks Jon for a brainstorming session, they invite their peers and data owner into a call.
They discuss what data product that can be used for this internally. They find the right data in the dashboard and create a simple visualization and analytics based on tools provided by the data infra team. They found out that some customer pricing can be improved. They also find new clusters that can be reached with a different product. They didn't expect to find out new findings while doing something that was totally unrelated.
So which company do you prefer to work with? Power, Dough or Light? You might prefer Light Corp among those.
With the promise of data lake, businesses now want to get benefits from Big Data and get the return of investment. Everyone wants a new dashboard, use case and heaven forbids realtime analytics. Nevertheless, the data team is still small, young and the skills are not there yet, people still learn, the talent is not available in the market. As a result the Data Engineering team can't keep up with new data sources, new data consumers and new demand from business that has been promised from the big investment on infrastructure. They want results. And they needed it yesterday. It's not the technology that becomes the bottleneck. It's human. It's become costly because the pipeline is slow.
Data Lake has been pretty in theory but practice proved otherwise. It's difficult to process without proper governance. It's difficult to access data that is not well structured as used before. The data gets duplicated, the coordination between the team is lacking and another silos is created. It's like a town without rules.
We forget the basic principles of software design like encapsulation, modularity, loose coupling, high cohesion and divide and conquer. We couple the well defined contextes between departments. We bring the data into a single data store, then try to understand all of that from the perspective of a tiny data department that doesn't know the behaviour of the data. Of course, they will try to learn from the source system expert but everyone has their own job and becomes their last priority for that day. Who loves endless meetings to explain their system to other departments over and over again? It might be OK for just 1 source system, but mid size organizations have hundreds of systems. Each system contains multiple databases. And you know the rest with tables and fields, right? Where do we start then? It's a huge web of interconnected systems that has a long history.
The system might be bought or built by a different vendor or outsourcing company or created in house. The behaviour of users, vendor delivery methods, architecture can differ as well. On top of that, each product has different data lifecycle. Even people inside the department might not be able to understand all the data within their apps and where it's stored. The knowledge of business and technical knowledge also have a huge variance. How come a single data department that consists of only 10 people would be able to cope with that. Not to forget anything can happen in production in the middle of the night.
Every tool gets bored and dies every once a whole but in the end, only the concepts and fundamentals matter. We still need a proper design, even in the data space. People forget that it's still applied regardless of the domain. We create a great microservice architecture but at the end we are trying to join everything again into one big giant data monolith that is hard to use and understand.
As engineers, we get paid to solve business or society problems with technology. Let's not create a problem by inappropriate use of technology. Great weapons in the hands of wrong people can bring chaos. We need to get back into the basics and fundamentals once again. It's a business that we as engineers need to understand better, how they operate and how to remove friction and increase collaboration to bring down walls that create silos structure. That brings us once again into the Domain Driven Design concept by collaborating with business to increase agility in the whole organization.
So what we know is that currently we struggle with data explosion with unmanageable structure and lack of proper governance and lack of team capacity, knowledge and man power. How can we do this differently? Why not go back to basics and remove the pains? We need to honour the bounded context and create a proper collaboration with the business. We might have one data platform but we can always create proper boundaries, so that each team will have their own data product inside the service boundary. Clean separation between services is still happening not only in application/service level but also data level. Encapsulation everyone?
Having said what constitutes a good data mesh, let's try to give some starting point cases and how a good architecture can be built.
Since this is a green field project, it's the easiest one you can imagine. You may not have much constraints in place on how the platform should be built, so you can try to build it in a way, so that will he highly efficient even if it grows big.
There is a high number of services and tools available on AWS are versatile and allow for advanced functionalities like data anonymization or ACID transactions.
Let's see how we can implement a good Data Mesh on AWS. Diagram below shows an example of this approach.
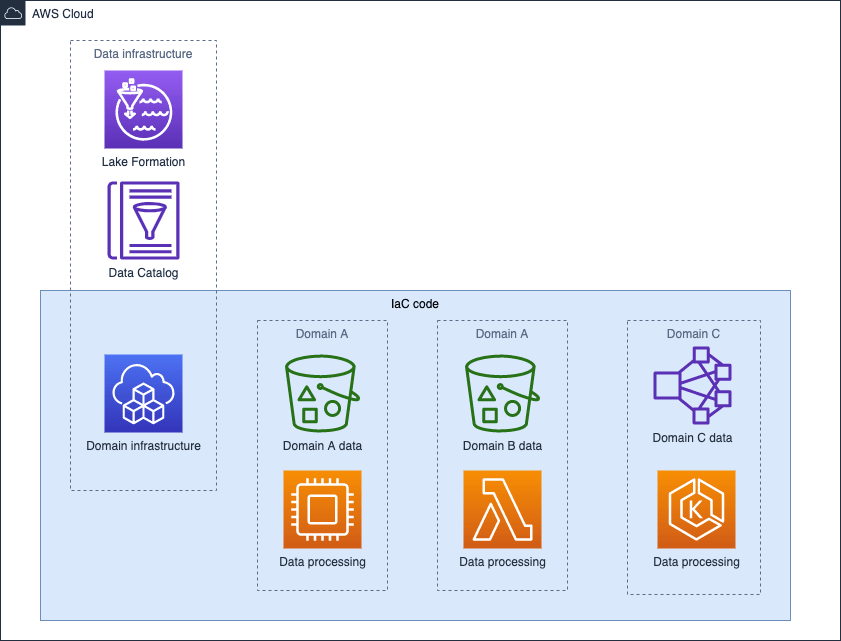
We can distinguish two main groups there:
What AWS service should be used to help satisfy each Data Mesh principle? What OSS alternatives can be used on AWS cloud since as we know, OSS presence here is dominant? Below is a short, not exhaustive list of options:
| Data Mesh Principle | AWS service/tool | OSS alternative |
|---|---|---|
| Domain Ownership | S3 | lakeFS, Delta Lake |
| Data as a product | Glue | Project Nessie, Apache Atlas, Hive Metastore, Apache Iceberg |
| Self-serve data platform | CloudFormation, CDK, Amazon Managed Workflows for Apache Airflow, EKS, EMR, QuickSight | Terraform, K8S, Rancher, jupyter, Kibana |
| Federated computational governance | Lake Formation, Organizations | Apache Atlas |
At a bare minimum, you should have at the start one person that has knowledge of Cloud system engineer and one data engineer. In enterprise settings, you should consider having Cloud Center of Excellence (CCOE).
Remember the company partners Power United in our story before? Let's continue using that one.
They have 2 hard-working people in the company Jackie (Cloud Administrator) and Alex (Data Engineer Lead) from centralized Analytics and Data-warehouse department. They've been assigned to create a new initiative for a new data analytics platform in AWS.
Currently, in the company, there are multiple squads that handle domain microservices like billing, finance, inventory, shipping etc. Luckily, they already have their own domain and microservices.
Let's see how it works.
This is a more complex case. There already is an analytical system in place and you discover that there are noticeable bottlenecks that slow the company down. You could have already invested heavily in products like Cloudera or other data monoliths, so you need to apply a sliced approach.
How to solve the bottlenecks? Apply data mesh principles in order to remove unnecessary bottlenecks. You can split your data lake like a monolith server/service. Find the domains, define the boundaries and build the data around the domain thoughtfully. Diagram below visualizes this approach:
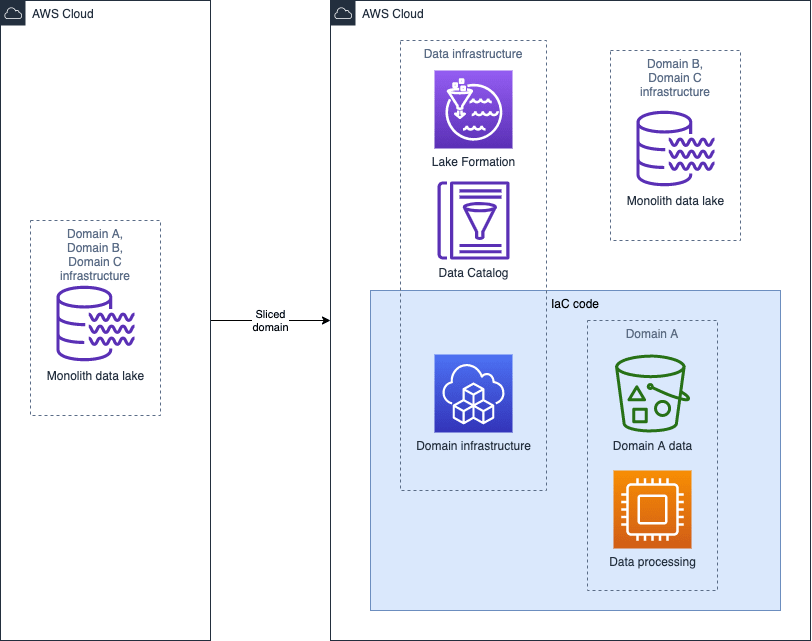
Once done, you can keep slicing the monolith until the monolith can be decommissioned.
Even though the case above is common, that is not always a problem. There are situations when there is a separate team that manages the data and a separate one that is providing the data. How to resolve this issue? You need to bring up the data ownership topic. Ideally, the team that manages the data needs to transition to a data infra team and support ones that are actually working on data.
Diagram below shows how a problem with a lack of ownership can be resolved. The data team needs to focus on providing a domain infrastructure IaC, so that the team responsible for Domain can be also responsible for the data.
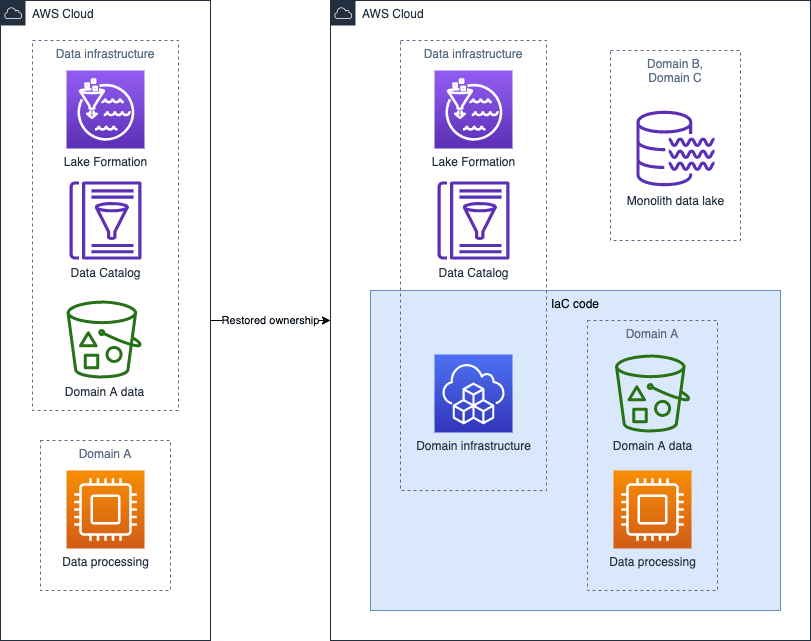
What if you have an existing platform and want to scale it, that is to add a new team? The team will take time to get up to speed to deliver the value. Shared self service tools (data discovery/catalog/schema) and shared infra can speed them up. If you grow the number of teams that work on the data, you should invest into the self-serve data platform, to ensure high performance of the new teams.
Scaling of a data mesh within an AWS account is a relatively easy task although it is not a case at an enterprise. An enterprise can make use of hundreds of AWS accounts and in order to handle this usual case, a proper approach must be defined.
From an approach of data governance, two design types can be distinguished:
Because the decentralized design type allows for more organizational configurations to be implemented, let's consider below a case with this design.
Domain A and Domain B resides in an AWS account OU A, with its own Lake Formation and Glue Catalog. What we want to have, is to enable Domain C to access the data in other domains. Domain C resides in OU B account, also with its own Lake Formation and Glue Catalog. To deliver this task, we need to make use of AWS RAM and share Glue resources between accounts.
Diagram below shows how this can be realized.
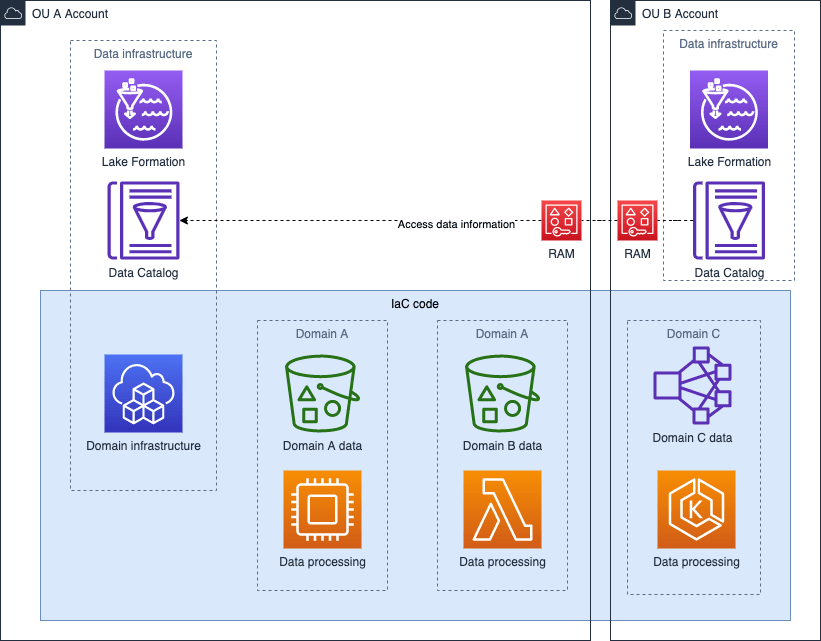
All the above cases consider a simple case, where there is only one provider and there is no data on-premise. That's not always the case, there are organizations applying hybrid cloud approach, multi cloud approach or both, hybrid and multi cloud. Designing an interoperable system that would accommodate such a setup can be challenging, most because of vendor lock-in.
As usual, it's best to either look at OSS offerings or write your own solutions that would help. An example of a self written platform is Airbnb and their Minerva platform, that is vendor independent.
The whole topic is very extensive although the general rules of a data mesh still apply, with prevailing domain ownership. The premise of a self-serve data platform can be challenging as it is hard to provide tools that would work across a versatile portfolio of platforms at a reasonable cost. Definitely suggestions provided in Cloud Strategy are helpful to craft the best possible data mesh for the organization.
At this step, it's worth distinguishing fintech companies from other sectors because of their special characteristics. The nature of fintech companies is that they are able to process information effectively. Moreover, most of the capital market professionals believe that data analysis will be the most important skill at trading desks in the near future ref. To remain competitive, a further adjustment towards better tools for data analysis at companies providing Financial Services is necessary.
Each organization may generate 20 to 400 GB of data from stock exchanges per day, if we exclude high-frequency trading (HFT). To create proper data models, an analyst may need about 20 years of data, which means there is a need for PBs storage and high processing capacity. Assuming that, an extensive platform for this purpose is necessary.
One approach might be to leverage basic managed services and build a platform that conforms to requirements but it is also possible to make use of a managed service specifically designed for fintech, Amazon FinSpace. It allows for configuration of environments where a set of data and users who can operate on the data can be configured. Once the environment is added and data feeds are configured for the purposes of an analyst, it's possible to begin processing even PBs of data.
How can Amazon FinSpace be leveraged to support Data Mesh paradigms? Finspace can be treated as a tool for a single Domain. That can be a proper tool for end users to rely on data provided by other Domains.
Organizations strive to be data driven but how can this be done well and to ensure the data flows can be setup well at various units effectively? We hope that after reading this article, you will have a better overview on the general rules and concrete realizations on AWS you should follow to achieve that.
Software and cloud architect with about 10 years of experience, Developer Consultant at ThoughtWorks, helping clients achieving their goals. After work, OSS contributor and a self-taught aroid plant grower.
Co-founder and CTO at Scifin Technologies (Crypto Derivatives HFT firm). Doing distributed system and real-time streaming analytics for about 15 years in O&G, Banking, Finance and Startups.
35