
27
Scrape Bing Organic Search with Python
Contents: intro, imports, what will be scraped, code, links, outro.
In this blog post you'll see how to scrape title, link, displayed link, and a description from Bing organic search results.
from bs4 import BeautifulSoup
import requests
import lxmlEverything will be shown on the following container
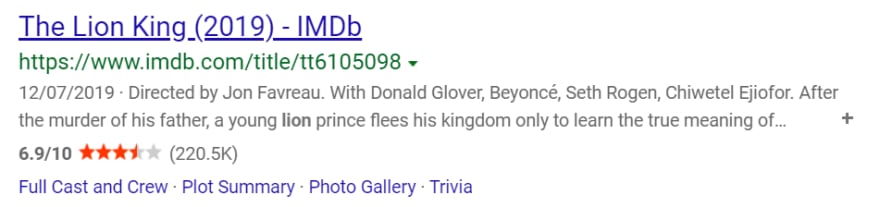
Title, link

Displayed link

Description (snippet)

Inline links

You might see a lot of
try/expect blocks here because not every element has certain data. For example not every container has inline links, so we need to make an exception for it to handle.from bs4 import BeautifulSoup
import requests, lxml
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
html = requests.get('https://www.bing.com/search?q=lion king&hl=en', headers=headers).text
soup = BeautifulSoup(html, 'lxml')
for result in soup.select('.b_algo'):
try:
title = result.select_one('.b_algo h2 a').text
except:
title = None
try:
link = result.select_one('.b_algo h2 a')['href']
except:
link = None
try:
displayed_link = result.select_one('.b_caption cite').text
except:
displayed_link = None
try:
snippet = result.select_one('#b_results p').text
except:
snippet = None
try:
for inline in result.select('.sa_uc a'):
inline_title = inline.text
inline_link = inline['href']
print(f'{inline_title}\n{inline_link}')
except:
inline_title = None
inline_link = None
print(f'\n{title}\n{link}\n{displayed_link}\n{snippet}\n')
# part of the output:
'''
# inline links
Full Cast and Crew
https://www.imdb.com/title/tt6105098/fullcredits
Plot Summary
https://www.imdb.com/title/tt6105098/plotsummary
# organic results
The Lion King (2019) - IMDb
https://www.imdb.com/title/tt6105098/
https://www.imdb.com/title/tt6105098
12/07/2019 · Directed by Jon Favreau. With Donald Glover, Beyoncé, Seth Rogen, Chiwetel Ejiofor. After the murder of his father, a young lion prince flees his kingdom only to learn the true meaning of responsibility and bravery.
Full Cast and Crew
https://www.imdb.com/title/tt6105098/fullcredits
'''
Using Bing Organic Results API
from serpapi import GoogleSearch
params = {
"api_key": "YOUR_API_KEY",
"engine": "bing",
"q": "lion king"
}
search = GoogleSearch(params)
results = search.get_dict()
for result in results['organic_results']:
title = result['title']
link = result['link']
displayed_link = result['displayed_link']
snippet = result['snippet']
try:
inline_links = result['sitelinks']['inline']
except:
inline_links = None
print(f'{title}\n{link}\n{displayed_link}\n{snippet}\n{inline_links}\n')
# part of the output:
'''
Disney THE LION KING | Award-Winning Best Musical
https://www.lionking.com/
https://www.lionking.com
Disney's official site for tickets to the landmark Broadway musical THE LION KING in New York City and on tour across North America. Get information, photos and videos.
[{'title': 'Cast & Creative', 'link': 'https://www.lionking.com/cast'}, {'title': 'Get Tickets', 'link': 'https://www.lionking.com/tickets'}, {'title': 'About', 'link': 'https://www.lionking.com/about'}, {'title': 'FAQ', 'link': 'https://www.lionking.com/faq'}, {'title': 'Worldwide', 'link': 'https://www.lionking.com/worldwide'}, {'title': 'Gazelle Tour', 'link': 'https://www.lionking.com/tour'}]
'''If you have any questions or something isn't working correctly or you want to write something else, feel free to drop a comment in the comment section or via Twitter at @serp_api.
Yours,
Dimitry, and the rest of SerpApi Team.
Dimitry, and the rest of SerpApi Team.
27