
26
Data Replication for DBMS using the Commit Log

In this article, we will see how developers can break down information silos for their teams and business by replicating data across multiple systems. First we will review why developers will replicate data and considerations for the cloud. Second, we will prepare for war with the replicators. Then we will examine the architecture of Postgres and MySQL and how their commit logs enable us to make exact copies of the data. Finally, we will connect Debezium to Postgres for a complete data replication solution.
Data replication is the process of moving data between different database systems for various business use cases. In a typical SaaS (Software As A Service) application, data is stored in an operational database such as MySQL, PostgreSQL, Oracle, etc. There are other database systems such as data warehouses and search systems built for specialized use cases. Moving data between these systems is known as data replication.
Note: Data replication between the same database systems is done for availability and should not be confused with the data replication being discussed in this article.
Information silos are one of the biggest impediments for businesses to unlock value from their data and protect their assets.
Depending on the underlying architecture, enabling democratized access to data can be very challenging. Cloud computing has evolved so much in the past decades that even some massive companies managing their own data centers have moved to the cloud. Cloud-native architectures such as data pipelines, data lakes, data warehouses, and fully managed data systems are common. No company wants to spend money on the maintenance of rudimentary systems but rather on building its core business. Saving a few dollars by hosting their own infrastructure (on-premise) is no longer lucrative. With that said, there are a different set of challenges that come with the cloud, such as
Regardless of the underlying architecture, i.e., whether it is cloud or on-premise, one can choose abstract designs so that they can be easily moved across and even be hybrid.

We are going to focus exclusively on the first part, i.e., the replication in this article. This layer is the key to enabling further layers for business.
Before we dive into solutions, we need to understand how replication works with standard operational databases (relational databases).
Relational database systems maintain something called a commit log (in PostgreSQL, it is called a Write Ahead Log or WAL log). These commit logs are written whenever a database transaction commit happens. Regardless of the database we use, almost all database logs have the following properties,
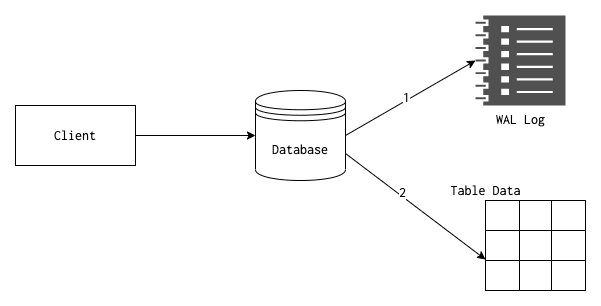
The logging architecture of relational database systems is one of the oldest and one of the most battle-tested engineering ideas that we have today. Many newer systems drew their ideas and inspiration from them. Why such a logging system exists?
These properties help us to establish a solid base upon which further systems are built.
MySQL's architecture is very similar to PostgreSQL, but the WAL log of PostgreSQL combines both InnoDB's transaction log and binary log. Since MySQL implements multiple storage engines, the usage is segregated into different logs. The storage engine part is not within the scope of this article, so I will stick to PostgreSQL examples henceforth.
WAL file is actually a binary file and is located in the
pg_wal directory of your PostgreSQL installation. A typical directory structure is shown below.When we try to see the content, it will be something like below,

PostgreSQL provides a facility called
pg_waldump to read these files. We can use pg_waldump /path/to/wal/file and it will decode the entire file into human-readable text. An excerpt from the text is provided below.rmgr: Btree len (rec/tot): 80/ 80, tx: 564, lsn: 0/2F106698, prev 0/2F1065E8, desc: INSERT_LEAF off 41, blkref #0: rel 1663/16385/2658 blk 16
rmgr: Btree len (rec/tot): 64/ 64, tx: 564, lsn: 0/2F1066E8, prev 0/2F106698, desc: INSERT_LEAF off 292, blkref #0: rel 1663/16385/2659 blk 10
rmgr: Heap len (rec/tot): 175/ 175, tx: 564, lsn: 0/2F106728, prev 0/2F1066E8, desc: INSERT off 43 flags 0x00, blkref #0: rel 1663/16385/1249 blk 56
rmgr: Btree len (rec/tot): 72/ 72, tx: 564, lsn: 0/2F1067D8, prev 0/2F106728, desc: INSERT_LEAF off 41, blkref #0: rel 1663/16385/2658 blk 16
rmgr: Btree len (rec/tot): 64/ 64, tx: 564, lsn: 0/2F106820, prev 0/2F1067D8, desc: INSERT_LEAF off 293, blkref #0: rel 1663/16385/2659 blk 10
rmgr: Heap len (rec/tot): 175/ 175, tx: 564, lsn: 0/2F106860, prev 0/2F106820, desc: INSERT off 44 flags 0x00, blkref #0: rel 1663/16385/1249 blk 56
rmgr: Btree len (rec/tot): 72/ 72, tx: 564, lsn: 0/2F106910, prev 0/2F106860, desc: INSERT_LEAF off 47, blkref #0: rel 1663/16385/2658 blk 16
rmgr: Btree len (rec/tot): 64/ 64, tx: 564, lsn: 0/2F106958, prev 0/2F106910, desc: INSERT_LEAF off 294, blkref #0: rel 1663/16385/2659 blk 10
rmgr: Heap len (rec/tot): 175/ 175, tx: 564, lsn: 0/2F106998, prev 0/2F106958, desc: INSERT off 45 flags 0x00, blkref #0: rel 1663/16385/1249 blk 56
rmgr: Btree len (rec/tot): 80/ 80, tx: 564, lsn: 0/2F106A48, prev 0/2F106998, desc: INSERT_LEAF off 42, blkref #0: rel 1663/16385/2658 blk 16So far, we have seen things in an abstract fashion. We started from why companies need to unlock the full potential of their database, which leads to data replication and data platforms. To understand how replication works, further sections of this article will focus on a specific database platform, PostgreSQL. Most of the concepts are similar for other database systems as well, so this can be used as a reference to form a mental framework around database replication itself.
We saw how WAL enables the database to maintain data integrity, consistency in case of system shutdowns, and even rolling back from data corruption. Like many other systems out there, PostgreSQL also evolved from the ground up, and as such, we need to understand how replication works within two nodes of the same database and how we can extend that to other data systems. Regardless of whatever replication mechanism we discuss below, it relies upon the WAL for replication.
Physical replication has been existing in PostgreSQL for quite a while. It is used to replicate the whole of the database by physical copy or byte-to-byte copy. Any change made to the main database is also reflected in the replica database without any changes. The replica can choose to be a hot standby node (i.e., the main database fails, and the replica takes over as the main/master).
There are several ways of physical replication, such as log shipping, streaming replication, etc., but they can largely be classified into two categories.
There are several restrictions for this type of replication, such as the listening database should also be in the same major version; partial content cannot be replicated; and so on. For these reasons, physical replication is typically used to sync data between two PostgreSQL database systems, mainly for high availability reasons.
Before version 10 (shown below), other options allowed developers/engineers to replicate without logical replication to other downstream systems. As the name suggests, logical decoding decodes the WAL content into a human-readable format and replicates it to different consumers. There are both advantages and disadvantages to this approach. Still, since this step requires plugins/installations in the host database system, it is often difficult to maintain, particularly in cloud environments.
Starting from PostgreSQL version 10, logical replication is available to replicate data from PostgreSQL databases. As mentioned in the documentation, logical replication is based on a publish-subscribe model. One or more subscribers can choose to listen to the published data and publish and subscribe only to specific databases/tables.
It is clear that logical replication was targeted more towards replicating to other data systems such as a messaging system, data lakes, and data warehouses. It is much easier to also listen from multiple databases as well. We will choose an open-source tool called Debezium to build our replication pipeline.
In this section, we will see a demo on how to use Debezium for the Change Data Capture (CDC) happening in our PostgreSQL source database. We will use Docker to quickly set up the database and debezium connector to listen to the changes.
We wrote a full detailed tutorial on setting up Debezium and Postgres using Docker. The most important parts are described below but please see the link above for all the details!
Before we activate Debezium, we need to prepare Postgres by making some configuration changes. Debezium utilizes the WAL that we described above. Postgres uses this log to ensure data integrity and manage row versions and transactions. Postgres' WAL has several modes you can configure it to, and for Debezium to work, the WAL level must be set to
replica. Let's change that now.psql> alter system set wal_level to 'replica';You may need to restart the Postgres container for this change to take effect.
There is one Postgres plugin not included with the image we used that we will need:
wal2json. Debezium can work with either wal2json or protobuf. For this tutorial, we will use wal2json. As its name implies, it converts Postgres' write-ahead logs to JSON format.With our Docker app running, let's manually install wal2json using aptitude. To get to the shell of the Postgres container, first find the container ID and then run the following command to open bash:
$ docker ps
CONTAINER ID IMAGE
c429f6d35017 debezium/connect
7d908378d1cf debezium/kafka
cc3b1f05e552 debezium/zookeeper
4a10f43aad19 postgres:latest
$ docker exec -ti 4a10f43aad19 bashNow that we're inside the container, let's install wal2json:
$ apt-get update && apt-get install postgresql-13-wal2jsonWe're ready to activate Debezium!
We can communicate with Debezium by making HTTP requests to it. We need to make a POST request whose data is a configuration in JSON format. This JSON defines the parameters of the connector we're attempting to create. We'll put the configuration JSON into a file and then use
curl to send it to Debezium.You have several configuration options at this point. This is where you can use a whitelist or blacklist if you only want Debezium to stream certain tables (or avoid certain tables).
$ echo '
{
"name": "arctype-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"plugin.name": "wal2json",
"database.hostname": "db",
"database.port": "5432",
"database.user": "postgres",
"database.password": "arctype",
"database.dbname": "postgres",
"database.server.name": "ARCTYPE",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"snapshot.mode": "always"
}
}
' > debezium.jsonNow we can send this configuration to Debezium.
$ curl -i -X POST \
-H "Accept:application/json" \
-H "Content-Type:application/json" \
127.0.0.1:8083/connectors/ \
--data "@debezium.json"The response will be a JSON representation of the newly initiated connector.
{
"name": "arctype-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"plugin.name": "wal2json",
"database.hostname": "db",
"database.port": "5432",
"database.user": "postgres",
"database.password": "arctype",
"database.dbname": "postgres",
"database.server.name": "ARCTYPE",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"snapshot.mode": "always",
"name": "arctype-connector"
},
"tasks": [],
"type": "source"
}It is important to understand that once we are using Debezium and listening through the logs, we have left the realm of relational databases with ACID guarantees and into the world of distributed systems. With our choice as Kafka for the messaging system, the semantics it follows decides how we replicate/distribute data to further downstream systems.

The third message delivery mechanism is incredibly hard to solve in a distributed system. Kafka is one among the systems that has solved this at scale, but each has its own drawbacks regarding throughput, scale, and accuracy. One must make an informed choice to balance out what is necessary.
As a business expands, the need to ethically leverage data is not a luxury anymore but a necessity. Data platforms are becoming increasingly common even across mid-sized businesses. They enable,
There has never been a better time to unlock the value of data.
26