
30
Evolution of a data system
The holy grail of data work is putting data science into production. But without an extensive data engineering background, you might not know how to build a production data system. In this post, I'll show how you can turn a machine learning model into a production data app by laying out the high-level system design of a simple Reddit analytics tool.
Reddit is a serious place for serious people, but sometimes subreddits become corrupted by miscreants who spread useless banter. To avoid such unpleasantries, we want to build a web app that can advise us of the seriousness of different subreddits.
For our project, we’ll use machine learning to score the seriousness of every individual Reddit post. We’ll aggregate the scores by subreddit and time, and we’ll expose the insights via an API that we can integrate with a frontend. We want our insights to update in near real-time so we’re reasonably up-to-date with the latest posts.
So we’re clear on what the system should do, here’s the API interface:
/subreddit/[name]: Returns a) a subreddit’s posts and their seriousness scores, b) an all-time seriousness score, and c) hourly seriousness scores for the last week/subreddits: Returns all subreddits we track and the all-time seriousness score for eachLet’s dive in.
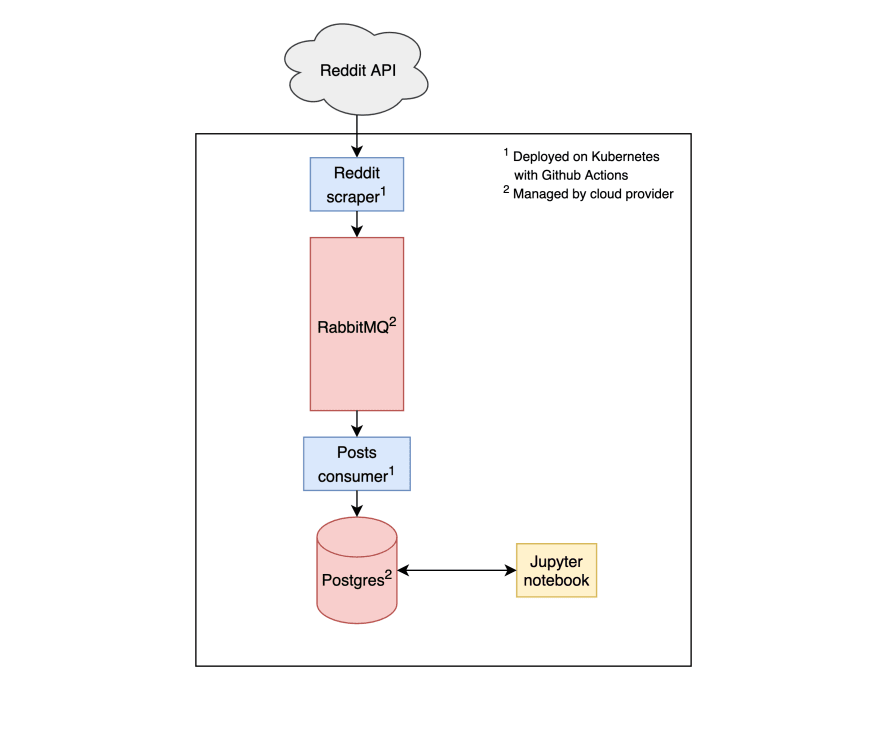
To start, we want to extract posts from Reddit and write it into our own storage system. Our storage system will have two components: a message queue and a database.
With our storage system in place (in theory), let’s write the first scripts of our data pipeline.
posts topic in our message queue.posts consumer: This script reads data from the posts topic and inserts it into our Postgres database.We need a way to deploy and run our code in production. We like to do that with a CI/CD pipeline and a Kubernetes cluster.
We’ll use a cloud provider to provision the message queue, database and Kubernetes cluster. We prefer managed services when they’re available, so we won’t deploy the message queue or database directly on Kubernetes.
Here’s a diagram of what our system looks like so far:

Once all this is up and running, we need to validate that the data is flowing. An easy way to do that is to connect to our Postgres database and run a few SQL queries to check that new posts are continually added. When everything looks good, we’re ready to move on.
Now that we have the raw data in Postgres, we’re ready to develop our moneymaker, the seriousness scoring model. For this example, we’ll keep things simple and use a Jupyter notebook that pulls historical posts from the Postgres database.
Note that there are other ways to train a machine learning model. Fancy “MLaaS'' and “MLOps” tools can help you continuously train, monitor and deploy models. If you want to integrate with one of these tools, you’ll likely connect your database to enable training, and you’ll ping an API to make an inference.
Here’s our system augmented with our ML development environment:
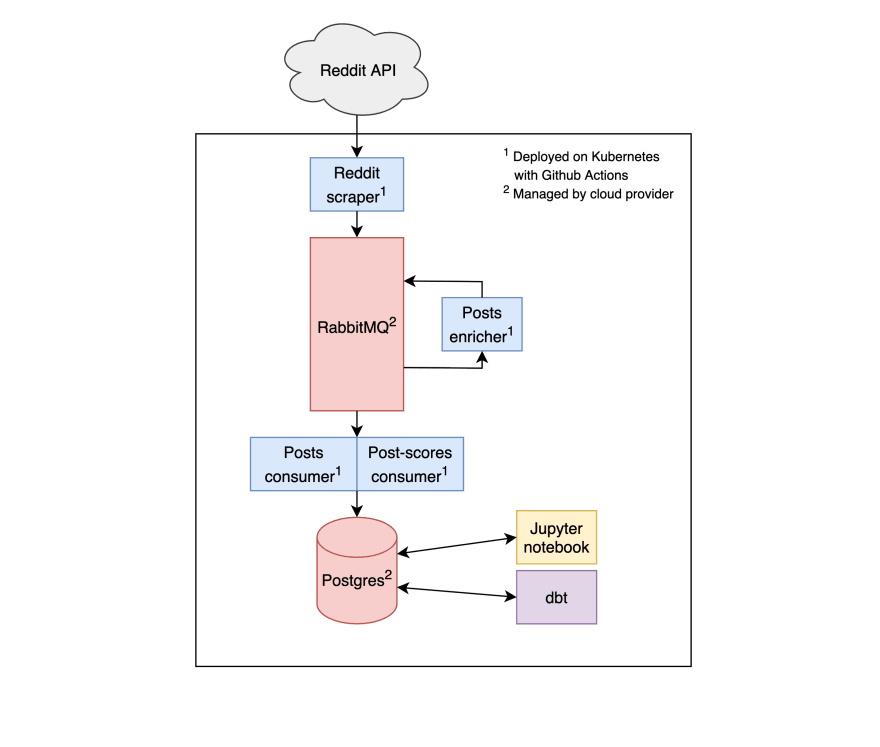
Now it’s time to build the workers that will apply the model to new posts, and write out the resulting seriousness scores. That’s two different scripts:
posts enrichment. This script consumes the Reddit posts topic, applies the predictive model, and writes the data back to another topic posts-scores, which will contain post IDs and seriousness scores.post-scores consumer. This script reads data from the posts-scores topic and inserts them into (a separate table in) our Postgres database.Next up, we want to aggregate our results by subreddit and time. We’ll use dbt, which allows us to schedule periodic SQL queries. We’ll schedule two aggregating queries:
subreddit-scores-5min in Postgres.subreddit-scores-total.With that, we have all the data that we want for our app available in Postgres. Here’s what the system looks like now:
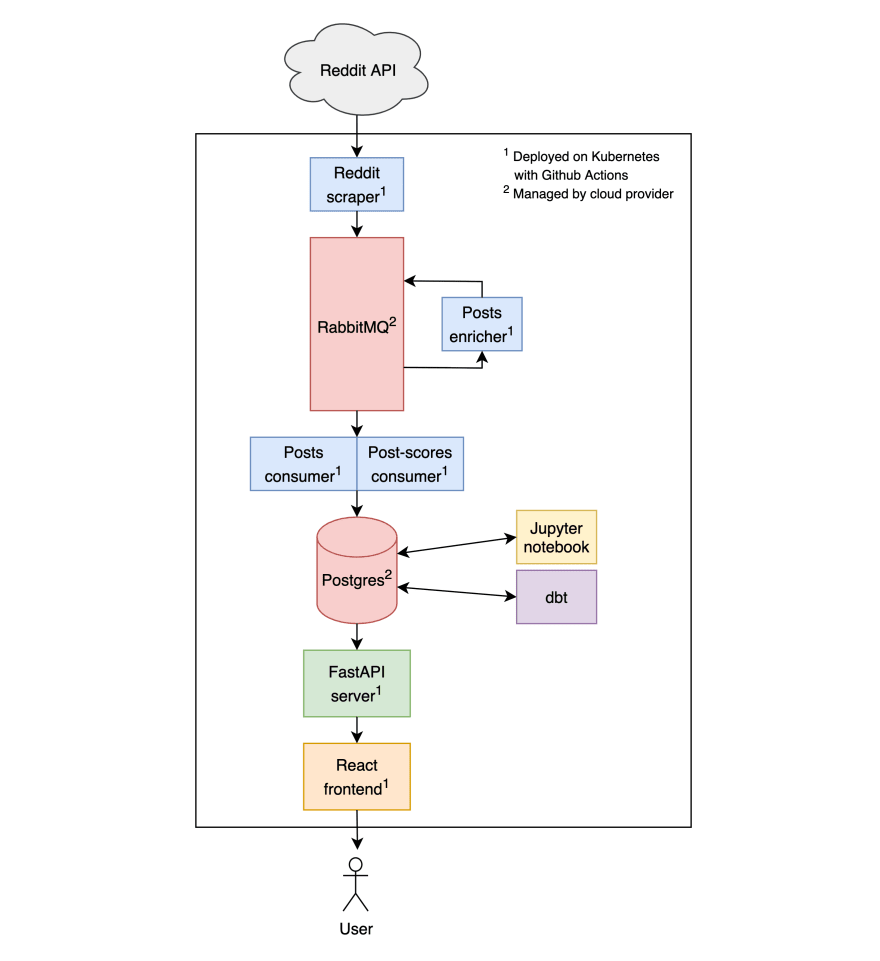
Our last step is creating the interfaces for accessing our Reddit insights. We need to set up a backend API server and write our frontend code.
API server. The API server will fetch the insights from Postgres and serve the results to the frontend. It’ll implement the routes we specified in the introduction. We’ll build the API server in Python using the FastAPI framework.
Frontend client. The frontend will contain tables and charts for viewing and searching the insights. We’ll implement it with React and use a fancy charting library like Recharts.
Deploy the API server and frontend code to Kubernetes, and we have ourselves a full stack analytics application! Here’s what the final design looks like:
Our Reddit analytics app is now ready to share with the world (at least on paper). We’ve set up a full stack that spans data ingest, model training, real-time predictions and aggregations, and a frontend to explore the results. It’s also a reasonably future proof setup. We can do more real-time enrichment thanks to the message queue, and we can do more aggregations thanks to dbt.
But the system does have its limitations. For scalability, we’re limited by the throughput of Postgres and RabbitMQ. For latency, we’re limited by the batched nature of dbt. To improve, we could add BigQuery as a data warehouse, use Kafka as our message queue, and add Flink as a real-time stream processor, but these powerful systems also come at the cost of greater complexity.
While there are always different tools you can use for the same job, this data system design is fairly standard. I hope it gives you perspective on what it takes to build a live analytics-centric web application.
30