
26
Netflix System Design- Backend Architecture
Cover Photo by Alexander Shatov on Unsplash
Netflix accounts for about 15% of the world's internet bandwidth traffic. Serving over 6 billion hours of content per month, globally, to nearly every country in the world. Building a robust, highly scalable, reliable, and efficient backend system is no small engineering feat but the ambitious team at Netflix has proven that problems exist to be solved.
This article provides an analysis of the Netflix system architecture as researched from online sources. Section 1 will provide a simplified overview of the Netflix system. Section 2 is an overview of the backend architecture and section 3 provides a detailed look at the individual system components.
Netflix operates in two clouds Amazon Web Services and Open Connect(Netflix content delivery network).
The overall Netflix system consists of three main parts.
Open Connect Appliances(OCA) - Open Connect is Netflix’s custom global content delivery network(CDN). These OCAs servers are placed inside internet service providers (ISPs) and internet exchange locations (IXPs) networks around the world to deliver Netflix content to users.
Client - A client is any device from which you play the video from Netflix. This consists of all the applications that interface with the Netflix servers.
Netflix supports a lot of different devices including smart TV, Android, iOS platforms, gaming consoles, etc. All these apps are written using platform-specific code. Netflix web app is written using reactJS which was influenced by several factors some of which include startup speed, runtime performance, and modularity.
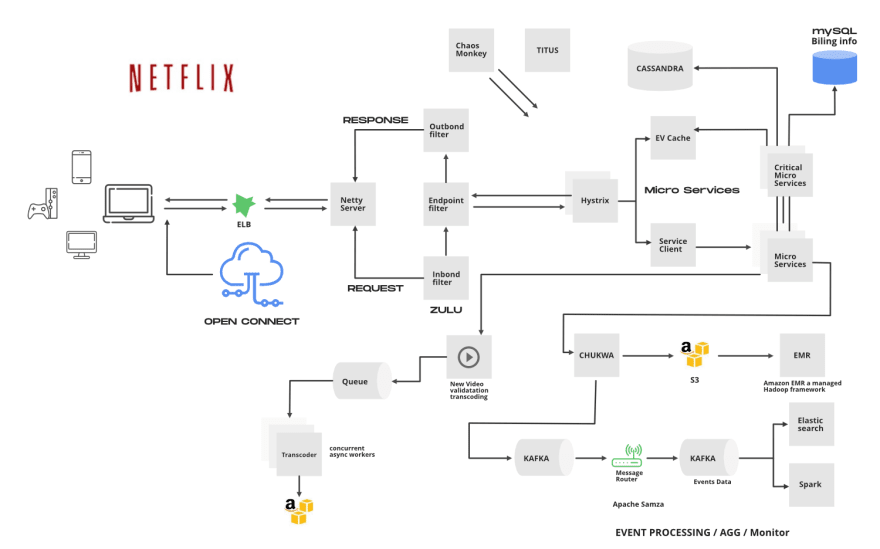
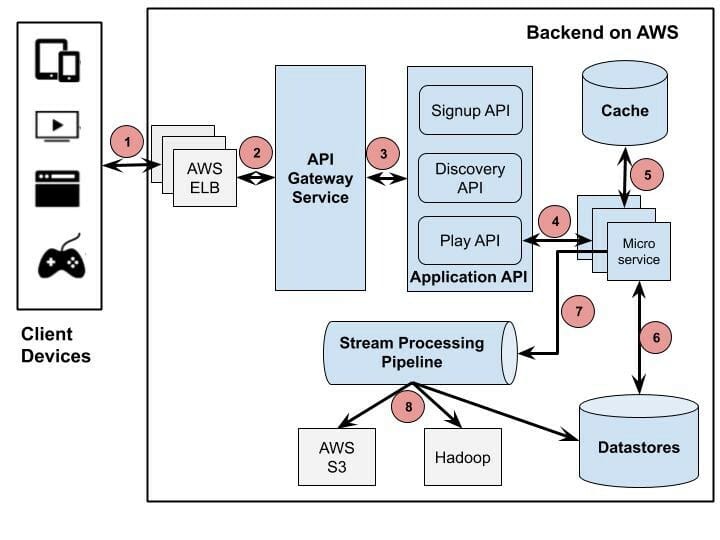
Netflix is one of the major drivers of microservices architecture. Every component of their system is a collection of loosely coupled services collaborating. The microservice architecture enables the rapid, frequent and reliable delivery of large, complex applications. The figure below is an overview of the backend architecture.
Everything that happens after you hit play on a video is handled by Open Connect. This system is responsible for streaming video to your device. The following diagram illustrates how the playback process works.

Netflix uses Amazon's Elastic Load Balancer (ELB) service to route traffic to services. ELB’s are set up such that load is balanced across zones first, then instances.
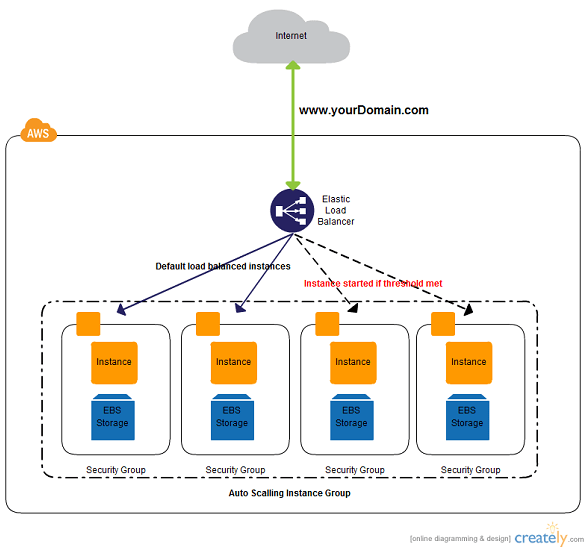
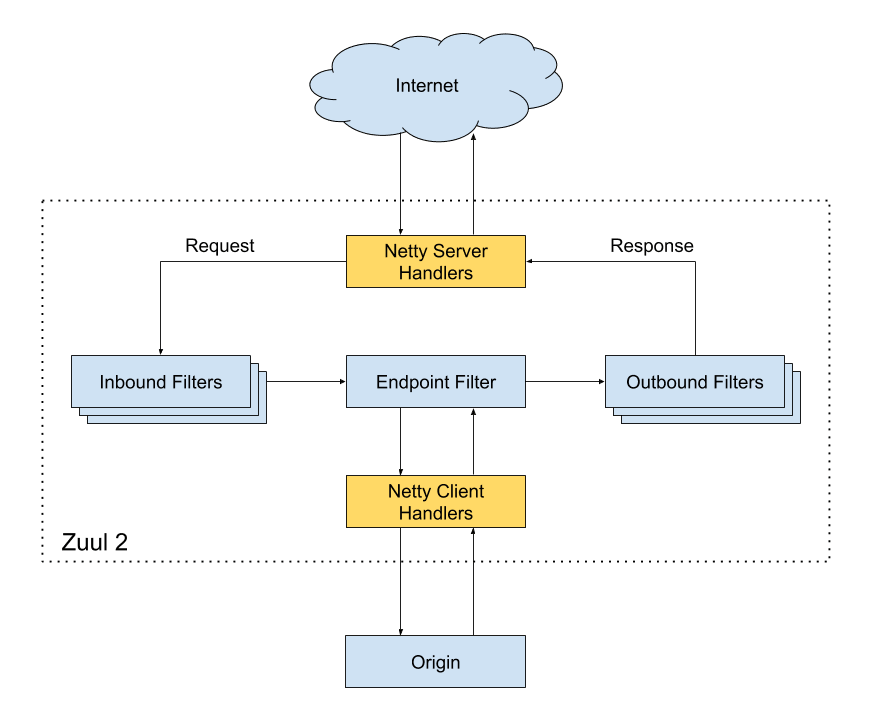
This load balancer routes request to the API gateway service; Netflix uses Zuul as its API gateway, It handles all the requests and performs the dynamic routing of microservice applications. It works as a front door for all the requests.
For Example, /api/products is mapped to the product service, and /api/user is mapped to the user service. The Zuul Server dynamically routes the requests to the respective backend applications. Zuul provides a range of different types of filters that allows them to quickly and nimbly apply functionality to the edge service.
The Cloud Gateway team at Netflix runs and operates more than 80 clusters of Zuul 2, sending traffic to about 100 (and growing) backend service clusters which amount to more than 1 million requests per second.
The Netty handlers on the front and back of the filters are mainly responsible for handling the network protocol, web server, connection management, and proxying work. With those inner workings abstracted away, the filters do all of the heavy liftings.
The Zuul 2 Api gateway forwards the request to the appropriate Application API.
Currently, the Application APIs are defined under three categories: Signup API -for non-member requests such as sign-up, billing, free trial, etc., Discovery API-for search, recommendation requests, and Play API- for streaming, view licensing requests, etc. When a user clicks signup, for example, Zuul will route the request to the Signup API.
If you consider an example of an already subscribed user. Supposing the user clicks on play for the latest episode of peaky blinders, the request will be routed to the playback API. The API in turn calls several microservices under the hood. Some of these calls can be made in parallel because they don’t depend on each other. Others have to be sequenced in a specific order. The API contains all the logic to sequence and parallelize the calls as necessary. The device, in turn, doesn’t need to know anything about the orchestration that goes on under the hood when the customer clicks “play”.

Signup requests map to signup backend services, Playback requests, with some exceptions, map only to playback backend services, and similarly discovery APIs map to discovery services.
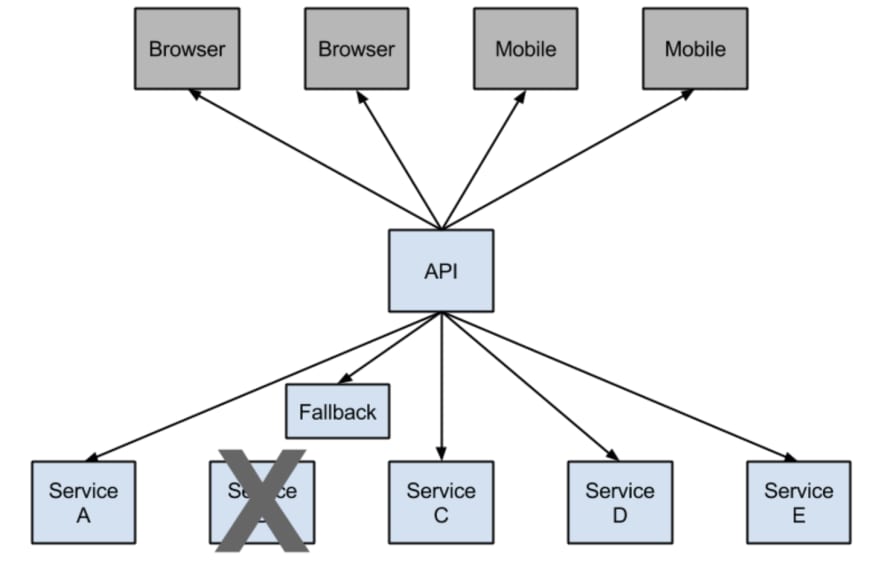
In any distributed environment (with a lot of dependencies), inevitably some of the many service dependencies fail. It can be unmanageable to monitor the health and state of all the services as more and more services will be stood up and some services may be taken down or simply break down. Hystrix comes with help by providing a user-friendly dashboard. Hystrix library is used to control the interaction between these distributed services by adding some latency tolerance and fault tolerance logic.
Consider this example from Netflix, they have a microservice that provides a tailored list of movies back to the user. If the service fails, they reroute the traffic to circumvent the failure to another vanilla microservice that simply returns the top 10 movies that are family-friendly. So they have this safe failover that they can go to and that is the classic example of first circuit breaking.
Note:
Netflix Hystrix is no longer in active development and is currently in maintenance mode. Some internal projects are currently being built with resilience4j
https://github.com/resilience4j/resilience4j
Titus
Titus is a container management platform that provides scalable and reliable container execution and cloud-native integration with Amazon AWS.

It is a framework on top of Apache Mesos, a cluster management system that brokers available resources across a fleet of machines.
Titus is run in production at Netflix, managing thousands of AWS EC2 instances and launching hundreds of thousands of containers daily for both batch and service workloads. Just think of it as the Netflix version of Kubernetes.
Titus is run in production at Netflix, managing thousands of AWS EC2 instances and launching hundreds of thousands of containers daily for both batch and service workloads. Just think of it as the Netflix version of Kubernetes.
Titus runs about 3 million containers per week.
A cache's primary purpose is to increase data retrieval performance by reducing the need to access the underlying slower storage layer. Trading off capacity for speed, a cache typically stores a subset of data transiently.
EVCache
EVCache
Two uses cases for caching is to:
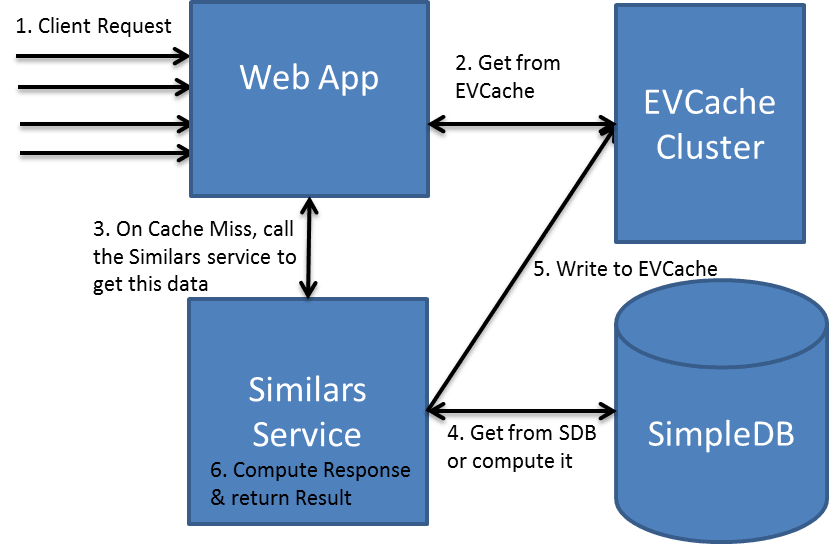
EVCache is a memcached & spymemcached based caching solution that is mainly used for AWS EC2 infrastructure for caching frequently used data.
EVCache is an abbreviation for:
EVCache is an abbreviation for:
Traditionally caching is done on the RAM. Storing large amounts of data on RAM is expensive. Hence Netflix decided to move some caching data to SSD.
Modern disk technologies based on SSD are providing fast access to data but at a much lower cost when compared to RAM. The cost to store 1 TB of data on SSD is much lower than storing the same amount using RAM.
Netflix uses AWS EC2 instances of MYSQL for its Billing infrastructure. Billing infrastructure is responsible for managing the billing state of Netflix members. This includes keeping track of open/paid billing periods, the amount of credit on the member’s account, managing the payment status of the member, initiating charge requests, and what date the member has paid through.
The payment processor needed the ACID capabilities of an RDBMS to process charge transactions.

Cassandra is a free and open-source distributed wide column store NoSQL database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure.
Netflix uses Cassandra for its scalability, lack of single points of failure, and cross-regional deployments. ” In effect, a single global Cassandra cluster can simultaneously service applications and asynchronously replicate data across multiple geographic locations.
Netflix stores all kinds of data across their Cassandra DB instances. All user collected event metrics are stored on Cassandra.
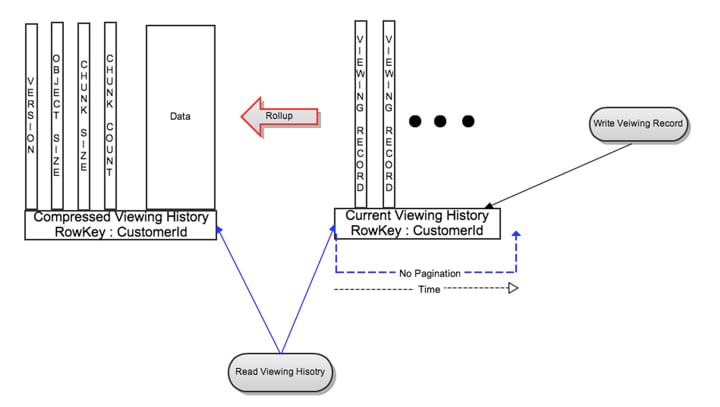
As user data began to increase there needed to be a more efficient way to manage data storage. Netflix Redesigned data storage architecture with two main goals in mind:
The solution to the large data problem was to compress the old rows. Data were divided into two types:
Did you know that Netflix personalizes movie artwork just for you?. You might be surprised to learn the image shown for each video is selected specifically for you. Not everyone sees the same image.

Netflix tries to select the artwork highlighting the most relevant aspect of a video to you based on the data they have learned about you on your viewing history and interests.
Netflix tries to select the artwork highlighting the most relevant aspect of a video to you based on the data they have learned about you on your viewing history and interests.
Stream Processing Data Pipeline has become Netflix’s data backbone of business analytics and personalized recommendation tasks. It is responsible for producing, collecting, processing, aggregating, and moving all microservice events to other data processors in near real-time.
Streaming data is data that is generated continuously by thousands of data sources, which typically send in the data records simultaneously, and in small sizes (order of Kilobytes). Streaming data includes a wide variety of data such as log files generated by customers using your mobile or web applications, e-commerce purchases, in-game player activity, information from social networks, financial trading floors, or geospatial services, and telemetry from connected devices or instrumentation in data centers.
This data needs to be processed sequentially and incrementally on a record-by-record basis or over sliding time windows and used for a wide variety of analytics including correlations, aggregations, filtering, and sampling.
Information derived from such analysis gives companies visibility into many aspects of their business and customer activity such as –service usage (for metering/billing), server activity, website clicks, and geo-location of devices, people, and physical goods –and enables them to respond promptly to emerging situations. For example, businesses can track changes in public sentiment on their brands and products by continuously analyzing social media streams, and respond in a timely fashion as the necessity arises.
The stream processing platform processes trillions of events and petabytes of data per day.

Viewing History Service captures all the videos that are played by members. Beacon is another service that captures all impression events and user activities within Netflix, All the data collected by the Viewing History and Beacon services are sent to Kafka.
Kafka is open-source software that provides a framework for storing, reading, and analyzing streaming data.
Netflix embraces Apache Kafka® as the de-facto standard for its eventing, messaging, and stream processing needs. Kafka acts as a bridge for all point-to-point and Netflix Studio wide communications.
Apache Chukwe is an open-source data collection system for collecting logs or events from a distributed system. It is built on top of HDFS and Map-reduce framework. It comes with Hadoop’s scalability and robustness features. It includes a lot of powerful and flexible toolkits to display, monitor, and analyze data. Chukwe collects the events from different parts of the system; From Chukwe you can do monitoring, analysis or you can use the dashboard to view the events. Chukwe writes the event in the Hadoop file sequence format (S3).
Netflix uses Apache Spark and Machine learning for Movie recommendation. Apache Spark is an open-source unified analytics engine for large-scale data processing.
On a live user request, the aggregated play popularity(How many times is a video played) and take rate(Fraction of play events over impression events for a given video) data along with other explicit signals such as members’ viewing history and past ratings are used to compute a personalized content for the user. The following figure shows the end-to-end infrastructure for building user movie recommendations.

Netflix uses elastic search for data visualization, customer support, and for error detection in the system.
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents.
With elastic search, they can easily monitor the state of the system and troubleshoot error logs and failures.
This article has provided a detailed analysis of the Netflix Backend architecture. You can refer to these references for more information.
26