
33
MLOps: Operationalizing ML on AWS | AWS WhitePaper Summary
This happens because there are a higher number of:
- changing artifacts to be managed.
- In addition to the software code, such as the datasets, the machine learning models, and the parameters and hyperparameters used by such models.
- And the size and portability of such artifacts can be orders of magnitude higher than the software code.
There are also organizational challenges.
- Different teams might own different parts of the process and have their own ways of working.
- Data engineers might be building pipelines to make data accessible, while data scientists can be researching and exploring better models.
- Machine learning engineers or developers then have to worry about how to integrate that model and release it to production.
- When these groups work in separate siloes, there is a high risk of creating friction in the process and delivering suboptimal results.
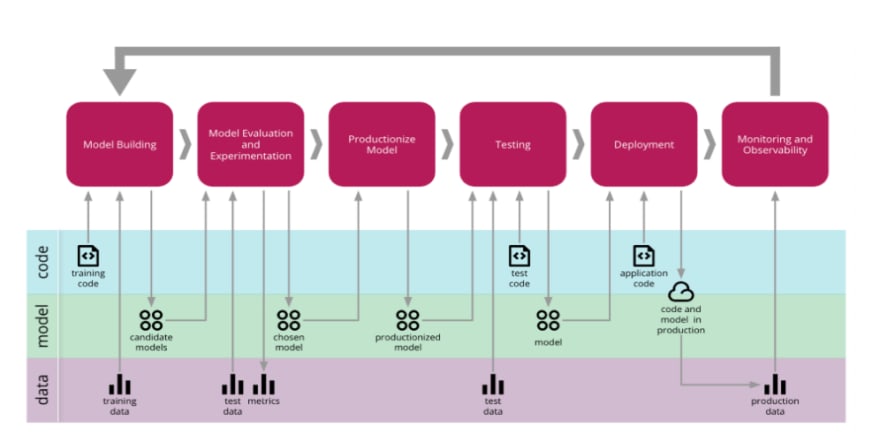
There are different approaches to do that with minimal disruption:
- You can have multiple models performing the same task for different partitions of the problem.
- You can have a shadow model deployed side by side with the current one to monitor its performance before promoting it.
- You can have competing models being actively used by different segments of the user base.
- Or you can have online learning models that are continuously improving with the arrival of new data.
Elastic cloud infrastructure is a key enabler for implementing these different deployment scenarios while minimizing any potential downtime, allowing you to scale the infrastructure up and down on-demand, as they are rolled out.
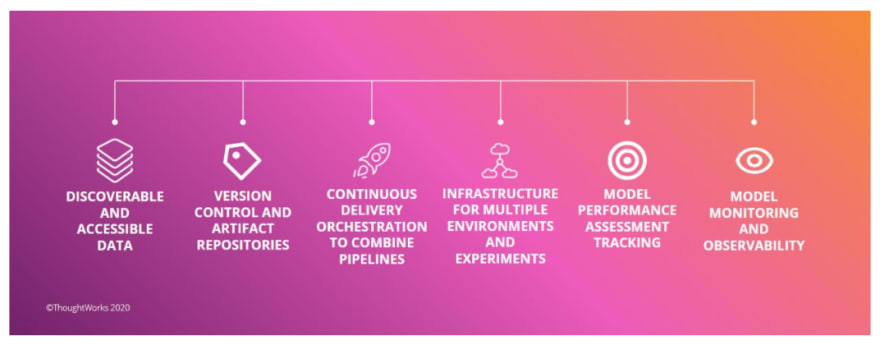
This whitepaper showcases MLOps solutions from AWS and the following AWS Partner Network (APN) companies that can deliver on the previously mentioned requirements:
- Alteryx
- Dataiku
- Domino Data Lab
- KNIME
These solutions offer a broad spectrum of experiences that cater to builders and those who desire no-to-low-code experiences.
AWS and the APN provide you with choices and the ability to tailor solutions that best fit your organization.
Alteryx Designer – desktop software that enables the assembly of code-free analytic workflows and apps
Alteryx Server – an analytical hub that allows users to scale their analytic capabilities in the cloud or on premises on enterprise hardware
Alteryx Promote – a deployable, containerized solution that enables the easy deployment of machine learning models as highly available REST APIs


It pioneered the Data Science Platforms category, and today powers data science research at over 20% of Fortune 100 companies.
Domino brings order to the chaos of enterprise data science through:
- Instant access to compute – IT-approved, self-service, elastic
- Data, code, environment, and model management – automatically versioned, searchable, shareable, and always accessible
- Openness – open source and proprietary IDEs and analytical software, all containerized under one platform and deployed on premises or in the cloud
- Full reproducibility of research – central knowledge management framework, with all units of work tied together
- Collaboration – for teams and for enterprises, with access to comprehensive search capabilities to share all key assets and collaborate on projects
- Easy deployment – models, web apps, other data products
- Platform and project management – best-in-class governance and security for IT and data science leaders
There are two tools to cover the entire data science lifecycle:
- KNIME Analytics Platform
- KNIME Server
KNIME on AWS:
- Both KNIME Analytics Platform and KNIME Server are offered in various forms in the AWS Marketplace .
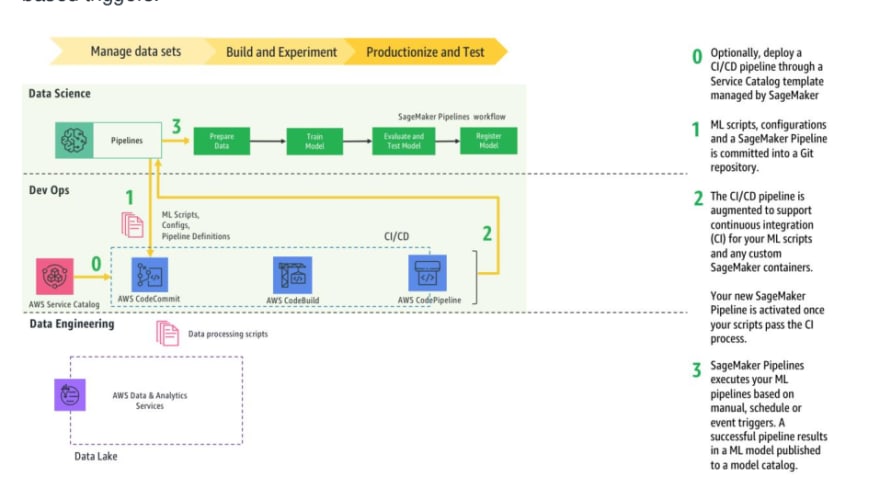
- AWS – Connect with vetted MLOps consultants and try Amazon SageMaker for free.
- Alteryx – Get started with the Alteryx Intelligence Suite Starter Kit.
- Dataiku – Launch a free-trial of Dataiku DSS from the AWS Marketplace.
- Domino Data Lab – Launch a free-trial of Domino Data Lab’s managed offering.
- KNIME – Launch a free-trial of the KNIME Server from the AWS Marketplace.
- ThoughtWorks – Learn more about ThoughtWorks’ CD4ML.
33