
28
AWS Well-Architected Framework | AWS Whitepaper Summary
Hi folks , Today I will go through with one of the most important whitepapers in AWS
Original One
Original One
The AWS Well-Architected Framework helps you understand the pros and cons of decisions you make while building systems on AWS. By using the Framework, you will learn architectural best practices for designing and operating reliable, secure, efficient, and cost-effective systems in the cloud. It provides a way for you to consistently measure your architectures against best practices and identify areas for improvement.
AWS also provides a service for reviewing your workloads at no charge. The AWS Well-Architected Tool (AWS WA Tool) is a service in the cloud that provides a consistent process for you to review and measure your architecture using the AWS Well-Architected Framework. The AWS WA Tool provides
recommendations for making your workloads more reliable, secure, efficient, and cost-effective
recommendations for making your workloads more reliable, secure, efficient, and cost-effective
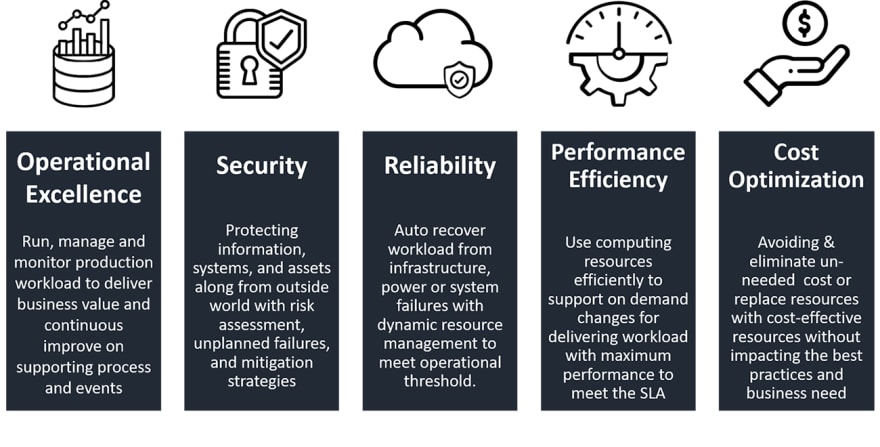
The AWS Well-Architected Framework is based on five pillars —
The Operational Excellence pillar includes the ability to support development and run workloads effectively, gain insight into their operations, and to continuously improve supporting processes and procedures to deliver business value
1.Perform operations as code
2.Make frequent, small, reversible changes
3.Refine operations procedures frequently
4.Anticipate failure
5.Learn from all operational failures
2.Make frequent, small, reversible changes
3.Refine operations procedures frequently
4.Anticipate failure
5.Learn from all operational failures
There are four best practice areas for operational excellence in the cloud:
1.Organization
1.Organization
2.Prepare
When you understand your workloads and their expected behaviors, capture a broad set of information to enable situational awareness (for example, changes in state, user activity, privilege access, utilization counters), knowing that you can use filters to select the most useful information over time.
When you understand your workloads and their expected behaviors, capture a broad set of information to enable situational awareness (for example, changes in state, user activity, privilege access, utilization counters), knowing that you can use filters to select the most useful information over time.
These accelerate beneficial changes entering production:
3.Operate
Efficient and effective management of operational events is required to achieve operational excellence.
4.Evolve
You must learn, share, and continuously improve to sustain operational excellence. Include feedback loops within your procedures to rapidly identify areas for improvement and capture learnings from the execution of operations.
You must learn, share, and continuously improve to sustain operational excellence. Include feedback loops within your procedures to rapidly identify areas for improvement and capture learnings from the execution of operations.
Analyze trends within lessons learned and perform cross-team retrospective analysis of operations metrics to identify opportunities and methods for improvement.
Successful evolution of operations is founded in: frequent small improvements; providing safe environments and time to experiment, develop, and test improvements; and environments in which learning from failures is encouraged. Operations support for sandbox, development, test, and production environments, with increasing level of operational controls, facilitates development and increases the predictability of successful results from changes deployed into production
Check out this Session also
The Security pillar encompasses the ability to protect data, systems, and assets to take advantage of cloud technologies to improve your security
1.Implement a strong identity foundation (least privilege, separation of duties, no long-term static credentials)
2.Enable traceability (Monitor, alert, and audit actions)
3.Apply security at all layers
4.Automate security best practices
5.Protect data in transit and at rest
6.Keep people away from data
7.Prepare for security events
2.Enable traceability (Monitor, alert, and audit actions)
3.Apply security at all layers
4.Automate security best practices
5.Protect data in transit and at rest
6.Keep people away from data
7.Prepare for security events
There are six best practice areas for security in the cloud:
1.Security
1.Security
2.Identity and Access Management
3.Detection
4.Infrastructure Protection
Any workload that has some form of network connectivity, whether it’s the internet or a private network, requires multiple layers of defense to help protect from external and internal network-based threats.
Any workload that has some form of network connectivity, whether it’s the internet or a private network, requires multiple layers of defense to help protect from external and internal network-based threats.
5.Data Protection
5.Incident Response
Ensure that you have a way to quickly grant access for your security team, and automate the isolation of instances as well as the capturing of data and state for forensics
The AWS Shared Responsibility Model enables organizations that adopt the cloud to achieve their security and compliance goals. Because AWS physically secures the infrastructure that supports our cloud services, as an AWS customer you can focus on using services to accomplish your goals.
Is the ability of a workload to perform its intended function correctly and consistently when it’s expected to.
There are four best practice areas for reliability in the cloud:
1.Foundations
It’s the responsibility of AWS to satisfy the requirement for sufficient networking and compute capacity service quotas (which are also referred to as service limits). These quotas exist to prevent accidentally provisioning more resources than you need and to limit request rates on API operations so as to protect services from abuse
2.Workload Architecture
AWS SDKs take the complexity out of coding by providing language-specific APIs for AWS services. These SDKs, plus the choice of languages, allow developers to implement the reliability best practices listed here
Your workload must operate reliably despite data loss or latency in these networks
3.Change Management
1.Foundations
It’s the responsibility of AWS to satisfy the requirement for sufficient networking and compute capacity service quotas (which are also referred to as service limits). These quotas exist to prevent accidentally provisioning more resources than you need and to limit request rates on API operations so as to protect services from abuse
2.Workload Architecture
AWS SDKs take the complexity out of coding by providing language-specific APIs for AWS services. These SDKs, plus the choice of languages, allow developers to implement the reliability best practices listed here
Your workload must operate reliably despite data loss or latency in these networks
3.Change Management
4.Failure Management
Is the ability to use computing resources efficiently to meet system requirements, and to maintain that efficiency as demand changes and technologies evolve
There are four best practice areas for performance efficiency in the cloud:
1.Selection
1.Selection
Compute
Storage
Database
Network
2.Review
3.Monitoring
4.Tradeoffs
You could trade consistency, durability, and space for time or latency, to deliver higher performance.
As you make changes to the workload, collect and evaluate metrics to determine the impact of those changes. Measure the impacts to the system and to the end-user to understand how your trade-offs impact your workload. Use a systematic approach, such as load testing, to explore whether the tradeoff improves performance.
You could trade consistency, durability, and space for time or latency, to deliver higher performance.
As you make changes to the workload, collect and evaluate metrics to determine the impact of those changes. Measure the impacts to the system and to the end-user to understand how your trade-offs impact your workload. Use a systematic approach, such as load testing, to explore whether the tradeoff improves performance.
Is the ability to run systems to deliver business value at the lowest price point
There are five best practice areas for cost optimization in the cloud:
1.Practice Cloud Financial Management
1.Practice Cloud Financial Management
2.Expenditure and usage awareness
3.Cost-effective resources
4.Manage demand and supply resources
5.Optimize over time
Recently AWS introduced a new AWS Well-Architected Sustainability Pillar to help organizations learn, measure, and improve workloads using environmental best practices for cloud computing.
Sustainable development
can be defined as “development that meets the needs of the present without compromising the ability of future generations to meet their own needs.” Your business or organization can have negative environmental impacts like direct or indirect carbon emissions, unrecyclable waste, and damage to shared resources like clean water
can be defined as “development that meets the needs of the present without compromising the ability of future generations to meet their own needs.” Your business or organization can have negative environmental impacts like direct or indirect carbon emissions, unrecyclable waste, and damage to shared resources like clean water
When building cloud workloads, the practice of sustainability is understanding the impacts of the services used, quantifying impacts through the entire workload lifecycle, and applying design principles and best practices to reduce these impacts
Design principles for sustainability in the cloud
Apply these design principles when architecting your cloud workloads to maximize sustainability and minimize impact.
Apply these design principles when architecting your cloud workloads to maximize sustainability and minimize impact.
Understand your impact: Measure the impact of your cloud workload and model the future impact of your workload. Include all sources of impact, including impacts resulting from customer use of your products, and impacts resulting from their eventual decommissioning and retirement
Establish sustainability goals: For each cloud workload, establish long-term sustainability goals such as reducing the compute and storage resources required per transaction. Model the return on investment of sustainability improvements for existing workloads, and give owners the resources they need to invest in sustainability goals.
Maximize utilization: Right-size workloads and implement efficient design to ensure high utilization and maximize the energy efficiency of the underlying hardware. Two hosts running at 30% utilization are less efficient than one host running at 60% due to baseline power consumption per host
Anticipate and adopt new, more efficient hardware and software offerings: Support the upstream improvements your partners and suppliers make to help you reduce the impact of your cloud workloads
Use managed services: Sharing services across a broad customer base helps maximize resource utilization, which reduces the amount of infrastructure needed to support cloud workloads. For example, customers can share the impact of common data center components like power and networking by migrating workloads to the AWS Cloud and adopting managed services, such as AWS Fargate for serverless containers, where AWS operates at scale and is responsible for their efficient operation
Reduce the downstream impact of your cloud workloads: Reduce the amount of energy or resources required to use your services. Reduce or eliminate the need for customers to upgrade their devices to use your services. Test using device farms to understand expected impact and test with customers to understand the actual impact from using your services.
Finally , Thanks for your patient to read this summary and I Hope you saw it useful
28