
32
Methods of Data Storage in Data Science You Should Know
Photo by Art Wall - Kittenprint on Unsplash
We live in extraordinary times where technology is part of everything. One of the things that have made technology so powerful and valuable is data. A vast amount of data is generated every day on the internet. Consider the data generated on Instagram alone:
This massive amount of data (called big data because of the size) cannot be stored using traditional techniques or on one machine. Storing and retrieving big data requires multiple interconnected machines. This article focuses on the different techniques of storing big data and their pros, cons, and use cases.
Before diving into the different types of data storage, we must first look at the types of data.
Human
Machine
Structured data accounts for about 20% of all the data on the internet and is usually easy to analyze to derive meaningful insights.
Human
Machine
Analyzing unstructured data is more complex and usually involves creating machine learning models. This data comprises about 80% of the data on the internet and has become easier to store and maintain.

Image SourceI like to think of this type of data as a kind of hybrid of both the above-mentioned types. It usually contains a structured part and an unstructured part.
Some examples of semi-structured data are emails and word documents. Notice these contain text (structured data) and media files (unstructured data). Think now of the data stored in NoSQL DBs in which one item has a certain number of fields, but the next does not—that is a semi-structured dataset. Notice that an email has the to, from, cc, and bcc fields, which are structured data, but it may also contain images.
Now that we have familiarised ourselves with the different types of data, we can look at the various methods of storing this data.
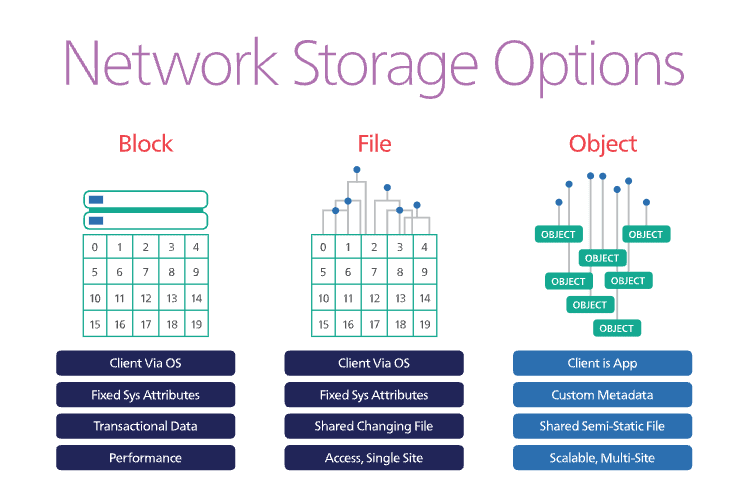
In block storage, data is stored as a contiguous chunk (called a block). It allows us to spread our network easily across different networks, and you don’t need to know where it is stored on the disk to access it. Relational databases are examples of RDMS, making it the best type of storage for structured data.
Other characteristics include:
They are highly scalable: You can increase the size of your block storage by adding more nodes to your network, thus making it easy to scale.
Easy to replicate: Most block storage services are easy to backup/replicate. Thus, in case of machine failure, your data is still intact.
Reads and writes are fast, and you do not need to know where the data is on disk.
Block storage is generally expensive as the data increases. This makes it expensive for data that is large, for instance.
They are highly scalable: You can increase the size of your block storage by adding more nodes to your network, thus making it easy to scale.
Easy to replicate: Most block storage services are easy to backup/replicate. Thus, in case of machine failure, your data is still intact.
Reads and writes are fast, and you do not need to know where the data is on disk.
Block storage is generally expensive as the data increases. This makes it expensive for data that is large, for instance.
An object is made up of 3 main parts:
Anytime an object is created, most services replicate it three times. This makes it easy to retrieve the object and search for the data. Thus, object storage is ideal for storing unstructured data as it can easily be accessed using an ID.
Advantages of object storage include:
In this article, we looked at the different types of data in big data and explored the main techniques of storing big data. I hope you learn something new from this article.
32