
29
AWS open source news and updates #76
Newsletter #76.
This week, we have new oss projects such as ecs-files-composer, lucid-dynamodb, kubectl-trace, tailscale-layer and more. AWS and community blog posts featuring OpenSearch, Kubernetes, COBOL, Jamulus, Firecracker, Apache Hudi, Apache Kakfa, Apache Flink, Redis and more. In the videos section we catch up with a couple of the sessions from the Airflow Summit and finally, some new events for your diary.
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following open source heroes: Tal Hoffman, Corey Quinn, John Preston, Pahud Hsieh, Vu Dao, Martin Baillie, Richard Austin Melchior, Re Alvarez-Parmar, Nithish Kumar Murcherla, Drew Zhang, Ali Arsanjani, Ashish Khetan, Li Zhang, Yi Xiang, Piotr Chotkowski, John Mousa, Sascha Janssen, Veliswa Boya, Didier Durand, Scott Kellish, Asaf Porat Stoler, Zach Gardner, Yaron Sananes, Zoltan Bozoky, Soyean Kim, Victor Leung, Nelson Assis, Param Sharma, Arindam Chatterji, Kyle Thomson, Matt Asay, Antony Prasad Thevaraj, Helge Aufderheide, Dhiraj Thakur, Sameer Goel, and Imtiaz Sayed.
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
ecs-files-composer
ecs-files-composer and useful open source project from John Preston, ECS Files Composer, is a small program that will allow users to define files they need pulled out of AWS Services, such as AWS S3 or AWS SSM Parameter Store, and load the content to a given location, adding builtin capabilities to set file ownership, mode, and other handy features. Great examples, use cases and top notch documentation as you would expect from a project form Mr Preston. Nice work.
lucid-dynamodb
kubectl-trace
tailscale-layer
Tailscale is a next-generation VPN approach that wraps around Wireguard. It offers a useful management interface, uses far less power on mobile devices than options like OpenVPN, and claims to run on almost anything.
In other words, this extension can be used with any existing Lambda function to provide communication across your Tailscale network — without having to configure a bunch of network rules that, frankly, don't work very well across different provider boundaries.
So far, I've used the extension to have Lambda functions talk to: The Raspberry Pi in my video production studio/guest room/sewing closet/screamatorium. My massively overpowered instance running in Oracle Cloud's yes-it's-actually-free tier. My iPhone and iPad. Resources living inside of my AWS VPCs, without having to use a NAT instance or Managed NAT Gateway to allow those functions to also speak to external resources.
Read more in the blog post he put around this, in Corey Writes Open-Source Code for Lambda and Tailscale
serverless-mux-on-aws

blog-multi-arch-springboot
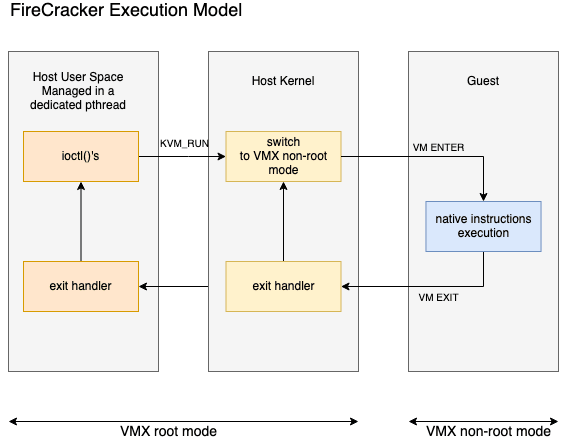
Firecracker
Tal Hoffman dives deep in his blog post, Firecracker internals: a deep dive inside the technology powering AWS Lambda guiding you through some of the Firecracker code. An often forgotten fact that sometimes just going through the source code of open source projects like Firecracker is one of the best ways to improve your understanding of it. Very nice post.
Emacs
If you are an Emacs user, then Martin Baillie has a must read post for you this week, in Emacs TRAMP over AWS SSM APIs showing you how you can use Emacs TRAMP mode to copy files to and from different locations on an EC2 instances, using SSH proxied over SSM.
Kubernetes

Next.js
Richard Austin Melchior has put together this post, Ship it, Next.js on AWS with Serverless Framework where he shows you how you can take a built Next.js application and ship it onto an AWS serverless stack using the Serverless framework.
OpenSearch
Essential reading this week, and a great shout out to the contributors so far.
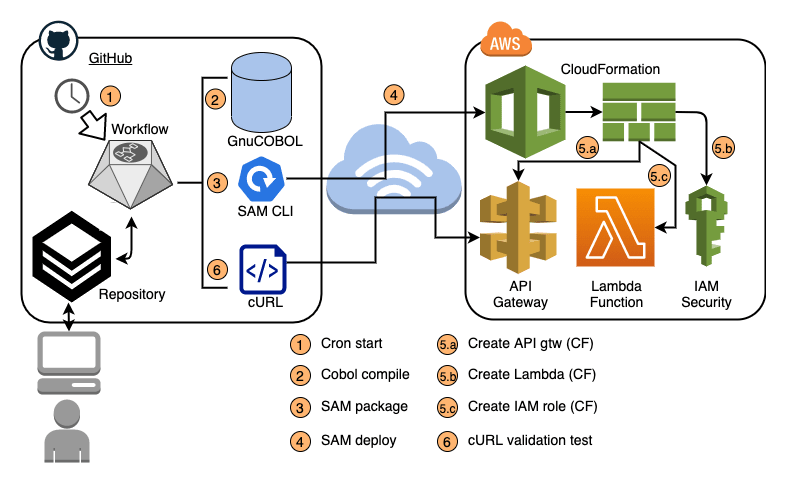
COBOL
Great two part post from Veliswa Boya and Didier Durand, Serverless COBOL: Rejuvenating legacy code with open source software Part 1 (and Part 2) show you how you can use open source software, in this instance GnuCOBOL, combined with AWS to extend the life of legacy code to help build modern (serverless) mainframes. They also take a look at the additional benefits of open source software when legacy features are deployed in such a modern environment. Really great post, and recommended reading this week. [hands on]
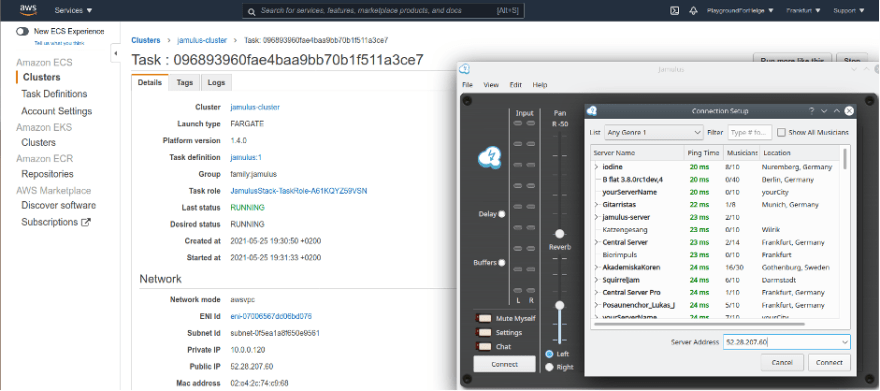
Jamulus
Jamulus is an open source project that enables you to play music, rehearse, or just jam with anyone online with low latency and works across multiple desktop clients such as Windows, macOS, or Linux. These clients connect to Jamulus servers worldwide. In this post from Helge Aufderheide, Running your own server for Jamulus, an open source solution to jam with other musicians online you will soon be able to get your own Jamulus server up and running and fulfil your musical rockstar ambitions to a global audience (rather than just the shower or car)
[hands on]
Apache Kafka

Apache Hudi
Dhiraj Thakur, Sameer Goel, and Imtiaz Sayed have come together to write this first in a series of posts, Query an Apache Hudi dataset in an Amazon S3 data lake with Amazon Athena part 1: Read-optimized queries. This series will look at Athena and Apache Hudi, and will provide a short overview of key Hudi capabilities along with detailed procedures for using read-optimized queries, snapshot queries, and bootstrapped tables. [hands on]
Apache Flink/Grafana
John Mousa and Sascha Janssen have put together this blog post, Near real-time processing with Amazon Kinesis, Amazon Timestream, and Grafana is part of a series of posts that aim to explore various patterns for data ingestion and cost-effective architecture pipelines. This particular looks at device telemetry uses cases. You will see how you can monitor your devices’ operations by visualising operational data with Grafana, using Apache Flink to transforms and aggregate streaming data in near-real time, to detect and clean any errors in time series data timestamps before ingesting them in Timestream to optimise operational analytics.
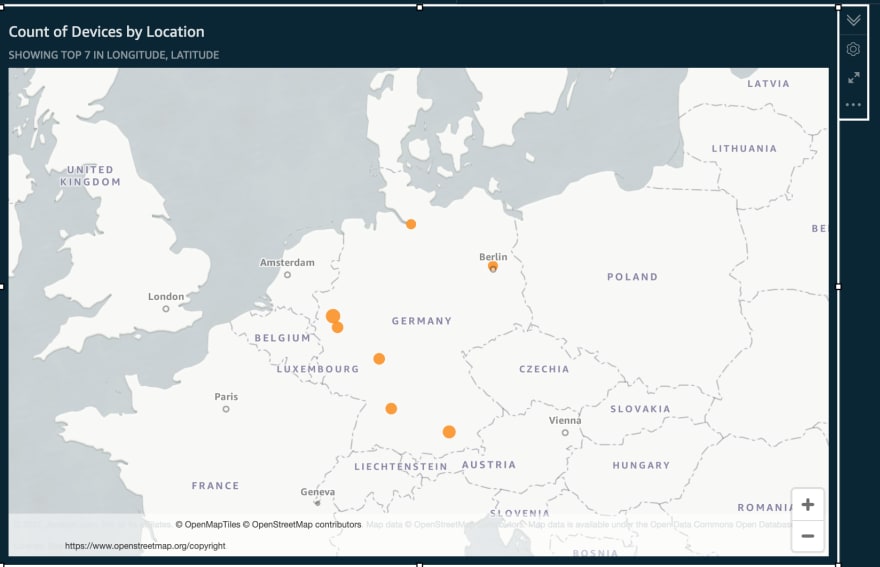
All the source code is available so you can reproduce this for yourself. [hands on]
Redis
In this blog post, Migrate Amazon ElastiCache to Graviton2 processors Scott Kellish, Asaf Porat Stoler, Zach Gardner, and Yaron Sananes explore the performance benefits of Graviton2 instances and how to migrate your ElastiCache for Redis cluster to Graviton2. More and more workloads are moving to Arm, and this is an area where open source projects are helping to unlock the ability for customers to run their workloads on any processor architecture.
Last week we also had Matt Asay and Antony Prasad Thevaraj post, How AWS and Redis Labs partner to make a better Redis which takes a look at how you can both collaborate with and compete with open source. The post explores that in detail as well as taking a look at how it all comes back to how we can best serve our customers.
Kubernetes
Param Sharma and Arindam Chatterji show you how to set up end-to-end encryption on Amazon Elastic Kubernetes Service (Amazon EKS) with AWS Certificate Manager Private Certificate Authority in the post, TLS-enabled Kubernetes clusters with ACM Private CA and Amazon EKS. You will learn how you can set up an NGINX ingress controller on Amazon EKS. As part of the example, we show you how to configure an AWS Network Load Balancer (NLB) with HTTPS using certificates issued via ACM Private CA in front of the ingress controller. [hands on]
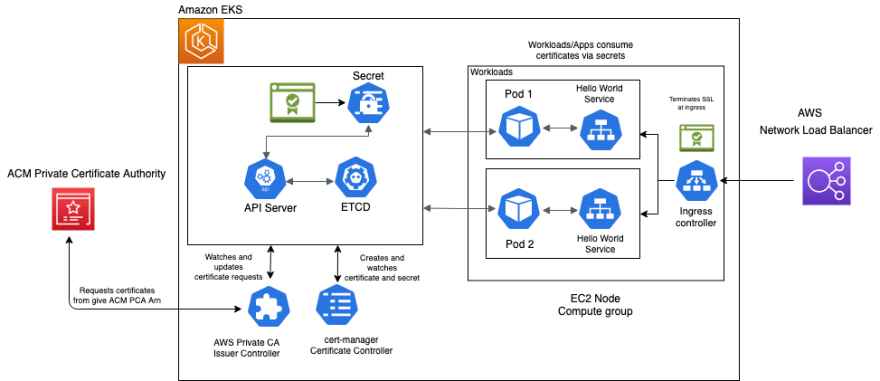
Fluentd
Following on from last weeks Fluentd/Amazon EKS post, this week it is the turn of Re Alvarez-Parmar, Nithish Kumar Murcherla, and Drew Zhang in the post Capturing logs at scale with Fluent Bit and Amazon EKS where they explore the need for optimisation when using Fluentd or Fluent Bit for log aggregation and demonstrate recent enhancements to Fluent Bit that are designed to reduce the volume API calls it makes to the Kubernetes API servers. An image is worth many words they say, so let me leave this here to tempt you into reading more. [hands on]

SageMaker JumpStart
SageMaker JumpStart is a capability in SageMaker that allows you to quickly get started with ML. JumpStart uses open-source pre-trained models to solve common ML problems like image classification, object detection, text classification, sentence pair classification, and question answering. In this first of a series, Ali Arsanjani, Ashish Khetan, and Li Zhang have put together Run image classification with Amazon SageMaker JumpStart, covers image classification tasks.
Tensorflow Serving
Yi Xiang has put together this post, Deploy variational autoencoders for anomaly detection with TensorFlow Serving on Amazon SageMaker that looks at how you can implement a variational autoencoder on SageMaker to solve an anomaly detection tasks, showing you how you can deploy multiple trained models to a single TensorFlow Serving multi-model endpoint. [hands on]
Zoltan Bozoky, Soyean Kim, and Victor Leung from Providence Health Care together with Nelson Assis from AWS shared how a public health organisation can use cloud services together with open source to improve medical care, such as infection prevention and control practices in controlled environments, in the post
Using cloud computing to develop an open source infection prevention and disease control solution
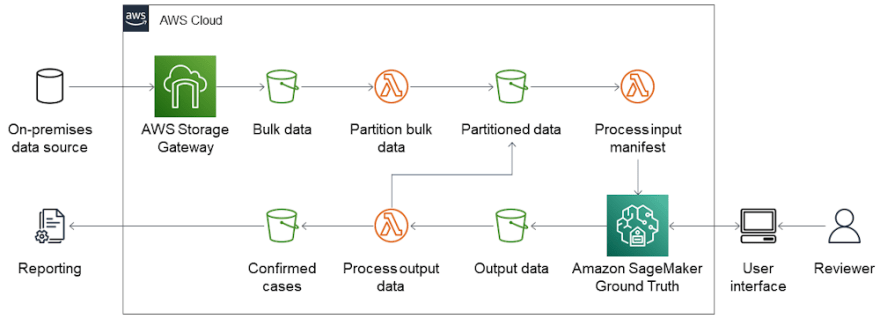
The open source AWS Quick Start solution described in this post can help you increase data throughput, minimise the total cost of ownership, and enable robust security, while providing enhanced availability, capacity, and scalability through access to advanced data mining and modelling services. [hands on]
In case you missed it, last week was the Airflow Summit, a free online conference for the worldwide community of developers and users of Apache Airflow. There were a few sessions covering Amazon Managed Workflows for Apache Airflow (MWAA), as well as lots of other great sessions which you should check out.
Apache Airflow 2.0 on Amazon MWAA
In this session we will discuss Amazon Managed Workflows for Apache Airflow (MWAA), how Apache Airflow (and specifically version 2.0) is implemented in the service, best practices for deployment and operations, and the Amazon MWAA team’s commitment to open source usage and contributions.
MWAA: Design Choices and Road Ahead
An informal and fun chat about the journey that we took and the decisions that we made in building Amazon Managed Workflows for Apache Airflow. We will talk about Our first tryst with understanding Airflow Talking to Amazon Data Engineers and how they ran workflows at scale Key design decisions and the reasons behind them Road ahead, and what we dream about for future of Apache Airflow. Open-Source tenets and commitment from the team We will leave time at the end for a short AMA/Questions.
AWS Toolkit for JetBrains
In this blog post, AWS Toolkit for JetBrains now supports Go and TypeScript Kyle Thomson shares how Go and TypeScript are now supported in this open source plugin.
Amplify Flutter
Last week the AWS Amplify’s tools and libraries for Flutter were updated to support null safety for all of our use cases. Flutter developers can now enjoy all the easy-to-integrate Amplify functionality with higher reliability and improved developer ergonomics. Sound null safety is a Dart language feature in which code is non-nullable by default and turns runtime null-dereference errors into edit-time analysis errors. This enables developers to reduce bugs in their code and benefit from performance improvements through smaller binaries and faster execution.
Null safety protection was introduced with Flutter 2 as an opt-in feature for developers and, as of Flutter 2.2, is enabled by default for all new Flutter apps. With this release of Amplify Flutter developers can now create new apps with null safety enabled, and no longer have to wait to migrate their existing apps to be null safe.
PostgreSQL
We have updated Amazon RDS for PostgreSQL to support PostgreSQL minor versions 13.3, 12.7, 11.12, 10.17, and 9.6.22. This release closes security vulnerabilities in PostgreSQL and contains bug fixes and improvements done by the PostgreSQL community.
This release also adds support for the oracle_fdw extension, which allows your PostgreSQL database to connect and retrieve data stored in separate Oracle databases.
FreeRTOS
FreeRTOS AWS reference integrations are pre-integrated FreeRTOS projects ported to microcontroller-based evaluation boards that demonstrate end-to-end connectivity to AWS IoT Core. This helps developers save months of development effort and accelerate time to market. FreeRTOS AWS reference integrations now include the new managed AWS IoT Over-the-Air update (OTA) library, AWS IoT Jobs library, and the AWS IoT Device Defender custom metrics feature from the FreeRTOS 202012.01 LTS release, and the coreMQTT Agent library from the FreeRTOS 202104.00 release.
Developers can use the reference integrations to get started on a wide variety of evaluation boards and use the integrated libraries to remotely update IoT device firmware, manage IoT device fleets, monitor IoT device fleet metrics, and to simplify the management of MQTT connections in multi-threaded applications.
Read more, including links to supporting blog posts here.
Open datasets
Forty-four new or updated datasets from the National Library of Medicine, Digital Earth Africa, Amazon, and others are available on the Registry of Open Data in the following categories: COVID-19, Agriculture, Climate and Weather, Energy, Geospatial, Life Sciences and Machine Learning.
Check out the full announcement, including links to the open datasets in, New datasets available on the Registry of Open Data from the National Library of Medicine, Digital Earth Africa, Amazon, and others
You can also read the blog post from Joe Flasher, Satellite imagery over Africa, a large-scale climate ensemble, and product listings with 3D renderings: The latest open data on AWS that looks at a few of those open datasets in more detail.
Hugging Face
Last week we announced AWS Deep Learning Containers (DLCs) with integrated SDKs for inference that enable customers to easily deploy Hugging Face models in Amazon SageMaker at scale. Read the full announcement in the post, Amazon announces new AWS Deep Learning Containers to deploy Hugging Face models faster on Amazon SageMaker
Later this week, there are a couple of interesting looking events you should check out.
Developing Secure Open Source Software (OSS) [FREE Event]
July 20th, 9:30 – 11:00am PDT
David Wheeler, Director of Open Source Supply Chain Security at The Linux Foundation will discuss steps you can take to develop more secure OSS and evaluate OSS for security.
Read more and register here
ML Dev Day Live Workshop [FREE Event]
July 21st 9:00am PDT
Learn how to build highly scalable and reliable pipelines for analytics using open source technologies such as Apache Spark, Delta Lake and open source machine learning frameworks such as TensorFlow, XGBoost, scikit-learn and MLFlow.
Read more and register here.
Open Data Lakes with Presto, Apache Hudi & AWS Glue and S3 – the next generation of analytics
July 27th at 10am PT/ 1pm ET
Sign up for this roundtable discussion where experts from each layer in this stack – Presto, AWS, and Apache Hudi – will discuss why they are seeing a pronounced adoption to this next generation of cloud data lake analytics and how these technologies enable open, flexible, and highly performant analytics in the cloud.
Read more and register here
Cloud Native Day
23rd September, Bern Switzerland
What is this, an in person event returning? A stellar line up including our own Michael Hausenblas, an event looking at CNCF projects and the future of IT. Find out more and to view prices/register, by clicking here.
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on [@AWSOpen](https://twitter.com/AWSOpen
29