
49
Detecting and Visualizing Twitter Sentiment during COVID-19 Pandemic using AWS Comprehend and Quicksight
People are experiencing a prolonged state of physical isolation from their friends, as well as teachers, extended family, and community networks due to COVID-19 lockdown. While quarantining adults has generally led to negative psychological effects, including confusion, anger, and post-traumatic distress, it is unknown how these measures have impacted children.
The twitter consumer sentiment is the most common text classification tool that analyzes an incoming tweet and conveys if the underlying sentiment is positive negative or neutral from the public.
Taking India as a case study, we are going to analyze the sentiment of people during each phase of COVID-19 Pandemic. The three phases are Pre-lockdown, Lockdown and Unlock phases.

Lets orchestrate AWS services to access the data, identify the sentiment and then visualise the results.

The tweets were collected on three bases:
Only tweets in English were collected for this purpose.
Keyword : 15 trending keywords related to COVID-19.
Location : Chennai, Bangalore, Hyderabad, Delhi, Mumbai, Kolkata.
Date Range : Three phases — Pre-lockdown, Lockdown, Unlock.
The GetOldTweets3 python library was used to collect the tweets based on the above three criteria. To preprocess the data, NLTK packages were used.
The GetOldTweets3 python library was used to collect the tweets based on the above three criteria. To preprocess the data, NLTK packages were used.
To save you from the hassle, I have uploaded the dataset in my Github repo. The techniques used for data collection and preprocessing is explained in the readme file.
All dataset contains three features: tweet text, location, phase.
All dataset contains three features: tweet text, location, phase.
If you are new to AWS, then you create your free AWS account here.
Go to IAM Console and then click roles. Give a name for the role (s3-lambda-role) and then select Lambda as the use case. Under permission, attach the following policies as mentioned in the picture below and create.

We are creating a user to export the Dynamo DB data. Click Users in the side pane of IAM console. Create a new user and attach “AmazonDynamoDBFullAccess” permission. Also, under the security tab, generate an access key and secret key (Keep it safe as we need it in later part of the tutorial)
Now we all are all set to proceed with the next step. So, whenever a file gets uploaded in the bucket, we need to send it to AWS Comprehend and receive the sentiment of each tweet and populate the data in Dynamo DB. So we need three things here.
Navigate to S3 console and create new bucket name it as “covidsentimenttwitter” or any name as you wish. This is where our dataset will be uploaded.
Navigate to DynamoDB console and on the side navigation pane, click Tables. Create a new table with “text” as the partition key. Also, note down the region where the table is created. In this tutorial, my table “covidsentiment” is created in “us-east-2” region.

The lambda function is going to act as a bridge between S3 object and Dynamo DB table.
Navigate to Lambda function console and click create function.
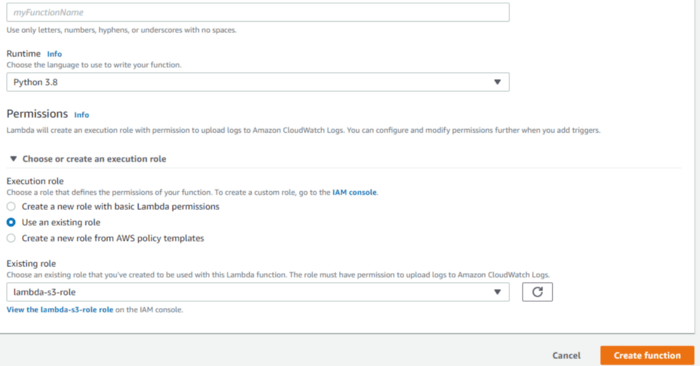
Give a suitable name and choose Python 3.8 as runtime. Under Permissions, click “Use an existing role” and select the role which we had created earlier in this tutorial.
Navigate to Lambda function console and click create function.
Give a suitable name and choose Python 3.8 as runtime. Under Permissions, click “Use an existing role” and select the role which we had created earlier in this tutorial.
Once the function is created, navigate inside it. In the Designer Pane, click Add Trigger. In Trigger Configuration, select S3 and select the bucket name which we had created earlier. Set the event type as “All Object create event”. So whenever a new object is created in the S3 bucket, this lambda function will be triggered.
Also, set the execution timeout for lambda function as 15 minutes.
Now we need to identify the sentiment of the tweet in the uploaded file and write the data to Dynamo DB. Run the following code under the function code of the lambda function. Replace the name of the bucket, table name as per your configuration and save the function. The lambda function code is as below.
Also, set the execution timeout for lambda function as 15 minutes.
Now we need to identify the sentiment of the tweet in the uploaded file and write the data to Dynamo DB. Run the following code under the function code of the lambda function. Replace the name of the bucket, table name as per your configuration and save the function. The lambda function code is as below.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import os | |
| import json | |
| import boto3 | |
| import csv | |
| from boto3.dynamodb.conditions import Key, Attr | |
| comprehend = boto3.client('comprehend') | |
| dynamodb = boto3.resource('dynamodb') | |
| table = dynamodb.Table('covidsentiment') | |
| print("Loading function") | |
| def lambda_handler(event, context): | |
| """Read file from s3 on trigger.""" | |
| s3 = boto3.client("s3") | |
| if event: | |
| file_obj = event["Records"][0] | |
| bucketname = str(file_obj['s3']['bucket']['name']) | |
| filename = str(file_obj['s3']['object']['key']) | |
| print("Filename: ", filename) | |
| fileObj = s3.get_object(Bucket=bucketname, Key=filename) | |
| file_content = fileObj["Body"].read().decode('utf-8').splitlines(True) | |
| print(file_content) | |
| recList = list() | |
| reader = csv.DictReader(file_content) | |
| for row in reader: | |
| # csv_header_key is the header keys which you have defined in your csv header | |
| # print(row['text']) | |
| table.put_item( | |
| Item={ | |
| 'text': row['text'], | |
| 'location': row['location'], | |
| 'phase': row['phase'], | |
| 'sentiment': comprehend.detect_sentiment(Text=row['text'],LanguageCode='en')['Sentiment'] | |
| } | |
| ) | |
Now you can upload all three dataset files in S3 bucket. You can monitor the lambda function and view the output logs by switching to the Monitoring tab in the lambda function. You can view the populated items in the Dynamo DB under Items tab in Dynamo DB console.
Once the data is populated, we can simply export the whole Dynamo DB data as CSV. Install the AWS CLI, and jq library in your local machine, if you don't have it.
In your terminal, type
In your terminal, type
$ aws configureEnter the Access ID, Secret key, Region name which we had created earlier.
Execute the following command to export the Dynamo DB. Replace the table name as per your config.
Execute the following command to export the Dynamo DB. Replace the table name as per your config.
$ aws dynamodb scan — table-name covidsentiment — select ALL_ATTRIBUTES — page-size 500 — max-items 100000 — output json | jq -r “.Items” | jq -r “(.[0] | keys_unsorted) as $keys | $keys, map([.[ $keys[] ].S])[] | @csv” > table.csvNavigate to AWS QuickSight. Under the Analysis tab, click New Analysis -> New Dataset -> Upload a file. Click and upload the exported Dynamo DB data CSV file.
Once the dataset is imported, Click Add Visual and then select your preferred graph and set the relevant Axis, filters and play with it.
Once the dataset is imported, Click Add Visual and then select your preferred graph and set the relevant Axis, filters and play with it.


Once you have derived meaningful insights with the data, you can publish the QuickSight dashboard.
Voila, we have built a dashboard to visualize the sentiment of the twitter during COVID-19 pandemic.
If you have reached this part of the article, do like and share and follow me for more articles on AI and Cloud.