
18
Identifying Suspicious URLs using Supervised Learning and Lexical Analysis
At present, the worldwide web platform has become very popular for online criminal activities like identity theft, extortion, insurance frauds, auction frauds etc and these activities happen through various ways like by sending phishing emails, via malicious URLs, sending fake text messages etc. According to Google every month they are blacklisting more than 50,000 URLs containing malware and over 90,000 phishing websites. Therefore, it is crucial to detect malicious URLs from the internet and blacklist them from being exposed to various attacks by the users. A specific URL can be categorised into various types, but this article aims at 5 types namely Spam URLs, Phishing URLs, Malware URLs, Defacement URLs and Benign URLs. The Benign URLs are the trusted websites whereas all other mentioned URLs are Malicious URLs. Generally classifying an URL will be limited to whether it is a spam or benign URL but there are different types of URLs as mentioned above based on various features. The URL identification is a multi-classification problem, and this can be done by using various algorithms that are present in Machine Learning. This article mainly focuses on KNN Algorithm.
The Dataset can be downloaded from the following link:-
https://www.kaggle.com/ruthvikrajamv/identifying-suspiciousurlsmllexical-analysis.
https://www.kaggle.com/ruthvikrajamv/identifying-suspiciousurlsmllexical-analysis.
The Dataset consists of more than 60,000 URLs and 80 different Lexical features like the length of the hostname, URL length, tokens that are found in the URL etc which are initially collected containing benign and malicious URLs in four different categories as Spam, Malware, Phishing and Defacement. There are four different files in the dataset and each file consists of benign and a single class among malicious URLs. Initially, pre-processing of data is done to remove null and noisy data then, Binary Classification is implemented on each category to test the algorithm and to extract the important features that affect the output variable. Finally, all the files are combined and shuffled to do the Multi-Classification.

[Execute Spam and Benign, Phishing and Benign, Malware and Benign and Defacement and Benign in separate cells]
# Importing all the necessary libraries
import pandas as pd
import numpy as np
import time
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import shuffle
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, f1_score
# Loading Malware, Spam, Phishing and Defacement Datasets
# Each Dataset also consists of Benign URL's
malware=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Malware.csv")
spam=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Spam.csv")
phishing=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Phishing.csv")
defacement=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Defacement.csv")
# Data Cleaning: Strip whitespaces from the column names and drop NA values
malware = malware.rename(str.strip, axis='columns')
spam=spam.rename(str.strip, axis="columns")
phishing=phishing.rename(str.strip, axis="columns")
defacement=defacement.rename(str.strip, axis="columns")
malware.info() # NumerRate_Extension values are missing for most of the rows
spam.info() # NumerRate_Extension values are missing for most of the rows
phishing.info() # NumerRate_Extension values are missing for most of the rows
defacement.info() # Entropy_DirectoryName and NumberRate_Extension values are missing for most of the rows
## Malware and Benign ##
# In Malware Dataset nearly 40% of values are NULL values in the NumberRate_Extension column
malware1=malware.drop(["NumberRate_Extension"], axis=1)
malware1=malware1.dropna()
malware1=shuffle(malware1)
malware1=malware1.reset_index(drop=True)
malware1.info()
# Functions:-
# If URL_Type_obf_Type == "malware" [class label 0], else [class label 1]
# Function to label the classes in a DataFrame
def class_labels_malware(class_name):
if(class_name=="malware"):
return 0
else:
return 1
# Function for Data Scaling
def dataset_scaling(dataset):
# Scaling dataset
scaler = MinMaxScaler(feature_range=(0, 1)) # Scaling object for features
df_X = dataset.loc[:, dataset.columns!="URL_Type_obf_Type"]
df_Y = dataset[["URL_Type_obf_Type"]]
df_X = scaler.fit_transform(df_X)
dataset1=np.concatenate((df_X, df_Y), axis=1)
return dataset1, scaler
malware1["URL_Type_obf_Type"]=malware1["URL_Type_obf_Type"].apply(lambda x:class_labels_malware(x))
# Mapping the classes with their respective labels
malware_columns=malware1.columns
malware2, scaler=dataset_scaling(malware1) # Scaling the Dataset
malware2=pd.DataFrame(malware2,columns=malware_columns)
# After, performing scaling the output will be of type array so storing it as a DataFrame
# Splitting the samples
train_x, test_x, train_y, test_y=train_test_split(malware2.loc[:, malware2.columns!="URL_Type_obf_Type"], malware2["URL_Type_obf_Type"], random_state=0, test_size=0.25)
# Machine Learning Models
start = time.time()
knn=KNeighborsClassifier(n_neighbors=7)
knn.fit(train_x, train_y)
predicted_test=knn.predict(test_x)
end = time.time()
print((end-start)) # Prints Time taken by the Model to train and execute the samples in seconds
# Predicting the Output for Train data
predicted_train=knn.predict(train_x)
# Performance Metrics
print(accuracy_score(test_y, predicted_test) * 100) # 98.4% for testing
print(accuracy_score(train_y, predicted_train) * 100) # 99% for training
print(f1_score(test_y, predicted_test)) # f1 score for test data -> 0.98
# Invert Input Variables[Optional] -> Apply similar code further if we want to Invert the Input Variables
X_invert=scaler.inverse_transform(malware2.loc[:, malware2.columns!="URL_Type_obf_Type"])
train_x_invert=scaler.inverse_transform(train_x)
test_x_invert=scaler.inverse_transform(test_x)
## Spam and Benign ##
# In Spam Dataset nearly 34% of values are NULL values in the NumberRate_Extension column
spam1=spam.drop(["NumberRate_Extension"], axis=1)
spam1=spam1.dropna()
spam1=shuffle(spam1)
spam1=spam1.reset_index(drop=True)
spam1.info()
# If URL_Type_obf_Type == "spam" [class label 0], else [class label 1]
# Function to label the classes in a DataFrame
def class_labels_spam(class_name):
if(class_name=="spam"):
return 0
else:
return 1
spam1["URL_Type_obf_Type"]=spam1["URL_Type_obf_Type"].apply(lambda x:class_labels_spam(x))
spam_columns=spam1.columns
spam2, scaler=dataset_scaling(spam1) # Scaling the Dataset
spam2=pd.DataFrame(spam2,columns=spam_columns)
# Splitting the samples
train_x, test_x, train_y, test_y=train_test_split(spam2.loc[:, spam2.columns!="URL_Type_obf_Type"], spam2["URL_Type_obf_Type"], random_state=0, test_size=0.25)
# Machine Learning Models
start = time.time()
knn=KNeighborsClassifier(n_neighbors=7)
knn.fit(train_x, train_y)
predicted_test=knn.predict(test_x)
end = time.time()
print((end-start)) # Prints Time taken by the Model to train and execute the samples in seconds
# Predicting the Output
predicted_train=knn.predict(train_x)
# Performance Metrics
print(accuracy_score(test_y, predicted_test) * 100) # 99.4% for testing
print(accuracy_score(train_y, predicted_train) * 100) # 99.5% for training
# Takes around 1.15 seconds
print(f1_score(test_y, predicted_test)) # f1 score for test data -> 0.99
## Phishing and Benign ##
# In Phishing Dataset nearly 48% of values are NULL values in the NumberRate_Extension column
phishing1=phishing.drop(["NumberRate_Extension"], axis=1)
phishing1=phishing1.dropna()
phishing1=shuffle(phishing1)
phishing1=phishing1.reset_index(drop=True)
phishing1.info()
# If URL_Type_obf_Type == "phishing" [class label 0], else [class label 1]
# Function to label the classes in a DataFrame
def class_labels_phishing(class_name):
if(class_name=="phishing"):
return 0
else:
return 1
phishing1["URL_Type_obf_Type"]=phishing1["URL_Type_obf_Type"].apply(lambda x:class_labels_phishing(x))
phishing_columns=phishing1.columns
phishing2, scaler=dataset_scaling(phishing1) # Scaling the Dataset
phishing2=pd.DataFrame(phishing2,columns=phishing_columns)
# Splitting the samples
train_x, test_x, train_y, test_y=train_test_split(phishing2.loc[:, phishing2.columns!="URL_Type_obf_Type"], phishing2["URL_Type_obf_Type"], random_state=0, test_size=0.25)
# Machine Learning Models
start = time.time()
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(train_x, train_y)
predicted_test=knn.predict(test_x)
end = time.time()
print((end-start)) # Prints Time taken by the Model to train and execute the samples in seconds
# Predicting the Output
predicted_train=knn.predict(train_x)
# Performance Metrics
print(accuracy_score(test_y, predicted_test) * 100) # 96.4% for testing
print(accuracy_score(train_y, predicted_train) * 100) # 97.4% for training
print(f1_score(test_y, predicted_test)) # f1 score for test data -> 0.96
## Defacement and Benign ##
# In Defacement Dataset nearly 39% of values are NULL values in the Entropy_DirectoryName
# and 32% of values are NULL values in the NumberRate_Extension column
# If we are using the dropna() on the Defacement Dataset, the number of rows falls from
# 15711 to 5186 rows but if we drop the above two columns and apply dropna() then the number
# of rows reduces from 15711 to 15477 so, better to drop the two columns
defacement1=defacement.drop(["NumberRate_Extension", "Entropy_DirectoryName"], axis=1)
defacement1=defacement1.dropna()
defacement1=shuffle(defacement1)
defacement1=defacement1.reset_index(drop=True)
defacement1.info()
# If URL_Type_obf_Type == "Defacement" [class label 0], else [class label 1]
# Function to label the classes in a DataFrame
def class_labels_defacement(class_name):
if(class_name=="Defacement"):
return 0
else:
return 1
defacement1["URL_Type_obf_Type"]=defacement1["URL_Type_obf_Type"].apply(lambda x:class_labels_defacement(x))
defacement_columns=defacement1.columns
defacement2, scaler=dataset_scaling(defacement1) # Scaling the Dataset
defacement2=pd.DataFrame(defacement2,columns=defacement_columns)
# Splitting the samples
train_x, test_x, train_y, test_y=train_test_split(defacement2.loc[:, defacement2.columns!="URL_Type_obf_Type"], defacement2["URL_Type_obf_Type"], random_state=0, test_size=0.25)
# Machine Learning Models
start = time.time()
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(train_x, train_y)
predicted_test=knn.predict(test_x)
end = time.time()
print((end-start)) # Prints Time taken by the Model to train and execute the samples in seconds
# Predicting the Output
predicted_train=knn.predict(train_x)
# Performance Metrics
print(accuracy_score(test_y, predicted_test) * 100) # 99.1% for testing
print(accuracy_score(train_y, predicted_train) * 100) # 99.5% for training
# When k=5, 99.1% and 99.5% for test and train data and takes 1.33 seconds to execute
print(f1_score(test_y, predicted_test)) # f1 score for test data -> 0.99import pandas as pd
import numpy as np
import time
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import shuffle
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, f1_score
from sklearn.decomposition import PCA
# Loading Malware, Spam, Phishing and Defacement Datasets
# Each Dataset also consists of Benign URL's
malware=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Malware.csv")
spam=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Spam.csv")
phishing=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Phishing.csv")
defacement=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Defacement.csv")
# all_files=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/All.csv")
# Data Cleaning: Strip whitespaces from the column names and drop NA values
malware = malware.rename(str.strip, axis='columns')
spam=spam.rename(str.strip, axis="columns")
phishing=phishing.rename(str.strip, axis="columns")
defacement=defacement.rename(str.strip, axis="columns")
malware.info() # NumerRate_Extension values are missing for most of the rows
spam.info() # NumerRate_Extension values are missing for most of the rows
phishing.info() # NumerRate_Extension values are missing for most of the rows
defacement.info() # Entropy_DirectoryName and NumberRate_Extension values are missing for most of the rows
#########################################################################
# BINARY CLASSIFICATION (Using a subset of Samples)
## Malware and Benign ##
# In Malware Dataset nearly 40% of values are NULL values in the NumberRate_Extension column
malware1=malware.drop(["NumberRate_Extension"], axis=1)
malware1=malware1.dropna()
malware1=shuffle(malware1)
malware1=malware1.reset_index(drop=True)
malware1.info()
# If URL_Type_obf_Type == "malware" [class label 0], else [class label 1]
# Function to label the classes in a DataFrame
def class_labels_malware(class_name):
if(class_name=="malware"):
return 0
else:
return 1
# Function for Data Scaling
def dataset_scaling(dataset):
# Scaling dataset
scaler = MinMaxScaler(feature_range=(0, 1)) # Scaling object for features
df_X = dataset.loc[:, dataset.columns!="URL_Type_obf_Type"]
df_Y = dataset[["URL_Type_obf_Type"]]
df_X = scaler.fit_transform(df_X)
dataset1=np.concatenate((df_X, df_Y), axis=1)
return dataset1, scaler
# Function for appending the column indices with correlation value closer to 0
def columns_lowcorr(corr, columns):
index_lowcorr=[]
for i in range(0, corr.shape[1]):
if((-0.1 < corr.iloc[-1,i] < 0.1) or (pd.isnull(corr.iloc[-1,i]))):
print(columns[-1],"and",columns[i],"with Correlation",round(corr.iloc[-1][i],2))
index_lowcorr.append(i)
return index_lowcorr
# Function for appending the features with high correlation
def columns_highcorr(corr, columns):
index_highcorr=[]
for i in range(0, corr.shape[0]-1):
for j in range(i, corr.shape[1]-1):
if(0.8<=corr.iloc[i][j]<1):
print(columns[i],"and",columns[j],"with Correlation",round(corr.iloc[i][j],2))
if(i not in index_highcorr):
index_highcorr.append(i);
return index_highcorr
# Function to determine the final Index column indices with low and high correlation values
def final_index(index_lowcorr, index_highcorr):
index=[]
for i in index_lowcorr:
if i not in index:
index.append(i)
for j in index_highcorr:
if j not in index:
index.append(j)
index.sort()
return index
malware1["URL_Type_obf_Type"]=malware1["URL_Type_obf_Type"].apply(lambda x:class_labels_malware(x))
malware_columns=malware1.columns
corr=malware1.corr()
# Removing all the columns with correlation almost equal to 0 ->
# Which shows no impact on the O/P variable and the features with High Correlation
index_malware_lowcorr=columns_lowcorr(corr, malware_columns)
index_malware_highcorr=columns_highcorr(corr, malware_columns)
index_malware=final_index(index_malware_lowcorr, index_malware_highcorr)
malware3=malware1.drop(columns=malware_columns[[index_malware]])
malware2, scaler=dataset_scaling(malware3) # Scaling the Dataset
malware2=pd.DataFrame(malware2,columns=malware3.columns)
# Principal Component Analysis
# Separating the input and output features
X=malware2.loc[:, malware2.columns!="URL_Type_obf_Type"]
y=malware2["URL_Type_obf_Type"]
# Let's say, components = 10
pca = PCA(n_components = 10)
pca.fit(X)
X_pca = pca.transform(X)
# Splitting the samples
train_x, test_x, train_y, test_y=train_test_split(X_pca, y, random_state=0, test_size=0.25)
# Machine Learning Models
start = time.time()
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(train_x, train_y)
predicted_test=knn.predict(test_x)
end = time.time()
print((end-start)) # Prints Time taken by the Model to train and execute the samples in seconds
# Predicting the Output
predicted_train=knn.predict(train_x)
# Performance Metrics
accuracy_score(test_y, predicted_test) * 100 # 97.7% for testing
accuracy_score(train_y, predicted_train) * 100 # 98.5% for training
# Using PCA it took only 0.18 seconds
f1_score(test_y, predicted_test) # f1 score for test data -> 0.98
## Spam and Benign ##
# In Spam Dataset nearly 34% of values are NULL values in the NumberRate_Extension column
spam1=spam.drop(["NumberRate_Extension"], axis=1)
spam1=spam1.dropna()
spam1=shuffle(spam1)
spam1=spam1.reset_index(drop=True)
spam1.info()
# If URL_Type_obf_Type == "spam" [class label 0], else [class label 1]
# Function to label the classes in a DataFrame
def class_labels_spam(class_name):
if(class_name=="spam"):
return 0
else:
return 1
spam1["URL_Type_obf_Type"]=spam1["URL_Type_obf_Type"].apply(lambda x:class_labels_spam(x))
spam_columns=spam1.columns
corr=spam1.corr()
# Removing all the columns with correlation almost equal to 0 ->
# Which shows no impact on the O/P variable and the features with High Correlation
index_spam_lowcorr=columns_lowcorr(corr, spam_columns)
index_spam_highcorr=columns_highcorr(corr, spam_columns)
index_spam=final_index(index_spam_lowcorr, index_spam_highcorr)
spam3=spam1.drop(columns=spam_columns[[index_spam]])
spam2, scaler=dataset_scaling(spam3) # Scaling the Dataset
spam2=pd.DataFrame(spam2,columns=spam3.columns)
# Principal Component Analysis
# Separating the input and output features
X=spam2.loc[:, spam2.columns!="URL_Type_obf_Type"]
y=spam2["URL_Type_obf_Type"]
# Let's say, components = 6
pca = PCA(n_components = 6)
pca.fit(X)
X_pca = pca.transform(X)
# Splitting the samples
train_x, test_x, train_y, test_y=train_test_split(X_pca, y, random_state=0, test_size=0.25)
# Machine Learning Models
start = time.time()
knn=KNeighborsClassifier(n_neighbors=7)
knn.fit(train_x, train_y)
predicted_test=knn.predict(test_x)
end = time.time()
print((end-start)) # Prints Time taken by the Model to train and execute the samples in seconds
# Predicting the Output
predicted_train=knn.predict(train_x)
# Performance Metrics
accuracy_score(test_y, predicted_test) * 100 # 99.1% for testing
accuracy_score(train_y, predicted_train) * 100 # 99.3% for training
# Using PCA it takes around 0.14 seconds only
f1_score(test_y, predicted_test) # f1 score for test data -> 0.99
## Phishing and Benign ##
# In Phishing Dataset nearly 48% of values are NULL values in the NumberRate_Extension column
phishing1=phishing.drop(["NumberRate_Extension"], axis=1)
phishing1=phishing1.dropna()
phishing1=shuffle(phishing1)
phishing1=phishing1.reset_index(drop=True)
phishing1.info()
# If URL_Type_obf_Type == "phishing" [class label 0], else [class label 1]
# Function to label the classes in a DataFrame
def class_labels_phishing(class_name):
if(class_name=="phishing"):
return 0
else:
return 1
phishing1["URL_Type_obf_Type"]=phishing1["URL_Type_obf_Type"].apply(lambda x:class_labels_phishing(x))
phishing_columns=phishing1.columns
corr=phishing1.corr()
# Removing all the columns with correlation almost equal to 0 ->
# Which shows no impact on the O/P variable and the features with High Correlation
index_phishing_lowcorr=columns_lowcorr(corr, phishing_columns)
index_phishing_highcorr=columns_highcorr(corr, phishing_columns)
index_phishing=final_index(index_phishing_lowcorr, index_phishing_highcorr)
phishing3=phishing1.drop(columns=phishing_columns[[index_phishing]])
phishing2, scaler=dataset_scaling(phishing3) # Scaling the Dataset
phishing2=pd.DataFrame(phishing2,columns=phishing3.columns)
# Principal Component Analysis
# Separating the input and output features
X=phishing2.loc[:, phishing2.columns!="URL_Type_obf_Type"]
y=phishing2["URL_Type_obf_Type"]
# Let's say, components = 10
pca = PCA(n_components = 10)
pca.fit(X)
X_pca = pca.transform(X)
# Splitting the samples
train_x, test_x, train_y, test_y=train_test_split(X_pca, y, random_state=0, test_size=0.25)
# Machine Learning Models
start = time.time()
knn=KNeighborsClassifier(n_neighbors=9)
knn.fit(train_x, train_y)
predicted_test=knn.predict(test_x)
end = time.time()
print((end-start)) # Prints Time taken by the Model to train and execute the samples in seconds
# Predicting the Output
predicted_train=knn.predict(train_x)
# Performance Metrics
accuracy_score(test_y, predicted_test) * 100 # 96.45% for testing
accuracy_score(train_y, predicted_train) * 100 # 96.6% for training
# Using PCA it takes around 0.23 seconds only
f1_score(test_y, predicted_test) # f1 score for test data -> 0.96
## Defacement and Benign ##
# In Defacement Dataset nearly 39% of values are NULL values in the Entropy_DirectoryName
# and 32% of values are NULL values in the NumberRate_Extension column
# If we are using the dropna() on the Defacement Dataset, the number of rows falls from
# 15711 to 5186 rows but if we drop the above two columns and apply dropna() then the number
# of rows reduces from 15711 to 15477 so, better to drop the two columns
defacement1=defacement.drop(["NumberRate_Extension", "Entropy_DirectoryName"], axis=1)
defacement1=defacement1.dropna()
defacement1=shuffle(defacement1)
defacement1=defacement1.reset_index(drop=True)
defacement1.info()
# If URL_Type_obf_Type == "Defacement" [class label 0], else [class label 1]
# Function to label the classes in a DataFrame
def class_labels_defacement(class_name):
if(class_name=="Defacement"):
return 0
else:
return 1
defacement1["URL_Type_obf_Type"]=defacement1["URL_Type_obf_Type"].apply(lambda x:class_labels_defacement(x))
defacement_columns=defacement1.columns
corr=defacement1.corr()
# Removing all the columns with correlation almost equal to 0 ->
# Which shows no impact on the O/P variable and the features with High Correlation
index_defacement_lowcorr=columns_lowcorr(corr, defacement_columns)
index_defacement_highcorr=columns_highcorr(corr, defacement_columns)
index_defacement=final_index(index_defacement_lowcorr, index_defacement_highcorr)
defacement3=defacement1.drop(columns=defacement_columns[[index_defacement]])
defacement2, scaler=dataset_scaling(defacement3) # Scaling the Dataset
defacement2=pd.DataFrame(defacement2,columns=defacement3.columns)
# Principal Component Analysis
# Separating the input and output features
X=defacement2.loc[:, defacement2.columns!="URL_Type_obf_Type"]
y=defacement2["URL_Type_obf_Type"]
# Let's say, components = 10
pca = PCA(n_components = 10)
pca.fit(X)
X_pca = pca.transform(X)
# Splitting the samples
train_x, test_x, train_y, test_y=train_test_split(X_pca, y, random_state=0, test_size=0.25)
# Machine Learning Models
start = time.time()
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(train_x, train_y)
predicted_test=knn.predict(test_x)
end = time.time()
print((end-start)) # Prints Time taken by the Model to train and execute the samples in seconds
# Predicting the Output
predicted_train=knn.predict(train_x)
# Performance Metrics
accuracy_score(test_y, predicted_test) * 100 # 99% for testing
accuracy_score(train_y, predicted_train) * 100 # 99.5% for training
# Using PCA it takes around 0.24 seconds only
f1_score(test_y, predicted_test) # f1 score for test data -> 0.99
# When we try to reduce the n_components value of PCA the accuracy score is also getting
# reduced Hence, better value is chosen to capture the variability of the featuresl=[0]*78 # Creating an Empty list of size -> Number of features
# Counting the features that has appeared for how many times in all the four Dataframes
for i in index_defacement:
l[i]=l[i]+1;
for j in index_malware:
l[j]=l[j]+1;
for k in index_spam:
l[k]=l[k]+1;
for m in index_phishing:
l[m]=l[m]+1;
# Extracting the feature indices that has appeared in all the Dataframes for most of the times
columns=malware1.columns # Column names and it respective indices
names_columns_worst=[] # Names of columns that are useless
for i in range(0,78):
if(l[i]==4 or l[i]==3):
names_columns_worst.append(columns[i])
names_columns_worst.remove("Entropy_DirectoryName") # Removing this feature explicitly because in further
# analysis the feature "Entropy_DirectoryName" will be explicitly dropped from all the Dataframes
print(names_columns_worst)
# Thereby from above it is clear that there are 46 features that shows no impact on the Output variableimport pandas as pd
import numpy as np
import time
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.utils import shuffle
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, f1_score
from sklearn.decomposition import PCA
# Loading Malware, Spam, Phishing and Defacement Datasets
# Each Dataset also consists of Benign URL's
malware=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Malware.csv")
spam=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Spam.csv")
phishing=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Phishing.csv")
defacement=pd.read_csv("/Users/ruthvikrajam.v/Desktop/ENGG*6600 Project/FinalDataset/Defacement.csv")
# Data Cleaning: Strip whitespaces from the column names and drop NA values
malware = malware.rename(str.strip, axis='columns')
spam=spam.rename(str.strip, axis="columns")
phishing=phishing.rename(str.strip, axis="columns")
defacement=defacement.rename(str.strip, axis="columns")
malware.info() # NumerRate_Extension values are missing for most of the rows
spam.info() # NumerRate_Extension values are missing for most of the rows
phishing.info() # NumerRate_Extension values are missing for most of the rows
defacement.info() # Entropy_DirectoryName and NumberRate_Extension values are missing for most of the rows
# In Malware Dataset nearly 40% of values are NULL values in the NumberRate_Extension column
# and also from the Binary classification analysis it is clear that the Entropy_DirectoryName has no
# impact on the output column so, dropping the column NumberRate_Extension from Spam, Malware and
# Phishing Datasets
malware1=malware.drop(["NumberRate_Extension", "Entropy_DirectoryName"], axis=1)
malware1=malware1.dropna()
malware1=shuffle(malware1)
malware1=malware1.reset_index(drop=True)
malware1.info()
# In Spam Dataset nearly 34% of values are NULL values in the NumberRate_Extension column
spam1=spam.drop(["NumberRate_Extension", "Entropy_DirectoryName"], axis=1)
spam1=spam1.dropna()
spam1=shuffle(spam1)
spam1=spam1.reset_index(drop=True)
spam1.info()
# In Phishing Dataset nearly 48% of values are NULL values in the NumberRate_Extension column
phishing1=phishing.drop(["NumberRate_Extension", "Entropy_DirectoryName"], axis=1)
phishing1=phishing1.dropna()
phishing1=shuffle(phishing1)
phishing1=phishing1.reset_index(drop=True)
phishing1.info()
# In Defacement Dataset nearly 39% of values are NULL values in the Entropy_DirectoryName
# and 32% of values are NULL values in the NumberRate_Extension column
defacement1=defacement.drop(["NumberRate_Extension", "Entropy_DirectoryName"], axis=1)
defacement1=defacement1.dropna()
defacement1=shuffle(defacement1)
defacement1=defacement1.reset_index(drop=True)
defacement1.info()
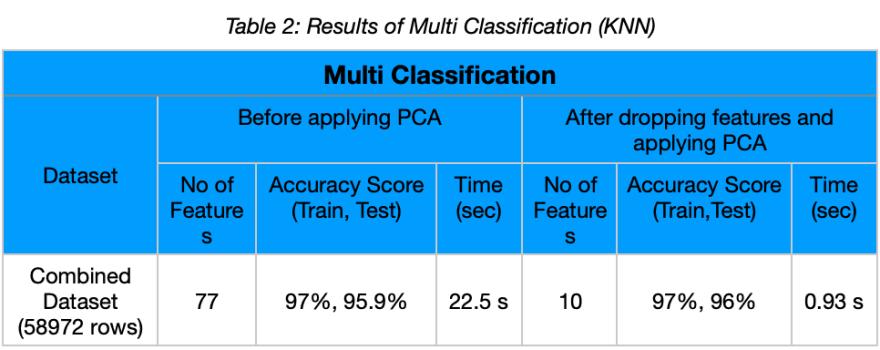
# The final Dataset consists of 58972 rows, 77 features and 1 output feature
# Appending all the DataFrames along rows
all_files=np.concatenate((malware1, spam1, phishing1, defacement1), axis=0)
all_files=pd.DataFrame(all_files, columns=malware1.columns)
all_files.info()
# Function for Data Scaling
def dataset_scaling(dataset):
# Scaling dataset
scaler = MinMaxScaler(feature_range=(0, 1)) # Scaling object for features
df_X = dataset.loc[:, dataset.columns!="URL_Type_obf_Type"]
df_Y = dataset[["URL_Type_obf_Type"]]
df_X = scaler.fit_transform(df_X)
dataset1=np.concatenate((df_X, df_Y), axis=1)
return dataset1, scaler
# Function for appending the features with high correlation
def columns_highcorr(corr, columns):
index_highcorr=[]
for i in range(0, corr.shape[0]):
for j in range(i, corr.shape[1]):
if(0.8<=corr.iloc[i][j]<1):
print(columns[i],"and",columns[j],"with Correlation",round(corr.iloc[i][j],2))
if(i not in index_highcorr):
index_highcorr.append(i);
return index_highcorr
# From the Previous Analysis it is clear that there are 45 features with no impact on the output variable
# So, dropping all the 45 columns from the final Dataset
names_columns_worst=['Querylength', 'path_token_count', 'avgdomaintokenlen', 'longdomaintokenlen',
'avgpathtokenlen', 'charcompvowels', 'charcompace', 'ldl_url', 'ldl_path',
'ldl_filename', 'ldl_getArg', 'dld_url', 'dld_domain', 'dld_path',
'dld_filename', 'urlLen', 'domainlength', 'pathLength', 'subDirLen',
'this.fileExtLen', 'ArgLen', 'pathurlRatio', 'ArgUrlRatio', 'argDomanRatio',
'argPathRatio', 'executable', 'isPortEighty', 'ISIpAddressInDomainName',
'LongestVariableValue', 'URL_DigitCount', 'host_DigitCount', 'Directory_DigitCount',
'Extension_DigitCount', 'Query_LetterCount', 'Path_LongestWordLength', 'URL_sensitiveWord',
'URLQueries_variable', 'spcharUrl', 'delimeter_Count', 'NumberRate_Domain', 'NumberRate_DirectoryName',
'NumberRate_AfterPath', 'SymbolCount_URL', 'SymbolCount_FileName', 'SymbolCount_Extension']
all_files1=all_files.drop(columns=names_columns_worst)
# Saving the above Dataframe as a csv file and loading it for further evaluation
all_files1.to_csv("/Users/ruthvikrajam.v/Desktop/All Files.csv",index=False)
all_files1=pd.read_csv("/Users/ruthvikrajam.v/Desktop/All Files.csv")
# Checking further if there are any features with high Correlation
corr=all_files1.corr()
index_allfiles_highcorr=columns_highcorr(corr, corr.columns)
all_files2=all_files1.drop(columns=corr.columns[index_allfiles_highcorr])
# 58,972 rows and 27 columns
# Assigning labels to the classes
all_files3=all_files2.copy() # Modifications done in all_files3 wont be reflected in all_files2
all_files3["URL_Type_obf_Type"]=all_files3["URL_Type_obf_Type"].map({"Defacement":0, "benign":1, "malware":2, "phishing":3, "spam":4 })
# Scaling the Dataset
all_files4, scaler=dataset_scaling(all_files3)
all_files4=pd.DataFrame(all_files4, columns=all_files3.columns)
# Principal Component Analysis -> Dimensionality Reduction
# Separating the input and output features
X=all_files4.loc[:, all_files4.columns!="URL_Type_obf_Type"]
y=all_files4["URL_Type_obf_Type"]
# Let's say, components = 10
pca = PCA(n_components = 10)
pca.fit(X)
X_pca = pca.transform(X)
# Splitting the samples
train_x, test_x, train_y, test_y=train_test_split(X_pca, y, random_state=0, test_size=0.25)
# Machine Learning Models
start = time.time()
knn=KNeighborsClassifier(n_neighbors=5)
knn.fit(train_x, train_y)
predicted_test=knn.predict(test_x)
end = time.time()
print((end-start)) # Prints Time taken by the Model to train and execute the samples in seconds
# Predicting the Output
predicted_train=knn.predict(train_x)
# Performance Metrics
accuracy_score(test_y, predicted_test) * 100 # 96% for testing
accuracy_score(train_y, predicted_train) * 100 # 97% for training
# Time taken by PCA to execute -> 0.933 seconds18