
15
Autoencoders
If you are new to Deep learning, and would love to understand Neural Network Architecture or would like to tinker with CNN’s / ANN’s then autoencoder is the best point to start with. In this post, we will go through a quick Introduction to Autoencoders.
Visit — machine.learns — Here you can Visualize the working of Autoencoders in different configurations and more.
So before directly jumping into the technical details, let’s first see some of its applications.

Converting a Black and White Image to a Colored Image.

What is an Autoencoders?
Autoencoder is an Artificial Neural Network learning technique. It is an Unsupervised Learning Approach. It mainly helps in achieving representation learning i.e. we come up with an architecture that forces the model to learn a compressed representation of the input data.
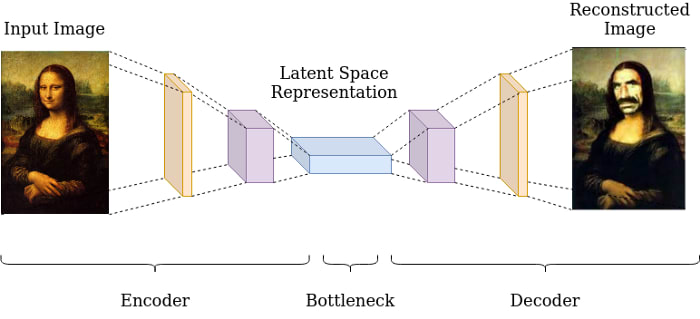
This compressed representation is also known as a bottleneck or latent representation. The bottleneck basically learns the features of the data, i.e. it learns to represent a particular data point based on a certain number of features. For example — if the input is a digit dataset then it may learn features like no of horizontal and vertical edges and based on these features it identifies each data point.
Latent Representation (Bottleneck)
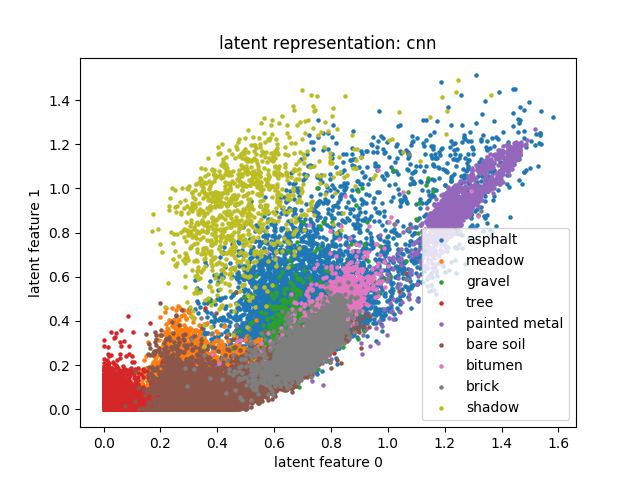
The above figure is a plot of Latent space or Bottleneck
We can see clusters of similar colors. Each cluster above is representing similar types of objects example the blue dots are representing asphalt etc.
It is important to know that each dot is representing a unique type of object.
So in total, we can divide an Autoencoder into three parts
It is important to know that each dot is representing a unique type of object.
So in total, we can divide an Autoencoder into three parts
Conclusion
Despite being a very basic architecture it helps a lot in understanding the various concepts of Neural networks and their architectures. So I will highly encourage you two to learn the implementation of Autoencoders too.
Hope you would have learned something valuable.
Hope you would have learned something valuable.
15