
27
TORCHSERVE ON AWS
This series walks you through the necessary information and AWS hands-on learning experience to further your understanding of the PyTorch model serving on AWS.
We begin by introducing you to PyTorch and TorchServe and then give you your hands-on experience using TorchServe in many different environments.
Specifically, we take you several different types of deployment:
Deployment of a custom model on Amazon SageMaker using a Docker container. This is also known as a “bring your own container” or BYOC deployment.
Deployment that uses the Amazon SageMaker SDK for natively model serving with TorchServe.
And, finally, deployment using the Amazon Elastic Kubernetes Service (Amazon EKS) service.
Using PyTorch’s TorchScript, developers can seamlessly transition between eager mode, which performs computations immediately for easy development, and graph mode which creates computational graphs for efficient execution in production environments.
PyTorch supports dynamic computation graphs, which provide a flexible structure that is intuitive to work with and easy to debug.
PyTorch also offers distributed training, deep integration into Python, and a rich ecosystem of tools and libraries, making it popular with researchers and engineers.
It started as a GPU-accelerated tensor library with an API relatively similar to NumPy. It evolved from a framework called Torch, written in Lua, that people really liked because of the imperative style of neural network construction that Torch gave you.
However, some looked at learning Lua as a barrier to entry to deep learning and also wanted the modularity to interface with other libraries. AI Researchers at Facebook decided to implement Torch in Python because Python and called it “PyTorch”. PyTorch is now one of the most referenced and fastest-growing frameworks.

All deep learning frameworks view models as directed acyclic graphs. However, the frameworks differ in how they allow you to specify models.
TensorFlow and MXNet use static computation graphs, meaning that the computation graph must be defined and built before it’s run.
In contrast, PyTorch uses dynamic computational graphs. This means that models are imperatively specified by using idiomatic Python code, and then the computation graph is built and re-built during execution time. Rather than being predetermined, the graph’s structure can change during execution.
Additionally, PyTorch’s imperative nature makes debugging become easier as it would be an individual line of code that would fail and be readily exposed for immediate error reporting.
The way that a graph is defined in PyTorch is very similar to regular python execution. You define your operators, you can use operator overloads like this plus operator. A graph is defined based on how you ran it.

PyTorch is a first-class citizen on AWS. You can get started with PyTorch on AWS using Amazon SageMaker, a fully managed machine learning service that makes it easy and cost-effective to build, train, and deploy PyTorch models at scale.
If you prefer to manage the infrastructure yourself, you can use the AWS Deep Learning AMIs or the AWS Deep Learning Containers, which come pre-installed with PyTorch to quickly deploy custom machine learning environments.


Deploying machine learning models for inference at scale is not easy. Developers must collect and package model artifacts, install and configure software libraries for prediction, create and expose API endpoints, generate logs and metrics for monitoring, and manage multiple model versions on potentially multiple servers.
Each of these tasks is complex manual operations that can slow down model deployment by weeks or even months. PyTorch developers lacked a canonical, officially supported mechanism for deploying PyTorch models in production and at scale.
TorchServe solves the biggest pain point of PyTorch developers today by providing a full-featured model serving solution for deploying PyTorch models in production at scale.
TorchServe was developed by AWS and launched jointly with Facebook in April of 2020. AWS engineers are public maintainers of the project under PyTorch governance.
TorchServe is an open-source model serving framework for PyTorch that makes it easy to deploy trained PyTorch models performantly at scale without having to write custom code. TorchServe delivers lightweight serving with low latency, so you can deploy your models for high-performance inference.
It provides default handlers for the most common applications such as object detection and text classification, so you don’t have to write custom code to deploy your models.
With powerful TorchServe features including multi-model serving, model versioning for A/B testing, metrics for monitoring, and RESTful endpoints for application integration, you can take your models from research to production quickly.
TorchServe supports any machine learning environment, including Amazon SageMaker, Kubernetes, Amazon EKS, and Amazon EC2.

TorchServe can be used for many types of inference in production settings. It provides an easy-to-use command-line interface and utilizes REST-based APIs to handle state prediction requests. For example, you want to make an app that lets your users snap a picture, and it will tell them what objects were detected in the scene and predictions on what the objects might be.
You can use TorchServe to serve a prediction endpoint for object detection and identification model that intakes images, then returns predictions. You can also modify TorchServe behavior with custom services and run multiple models.
TorchServe takes a PyTorch deep learning model and it wraps it in a set of REST APIs. Currently, it comes with a built-in web server that you run from the command line. This command-line call takes in the single or multiple models you want to serve, along with additional optional parameters controlling the port, host, and logging. TorchServe supports running custom services to handle the specific inference handling logic.

Frontend: The request/response handling component of
TorchServe. This portion of the serving component handles both request/response coming from clients and manages the lifecycles of the models.
TorchServe. This portion of the serving component handles both request/response coming from clients and manages the lifecycles of the models.
Model Workers: These workers are responsible for running the actual inference on the models. These are actual running instances of the models.
Model: Models could be a script_module (JIT saved models) or eager_mode_models. These models can provide custom pre-and post-processing of data along with any other model artifacts such as state_dicts. Models can be loaded from cloud storage or from local hosts.
Plugins: These are custom endpoints or authz/authn or batching algorithms that can be dropped into TorchServe at startup time.
Model Store: This is a directory in which all the loadable models exist.
Once installed you can quickly start up a server by running " torchserve --start ". Once a server is running, you’ll get access to three sets of APIs:
Inference API - This allows you to query the health of the running server and is also how you get predictions from the served model.
Management API - allows you to register/unregister a model, specify the number of workers for a model, describe a model’s status, list registered models, and set the default version of a model.
Metrics API - Returns Prometheus formatted metrics.
All of these services are listening on port 8080, 8081, and 8082 respectively by default, but you can change that. You can deploy models running in both eager mode and touchscript. TorchScript uses Torch.JIT, a just-in-time compiler, to produce models that can be serialized and optimized from PyTorch code.
[1] To begin, sign in to your AWS console. You will be launching a CloudFormation (CF) template into one of the below regions.
[2] Next, click the ONLY ONE icon below to launch your CF Template.
[3] Check the three acknowledgment boxes and the orange ‘Create Stack’ button at the bottom as seen below:

[4] Once complete, ensure that you see you should see output similar to the following screen:

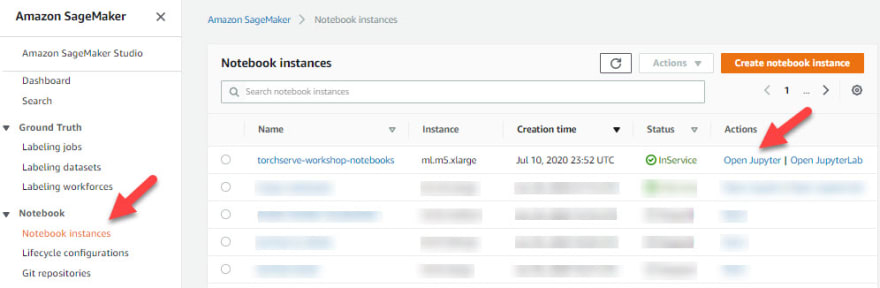
[5] Finally, head over to the Amazon SageMaker Console and click on Notebook Instances from the left navigation pane. Identify your newly created notebook and click the ‘Open Jupyter’ link as shown below:
With TorchServe, you get many features out-of-the-box. It gives you full flexibility of deploying trained PyTorch models performantly at scale without having to write custom handlers for popular models. You can go from a trained model to production deployment with just a few lines of code.
From your Jupyter notebook instance, please click on the ‘1_torchserve-install-and-inference’ folder and then open the torchserve-install-and-inference.ipynb Jupyter notebook.

27