
18
Web Scraping 101! Introduction to Web Scraping in Python.
Web Scraping makes it easier and faster when you have to pull a large amount of data from websites.
It is an automated method used to extract large amounts of data from websites.
The data on the websites are unstructured therefore Web scraping helps collect these unstructured data and store it in a structured form.
Job listings: Details regarding job openings, interviews are collected from different websites and then listed in one place so that it is easily accessible to the user.
Social Media Scraping: used to collect data from Social Media websites such as Twitter to find out what’s trending.
Email address gathering:companies that use email as a medium for marketing, use web scraping to collect email ID and then send bulk emails.
E-Commerce pricing:e-commerce sellers use web scraping to collect data from online shopping websites and use it to compare the prices of products.
Academic Research: Since data is an integral part of any research, be it academic, marketing or scientific, Web Scrapping helps you gather structured data from multiple sources in the Internet with ease.
- Python syntaxes are simple, clear, and easy to read. Meaning anyone, including beginners, can easily use them to write scraping scripts.
- Scripts written in Python are generally easy and quick to write, requiring only a few lines of code.
- Python tools such as Beautiful Soup and Scrapy can be easily used to develop high-performing, very efficient and easy to debug web scrapers.
- Since Python is an all-around language, its tools can build a very flexible web scraper that does data extraction, importation, parsing and visualization.
Requests
It is a Python library used for making various types of HTTP requests like GET, POST.
BeautifulSoup
It is the most widely used Python library for web scraping that creates a parse tree for parsing HTML and XML documents.
Beautiful Soup automatically converts incoming documents to Unicode and outgoing documents to UTF-8.
Selenium
It is a Python library originally made for automated testing of web applications.
It is a web driver made for rendering web pages and also to scrape dynamically populated web pages.
lxml
It is a high performance, blazingly fast, production-quality HTML, and XML parsing Python library.
Works well when scrapping large datasets and also allows you to extract data from HTML using XPath and CSS selectors.
Scrapy
It is not just a library but a web scraping framework.
Scrapy provides spider bots that can crawl multiple websites and extract the data.
- In this article we will use BeautifulSoup and Requests libraries to scrape.
To extract data using BeautifulSoup and Requests libraries following steps are followed:
Sending an HTTP GET request to the URL of the webpage that you want to scrape, which will respond with HTML content using the Request library of Python.
Fetching and parsing the data using Beautifulsoup and maintain the data in some data structure such as Dict or List.
Analyzing the HTML tags and their attributes, such as class, id, and other HTML tag attributes. Also, identifying your HTML tags where your content lives.
Storing the data in the required format eg CSV, XLSX or JSON
Understanding and Inspecting the Data
Inspection of the page which you want to scrape is the most important job in web scraping
Without knowing the structure of the webpage, it is very hard to get the needed information.
In this article, we will scrap data available Here
To inspect data that you wish to scrape, right-click on that text and click on inspect to examine the tags and attributes of the element.
Install the Essential Python Libraries
pip install requests beautifulsoup4Importing the Essential Libraries
Import the "requests" library to fetch the page content and bs4 (Beautiful Soup) for parsing the HTML page content.
import requests
from bs4 import BeautifulSoupCollecting and Parsing a Webpage
In the next step, we will make a GET request to the url and will create a parse Tree object(soup) with the help of BeautifulSoup and Python built-in "lxml" parser.
URL="https://www.pythontutorial.net/"
# Make a GET request to fetch the raw HTML content
r=requests.get(URL).text
# Parse the html content
soup= BeautifulSoup(r,'lxml')
print(soup.prettify())And our output will be:
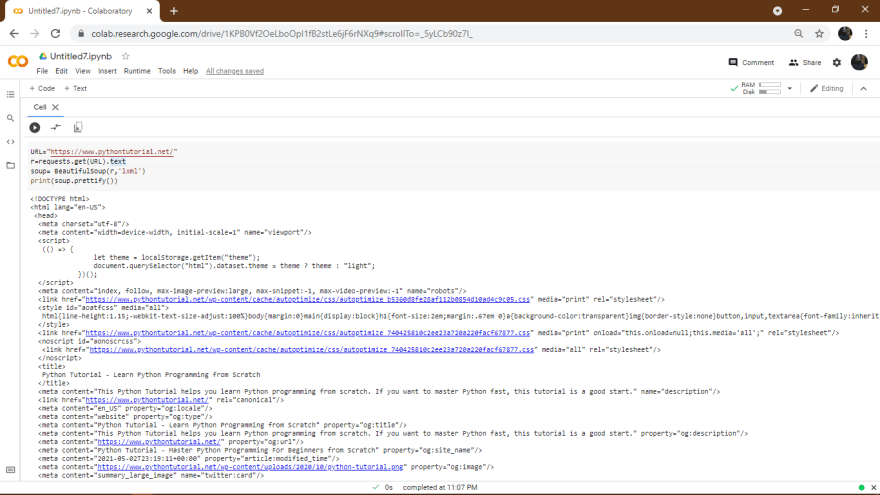
We can also print some basic information from it:
print the title of the webpage.
print(soup.title.text)Output
Python Tutorial - Learn Python Programming from ScratchPrint links in the page along with its attributes, such as href, title, and its inner Text.
for link in soup.find_all("a"):
print("Inner Text: {}".format(link.text))
print("Title: {}".format(link.get("title")))
print("href: {}".format(link.get("href")))Sample Output.

Finding all instances of a tag at once.
soup.find_all('p')Sample output

Searching for tags by class and id
We can use the find_all method to search for items by class or by id.
In this case we’ll search for any h tag that has the class entry_title:
soup.find_all('h', class_='entry_title')Searching for elements by id:
soup.find_all(id="page")We can also search for items using CSS selectors.
Example:
- p a — finds all a tags inside of a p tag.
- body p a — finds all a tags inside of a p tag inside of a body tag.
- html body — finds all body tags inside of an html tag.
Lets now use CSS selectors to find all the p tags in our page that are inside of a div;
soup.select("div p")Output

Now we have understood the python web scrapping basics.
18