
41
Aggregation Pipeline
Welcome back everyone. For this post I am going to continue talking about databases, specifically the aggregation pipeline in MongoDB. Most people learn how to pull data by using find commands in the Mongo Shell. While this is fine for simple queries it becomes insufficient as requests become more complex. This is where the aggregation pipeline comes in. It breaks up the query process into stages that form the pipeline. A generic example can be seen below.
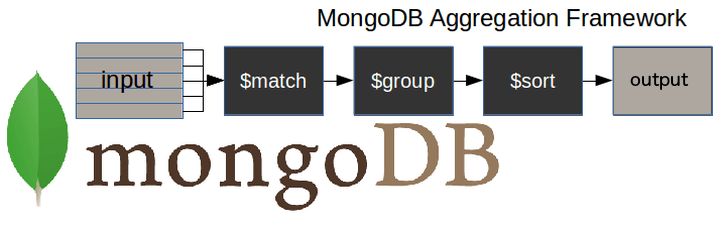
The most common stages are:
Match: Filters the documents to pull what is needed
Group: Separates the documents into specified groups
Sort: Sorts the documents in each group (ex: ascending or descending)
There are other more complex stages such as unwind and project but we will not be going over them.
The syntax to create a pipeline is to first create an array of JSON documents that contain each stage in the order you wish them to be performed. See an example below.
pipeline = [
{$match : {name: “John”},
{$group : {_id: “city”},
{$sort: {age: 1}
]
db.collection.aggregate(pipeline)Walking through the example, the pipeline first finds all of the documents that have a name that equals John. It then groups all of the John’s by their city and sorts them in each group by their age in ascending order.
As you can see this form of query can be extremely powerful and enhance readability of complex operations. It is important that as you learn to use the framework that the stages are ordered in ways to increase performance and do not hit the memory limitations. Let me know down below if you enjoyed the post and I hope you have a great rest of your week.
Resources:
Couto, J. (2021, May 4). The beginner's guide to MongoDB Aggregation (With Exercise). Studio 3T. https://studio3t.com/knowledge-base/articles/mongodb-aggregation-framework/.
Aggregation pipeline. Aggregation Pipeline - MongoDB Manual. (n.d.). https://docs.mongodb.com/manual/core/aggregation-pipeline/.
41