
36
Mongoose Partial Dump
Hello, my name is Afonso Araújo Neto and I'm a software engineer at Entria. It has been a while since a discussion that Sibelius Seraphini started with me about how to reproduce a production error on a local environment. To do that we needed to debug it, then introduce wrong data on local database, and finally compare software local behavior with production behavior. This is a common way to make sure the bug is gone. You need at least reproduce it in your local environment, fix it, then compare the new behavior with the old bug.
Then in a moment in our discussion he throws up an Idea about a "partial dump". I think that he already have thought about it before, I never asked by the way. This "partial dump" would be a solution to a problem on the usage of a common dump to reproduce bug. It has a big cost to copy a entire database every time a strange bug shows up, takes a lot of time and isn't safe to create and share a lot of production data. But if we could extract only a limited amount of data that we know that generate the bug?
For instance take a user details page. Someday at start of the day you and your team are working on a new feature, share a couple of information. Then suddenly a customer reports a bug on his user page, it won't load. So you found on his page a "Cannot read property null of undefined" error. As a experienced developer you already know that on user details page somewhere on the code can be a dynamic object property read like:
const property = getProperty();
console.log(property) // null
const user = getUser();
console.log(user) // undefined
const userPropertyValue = user[property] // <- error. user is undefinedOn the front-end field you can easily have a early return in case of user undefined. But this will only hide your bug. Why the back-end sent a undefined user? Why only that customer has a bug on his user page? Why the user is undefined here? One thing that can answer all these questions is our partial dump. Importing only the data relation that compose this user details page.
Sure the "property" variable being null is a bug as well. For our study case lets focus on user undefined. "Property null" could be a consequence of user undefined too. Like we could think the context of this code is inside a sanitize function. That function removes undefined / null / NaN of a user object, which is undefined.
To start developing the partial dump I needed to solve how to correct extract data with relationship to the module I want to reproduce. Lets go deeper inside the user details example. I want to take a dumper of user details page, which show some details analytics plus other infos. If that user page is for a e-commerce it would show all user's purchase orders, value spend, etc..
Lets take this image to represent all related models example:
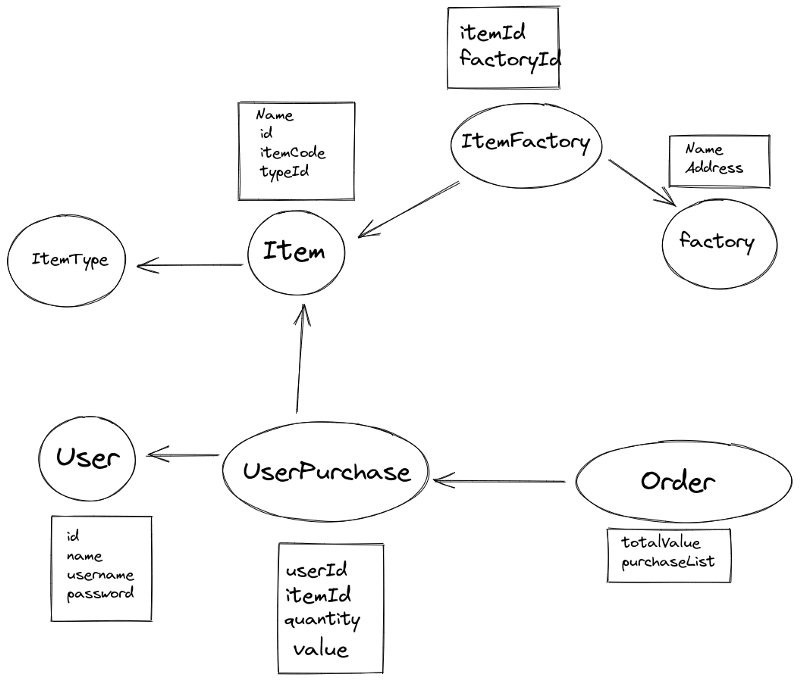
Maybe this isn't the best relationship for this case but lets focus on it for our study case
To properly export a usable dump of our user page details business rule. We would need to extract a User document, with all related UserPurchase documents, with all related Order and finally Item. ItemType, ItemFactory and Factory are collections related to Item, so them would be useful to a Item partial dump, not for user.
If ItemType was relevant for our UserPage in business rule would created a new collection UserItem (userId, itemId, quantity, etc..) or a UserItemType (userId, itemTypeId, quantityBought, etc..). But in this case, our use details page displays only all user orders. So a User Partial Dump would be:
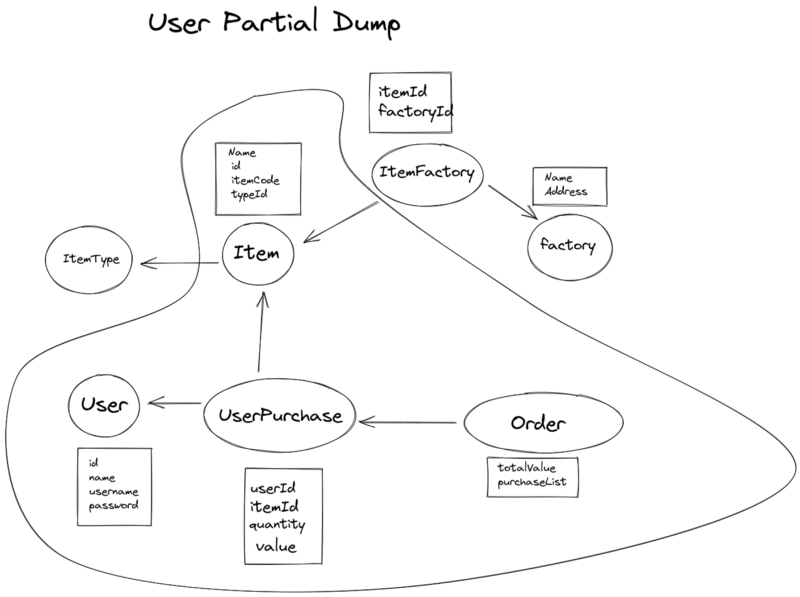
At the beginning we the partial dump used to receive a list of collectionName to be dumped. Like:
const collectionNameList = ['User', 'UserPurchase', 'Order', 'Item'];But as we used it we noticed this relationship pattern repeated a lot. It was so frequent that I decided to abstract this as a default "dump strategy".
In mongoose-partial-dump a "dump strategy" is a block of code used to extract from database documents following a certain relational pattern. The default strategy was made based on this list of rules:
- With all secondaryCollections documents, we recursively repeat step 1 and 2 of this list with the secondaryCollection found.
The result of these rules is a subgraph of your database graph:

As this package grows receiving upgrades and new features it would need one more feature before the use in production. Because of brasilian's LGPD law we can't manipulate production database. This law do not permit manipulation of personal data, as we would do by using partial dump.
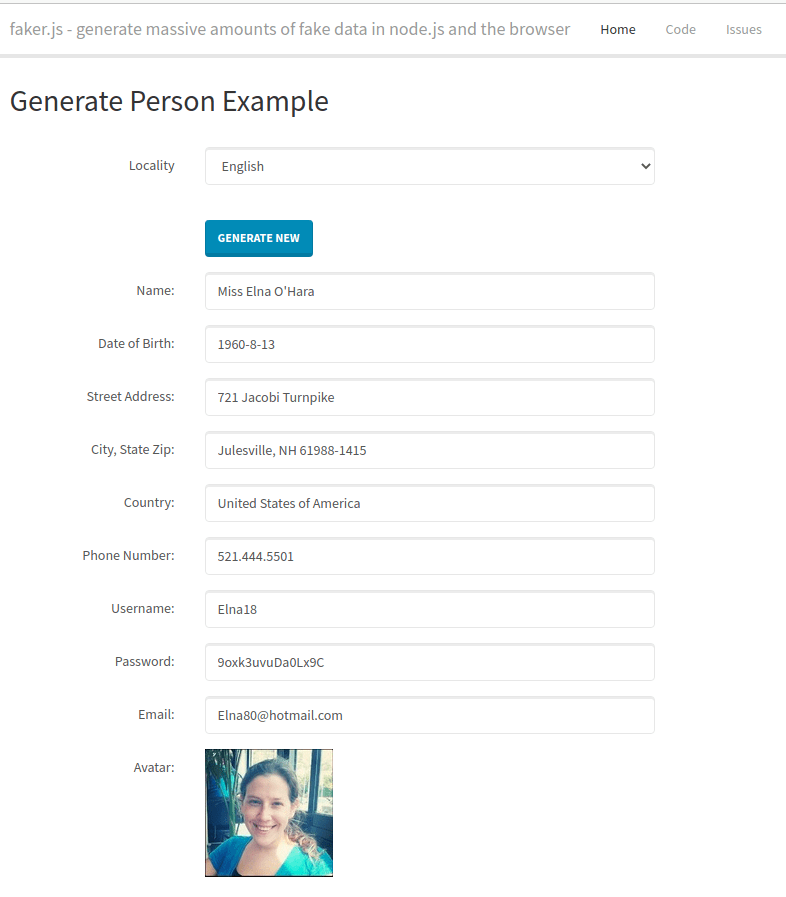
To solve this we implemented a anonymization feature. This feature change production data (name, address, avatar images, etc) before dump export using FakerJS. As the package says: "generate massive amounts of fake data in the browser and node.js".
That way we can fearlessly generate our dumps knowing we won't mess up with people personal data.
Software behavior do not changes. Independent of the environment, if any feature had changed, all behaviors will by the same. You can even copy/paste features url. In our case we use base64 transformation from a document _id like (user example):
**User:613514b8d5ae0e081ca7cd2d // value
VXNlcjo2MTM1MTRiOGQ1YWUwZTA4MWNhN2NkMmQ= // base64 encode**So if a production url is
<domain>/user/VXNlcjo2MTM1MTRiOGQ1YWUwZTA4MWNhN2NkMmQ=/details a related localhost in 8080 port url would be: localhost:8080/user/VXNlcjo2MTM1MTRiOGQ1YWUwZTA4MWNhN2NkMmQ=/details . Because in MongoDB we can create new documents by a pre-created unique identifier (ObjectId) the same url will exist for the same user page.A MWE is: "a collection of source code and other data files which allow a bug or problem to be demonstrated and reproduced." (wikipedia). Which data files can be made using partial dump.
Our partial dump became a useful tool in our daily debugging flow. With it we do not need aditional time trying to reproduce bugs, so we can spend more time creating better solutions for our bug fixes. And because time is a key resource for me it became so valuable that I decided to make it a open source. You can access it where:
Try it out. =)
36