
37
Scrape Brave Search Organic Results with Python
This blog post will show you how to scrape Organic Results from Brave Search. How to scrape title, link, displayed link, snippet, and sitelinks will be shown.
Contents:
What is Brave Search
Tl;DR: Privacy consumer tech market is growing fast. If you're tracking you website position in other search engines then you can take advantage of this growing market.
Brave Search is currently in Beta and it's offering users independent privacy search alternative to other big search engines. Brave don't want to replace Google or Bing search engines as Josep M. Pujol, chief of search at Brave said: "We need more choices, not to replace Google or Bing, but to offer alternatives."
Brave search is faster compare to Chrome because it (Brave Browser) blocks ads and trackers which speed up page load time, and it respect user privacy, and the only independent search engine. In other words, it has its own index, which it also gives it independence from other search providers.
As Brendan Eich, CEO and co-founder of Brave said: "Brave Search offers a new way to get relevant results with a community-powered index, while guaranteeing privacy.".
But wait, there's DuckDuckGo already. Since this blog post mainly focuses on scraping data, you can have a look at differences in focused on that topic articles:
Intro
This blog post is a first of Brave Search web scraping series. Here you'll see how to scrape Brave Search organic results using Python with
beautifulsoup, requests, lxml libraries.Note: This blog post don't cover all little things that might appear in organic results. HTML layout might be changed in the future thus some of CSS selectors might not work.
SelectorGadget was used to grab CSS selectors.
Make sure you're using
user-agent otherwise you'll get an empty output. If you want learn more about this topic, I have a dedicated blog post about how to chance of being blocked while web scraping search engines.Prerequisites
$ pip install requests
$ pip install lxml
$ pip install beautifulsoup4Make sure you have a basic knowledge of libraries mentioned above, since this blog post is not exactly a tutorial for beginners, so be sure you have a basic familiarity with them. I'll try my best to show in code that it's not that difficult.
Also, make sure you have a basic understanding of
CSS selectors because of select()/select_one() beautifulsoup methods that accepts CSS selectors. CSS selectors reference.Imports
from bs4 import BeautifulSoup
import requests, lxml, jsonWhat will be scraped

As well as rating and votes results

Process
Selecting title, link, displayed link, snippet/snippet image, inline sitelinks from the container with all the needed data:
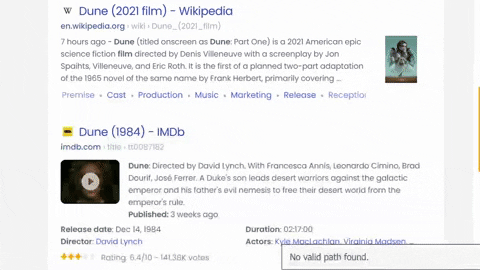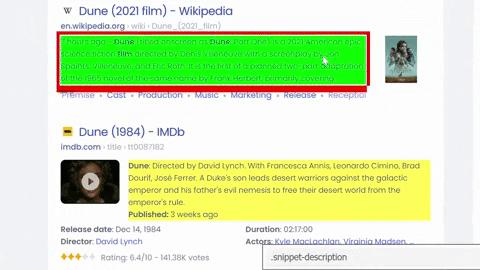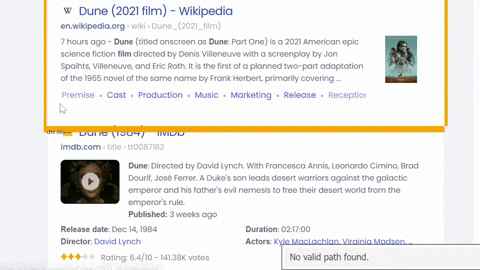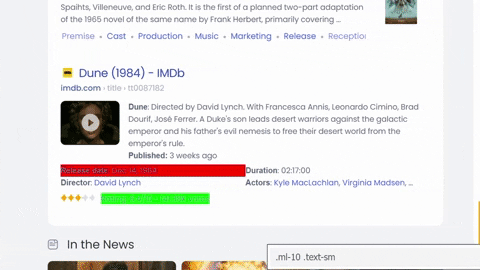
To get sitelinks we can use list comprehension and create a dictionary at the same time, in this case it would be something like this:
sitelinks = [
{
"title": sitelink.text
"link": sitelink['href']
} for sitelink in soup.select('CSS_SELECTOR')]Code
from bs4 import BeautifulSoup
import requests, lxml, json
headers = {
'User-agent':
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {
'q': 'dune film',
'source': 'web'
}
def get_organic_results():
html = requests.get('https://search.brave.com/search', headers=headers, params=params)
soup = BeautifulSoup(html.text, 'lxml')
data = []
for result, sitelinks in zip(soup.select('.snippet.fdb'), soup.select('.deep-results-buttons .deep-link')):
title = result.select_one('.snippet-title').text.strip()
title_img = result.select_one('.favicon')['src']
link = result.a['href']
displayed_link = result.select_one('.snippet-url').text.strip().replace('\n', '')
try:
# removes "X time ago" -> split by \n -> removes all whitespaces to the LEFT of the string
snippet = result.select_one('.snippet-content .snippet-description').text.strip().split('\n')[1].lstrip()
snippet_img = result.select_one('.snippet-content .thumb')['src']
except:
snippet = None
snippet_img = None
# list comprehension for creating key-value pair of title/link from sitelink results
sitelinks = [
{
title: sitelink.text.strip(),
link: sitelink['href']
} for sitelink in result.select('.deep-results-buttons .deep-link')]
try:
rating = result.select_one('.ml-10').text.strip().split(' - ')[0]
votes = result.select_one('.ml-10').text.strip().split(' - ')[1]
except:
rating = None
votes = None
data.append({
'title': title,
'title_img': title_img,
'link': link,
'displayed_link': displayed_link,
'snippet': snippet,
'snippet_img': snippet_img,
'rating': rating,
'votes': votes,
'sitelinks': sitelinks
})
print(json.dumps(data, indent=2, ensure_ascii=False))
get_organic_results()
----------------
# part of the output
'''
[
{
"title": "Dune (2021 film) - Wikipedia",
"title_img": "https://imgr.search.brave.com/wc-7XNJZ_tfrnnF72ZK8SIc1HV0ejHNf2xu1qguiQQw/fit/32/32/ce/1/aHR0cDovL2Zhdmlj/b25zLnNlYXJjaC5i/cmF2ZS5jb20vaWNv/bnMvNjQwNGZhZWY0/ZTQ1YWUzYzQ3MDUw/MmMzMGY3NTQ0ZjNj/NDUwMDk5ZTI3MWRk/NWYyNTM4N2UwOTE0/NTI3ZDQzNy9lbi53/aWtpcGVkaWEub3Jn/Lw",
"link": "https://en.wikipedia.org/wiki/Dune_(2021_film)",
"displayed_link": "en.wikipedia.org› wiki › Dune_(2021_film)",
"snippet": "Dune (titled onscreen as Dune: Part One) is a 2021 American epic science fiction film directed by Denis Villeneuve with a screenplay by Jon Spaihts, Villeneuve, and Eric Roth. It is the first of a planned two-part adaptation of the 1965 novel of the same name by Frank Herbert, primarily covering ...",
"snippet_img": "https://imgr.search.brave.com/IClP0pAcslDAfO9KZ_RAbCFo1Mt16hng2ec6U8GI4c0/fit/200/200/ce/1/aHR0cHM6Ly91cGxv/YWQud2lraW1lZGlh/Lm9yZy93aWtpcGVk/aWEvZW4vOC84ZS9E/dW5lXyUyODIwMjFf/ZmlsbSUyOS5qcGc",
"rating": null,
"votes": null,
"sitelinks": [
{
"Dune (2021 film) - Wikipedia": "Premise",
"https://en.wikipedia.org/wiki/Dune_(2021_film)": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Premise"
},
{
"Dune (2021 film) - Wikipedia": "Cast",
"https://en.wikipedia.org/wiki/Dune_(2021_film)": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Cast"
},
{
"Dune (2021 film) - Wikipedia": "Production",
"https://en.wikipedia.org/wiki/Dune_(2021_film)": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Production"
},
{
"Dune (2021 film) - Wikipedia": "Music",
"https://en.wikipedia.org/wiki/Dune_(2021_film)": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Music"
},
{
"Dune (2021 film) - Wikipedia": "Marketing",
"https://en.wikipedia.org/wiki/Dune_(2021_film)": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Marketing"
},
{
"Dune (2021 film) - Wikipedia": "Release",
"https://en.wikipedia.org/wiki/Dune_(2021_film)": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Release"
},
{
"Dune (2021 film) - Wikipedia": "Reception",
"https://en.wikipedia.org/wiki/Dune_(2021_film)": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Reception"
},
{
"Dune (2021 film) - Wikipedia": "Future",
"https://en.wikipedia.org/wiki/Dune_(2021_film)": "https://en.wikipedia.org/wiki/Dune_(2021_film)#Future"
}
]
}
... # other results
]
'''Links
Outro
If you have any questions or suggestions, or something isn't working correctly, feel free to drop a comment in the comment section.
If you want to access that feature via SerpApi, upvote on the Support Brave Search feature request, which is currently under review.
Yours,
Dimitry, and the rest of SerpApi Team.
Dimitry, and the rest of SerpApi Team.
37