
22
PyDP: A Python Differential Privacy Library
Differential privacy aims at addressing the paradox of learning nothing about an individual while learning useful information about a population. In essence, it describes the following promise, made by a data holder, or curator, to a data subject:
“You will not be affected, adversely or otherwise, by allowing your data to be used in any study or analysis, no matter what other studies, data sets, or information sources, are available.” – Cynthia Dwork in The Algorithmic Foundations of Differential Privacy.
Differential Privacy ensures that any sequence of outputs, which are responses to queries is ‘essentially’ equally likely to occur, independent of the presence or absence of any individual’s record.
Consider the illustration below, where the two databases
Database#1 and Database#2 differ by only one record, say, your data. If the results obtained from querying the database under these two different settings, are almost the same or similarly distributed, then they essentially are indistinguishable to an adversary.
Illustration of Differentially Private Database Mechanism (Image Source)
Mathematically,
dd’M(d) is the output of the training algorithm for the training subset d and M(d’) is the output of the training algorithm for the training subset d’. S under both these conditions should be arbitrarily close. The above equation should hold for all subsets d and d’.Smaller the value of Ɛ, stronger the privacy guarantees.
Membership Inference Attack (MIA) attempts at determining the presence of a record in a machine learning model’s training data by querying the model. From the discussion above, as the inclusion or exclusion of an individual’s data record cannot be inferred, differential privacy ensures protection against such attacks.
Differentially private database mechanisms can therefore, make confidential data widely available for accurate data analysis.
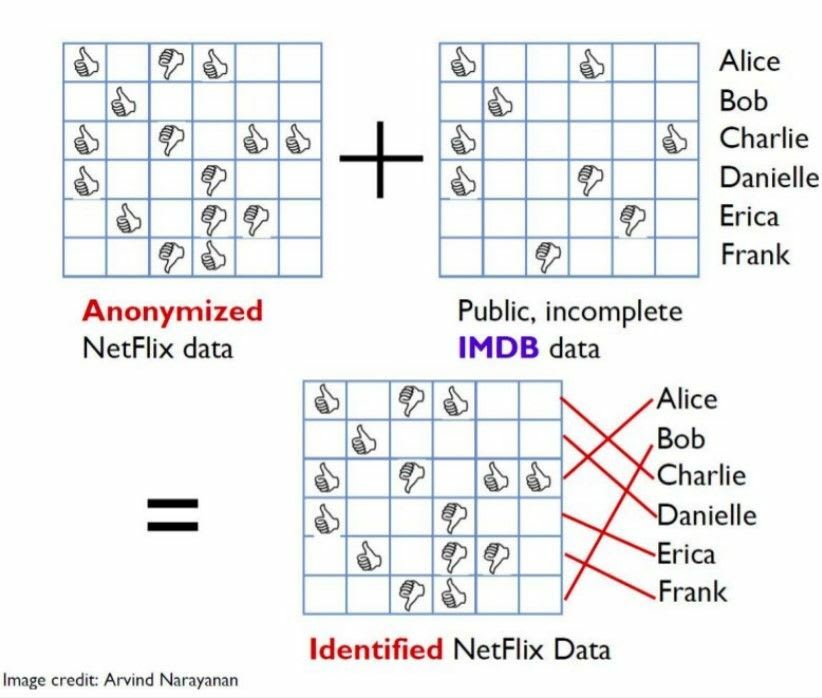
The Netflix Prize was an open competition for the best collaborative filtering algorithm for movie recommendations.
The dataset released was anonymized, without the users or the films being identified except by numbers assigned for the contest. Such anonymized movie records were published by Netflix as training data for the competition.
However, there were several users who could be identified by linkage with the Internet Movie Database (IMDb) which was non-anonymized and publicly available.
Researchers Arvind Narayanan and Vitaly Shmatikov, at the University of Texas at Austin present their studies in their work Robust De-anonymization of Large Datasets (How to Break Anonymity of the Netflix Prize Dataset).
Therefore, such linkage attacks can be used to match
“anonymized” records with non-anonymized records in a different dataset.Therefore, access to the IMDb would no longer permit a linkage attack to someone whose history is in the Netflix training set than to someone not in the training set.
PyDP is OpenMined’s Python wrapper for Google’s Differential Privacy project. The library provides a set of ε-differentially private algorithms, which can be used to produce aggregate statistics over numeric datasets containing private or potentially sensitive information.
!pip install python-dp # installing PyDPimport pydp as dp # by convention our package is to be imported as dp (dp for Differential Privacy!)
from pydp.algorithms.laplacian import BoundedSum, BoundedMean, Count, Max
import pandas as pd
import statistics
import numpy as np
import matplotlib.pyplot as pltThe dataset used here contains 5000 records, and is stored across 5 files, each file containing 1000 records.
More specifically, the dataset contains details such as the first and last names, email addresses of customers and the amount they spent on purchasing goods, and the state in the US they're from.
Let's fetch all the records, read them into pandas DataFrames and take a look at the head of each of the DataFrames.
url1 = 'https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/01.csv'
df1 = pd.read_csv(url1,sep=",", engine = "python")
print(df1.head())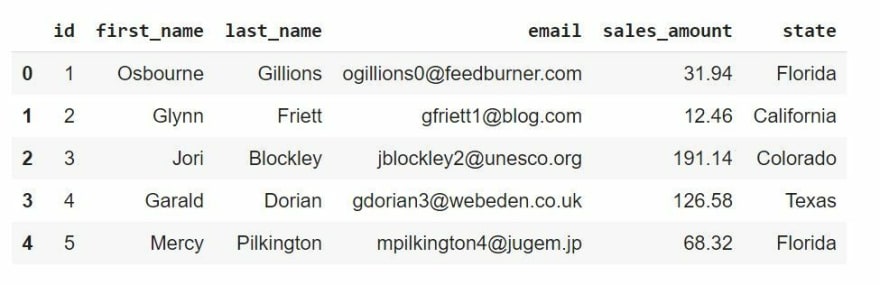
url2 = 'https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/02.csv'
df2 = pd.read_csv(url2,sep=",", engine = "python")
print(df2.head())
url3 ='https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/03.csv'
df3 = pd.read_csv(url3,sep=",", engine = "python")
df3.head()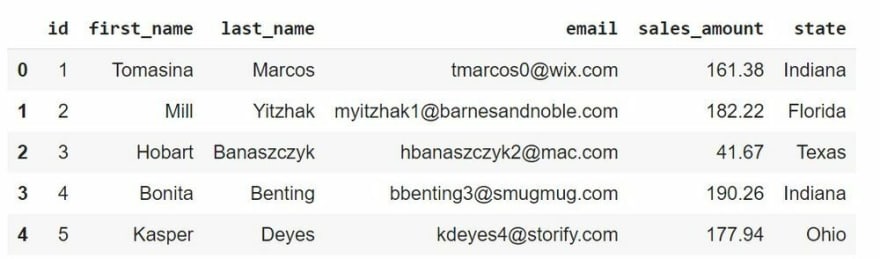
url4 = 'https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/04.csv'
df4 = pd.read_csv(url4,sep=",", engine = "python")
print(df4.head())
url5 = 'https://raw.githubusercontent.com/OpenMined/PyDP/dev/examples/Tutorial_4-Launch_demo/data/05.csv'
df5 = pd.read_csv(url5,sep=",", engine = "python")
print(df5.head())
Now that we've fetched records from all the 5 files, let us concatenate all the DataFrames into a single large DataFrame and this constitutes our original dataset. Note that our dataset has 5000 rows(records) and 6 columns.
combined_df_temp = [df1, df2, df3, df4, df5]
original_dataset = pd.concat(combined_df_temp)
print(original_dataset.shape)
# Result
# (5000,6)Let us now create a parallel database that differs by only one record, say, Osbourne's record and name it redact_dataset. We then inspect the heads of both DataFrames to verify that Osbourne's record has been removed.
redact_dataset = original_dataset.copy()
redact_dataset = redact_dataset[1:]
print(original_dataset.head())
print(redact_dataset.head())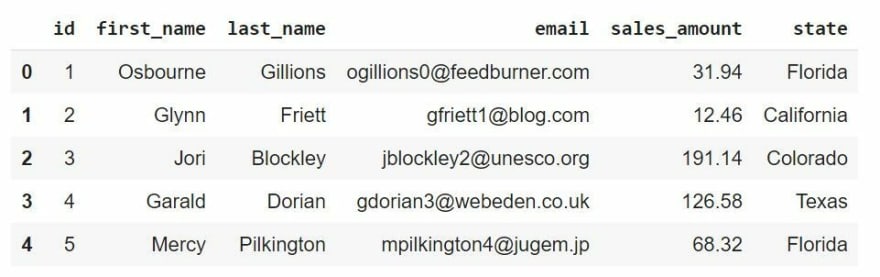
Is the amount of money we spend at our neighborhood store private or sensitive information? Well, it may not seem all that sensitive! But, what if the same information can be used to identify us?
In the example that we have, let us say we remove all personal information such as name and email address. Given that there's some access to the store's sales record, will the sales amount in itself not suffice to infer Osbourne's identity? Yes!
And to do that, we sum up all entries in the
sales_amount column in our original dataset, and the redact_dataset. The difference between these two sums exactly gives us the amount that Osbourne spent, and is verified as shown in the code snippet below. This is a simple example where membership inference was successful even after removal of personally identifiable information.
sum_original_dataset = round(sum(original_dataset['sales_amount'].to_list()), 2)
sum_redact_dataset = round(sum(redact_dataset['sales_amount'].to_list()), 2)
sales_amount_Osbourne = round((sum_original_dataset - sum_redact_dataset), 2)
assert sales_amount_Osbourne == original_dataset.iloc[0, 4]Now, we illustrate how differentially private sum in place of simple sum can help in rendering membership inference attacks unsuccessful.
For the example above, let's assume that the customers should spend a minimum of 5$ at the store and no more than 250$ for a particular purchase.
We then go ahead and compute differentially private sum on both original and the parallel dataset that differed by one record, as shown in the code snippets below.
dp_sum_original_dataset = BoundedSum(epsilon= 1.5, lower_bound = 5, upper_bound = 250, dtype ='float')
dp_sum_og = dp_sum_original_dataset.quick_result(original_dataset['sales_amount'].to_list())
dp_sum_og = round(dp_sum_og, 2)
print(dp_sum_og)
# Output dp_sum_og
# 636723.61
dp_redact_dataset = BoundedSum(epsilon= 1.5, lower_bound = 5, upper_bound = 250, dtype ='float')
dp_redact_dataset.add_entries(redact_dataset['sales_amount'].to_list())
dp_sum_redact=round(dp_redact_dataset.result(), 2)
print(dp_sum_redact)
# Output dp_sum_redact
# 636659.17Let's proceed to summarize a few observations.
We've therefore succeeded in ensuring differential privacy in our simple example!
print(f"Sum of sales_value in the orignal dataset: {sum_original_dataset}")
print(f"Sum of sales_value in the orignal dataset with DP: {dp_sum_og}")
assert dp_sum_og != sum_original_dataset
# Output
Sum of sales_value in the orignal dataset: 636594.59
Sum of sales_value in the orignal dataset with DP: 636723.61
print(f"Sum of sales_value in the second dataset: {sum_redact_dataset}")
print(f"Sum of sales_value in the second dataset with DP: {dp_sum_redact}")
assert dp_sum_redact != sum_redact_dataset
# Output
Sum of sales_value in the second dataset: 636562.65
Sum of sales_value in the second dataset with DP: 636659.17
print(f"Difference in Sum with DP: {round(dp_sum_og - dp_sum_redact, 2)}")
print(f"Actual Difference in Sum: {sales_amount_Osbourne}")
assert round(dp_sum_og - dp_sum_redact, 2) != sales_amount_Osbourne
# Output
Difference in sum using DP: 64.44
Actual Value: 31.94Hope this introductory post helped in understanding the intuition behind differential privacy and protection against membership inference attacks. We shall look at a few more examples in subsequent blog posts.😊
[1] The Algorithmic Foundations of Differential Privacy by Cynthia Dwork.
[2] PyDP Tutorial by Chinmay Shah at OpenMined Privacy Conference
22