
24
A Next-Generation ORM: Prisma
For this example, I'll use a simple blog app. It has a User table, and an Article table. Users can have many Articles, and each Article only has one author.
To install Prisma, run yarn add prisma -D.
In a folder called prisma at the root of your project, you can create a file called schema.prisma. This is where the descriptions (or "schemas") of your tables will be stored.
Prisma uses this file to apply changes to the database, and generate a custom client for us.

You can ignore the migrations folder for now.
To specify where your database will be, you start a datasource block.
In the following snippet, I use an SQLite database (a lightweight database good for quickly testing apps, which stores the database in a single file). For the "url" of the SQLite database, I specify database.db.
datasource db {
provider = "sqlite"
url = "file:./database.db"
}Alternatively, you can use Postgres or MySQL as your database.
Because exposing Postgres's database url can compromise its security, we can store it as an environment variable to avoid putting it directly in the code. Prisma supports .env files, which loads environment variables from a file called .env, allowing for a portable development environment.
This is what the snippet for a Postgres database would look like:
datasource db {
provider = "postgres"
// Access the DATABASE_URL variable.
url = env("DATABASE_URL")
}Remember how I said Prisma can generate client-side code for you?
This snippet specifies exactly what behavior the Prisma generator will follow. This has worked perfectly for me.
generator client {
provider = "prisma-client-js"
}Now, it's time for us to add our tables. For this example, I'll use a simple blog app. It has a User table, and an Article table. Users can have many Articles, and each Article only has one author.
We'll start with some basic details about each user, so we can get familiar with the syntax of Prisma.
To start the schema for a table, we declare a model block:
model User {
// Our fields (columns) go here...
}We'll add an ID column, which will be an integer, an email column, which will be a string, and a name column, which will also be a string.
model User {
id Int
email String
name String
}Because we want our ID to be indexable, we'll add the @id decorator. This is a simple app, so we'll make its value automatically increment for each user.
model User {
id Int @id @default(autoincrement())
email String
name String
}Because we want each user's email to be unique, we'll add the @unique decorator.
model User {
id Int @id @default(autoincrement())
email String @unique
name String
}Now, time for our Article model. We'll make an ID field in the same way as before, and also add a title field, a content field, and a field to specify when the article was published. Finally, we'll add an authorId field for the ID of the user who authored the article.
model Article {
id Int @id @default(autoincrement())
authorId Int
title String
content String
publishedAt DateTime
}Our article has a field called authorId, but wouldn't it be nice if there were a field called author which had the type User? With Prisma, we can actually make this happen!
model Article {
id Int @id @default(autoincrement())
authorId Int
author User
title String
content String
publishedAt DateTime
}We aren't done yet, but there isn't much left to do.
We just need to use the @relation decorator.
The @relation decorator uses this syntax:
@relation(fields: [authorId], references: [id])
Let's break this down.
The fields attribute specifies which field of the Article references the id of the author. The references attribute specifies which field of the User table the fields attribute points to.
That might have been wordy, so I'll just show you what it would look like in the schema:
model Article {
id Int @id @default(autoincrement())
authorId Int
author User @relation(fields: [authorId], references: [id])
title String
content String
publishedAt DateTime
}Perfect.
There is one final step. Because each Article has an author, logically, each User will have several Articles. We actually cannot avoid adding that to the schema.
To reflect this in our schema, we just add an articles field to the User model. We'll make it have the type Article[].
model User {
id Int @id @default(autoincrement())
email String @unique
name String
articles Article[]
}Phew! We're done with schema.prisma for this article.
Here's what the final schema.prisma looks like:
datasource db {
provider = "sqlite"
url = "file:./database.db"
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String
articles Article[]
}
model Article {
id Int @id @default(autoincrement())
authorId Int
author User @relation(fields: [authorId], references: [id])
title String
content String
publishedAt DateTime
}Now, we want Prisma apply these changes to our database. This will automatically generate the custom client SDK. The process of applying changes to a database is called "migration".
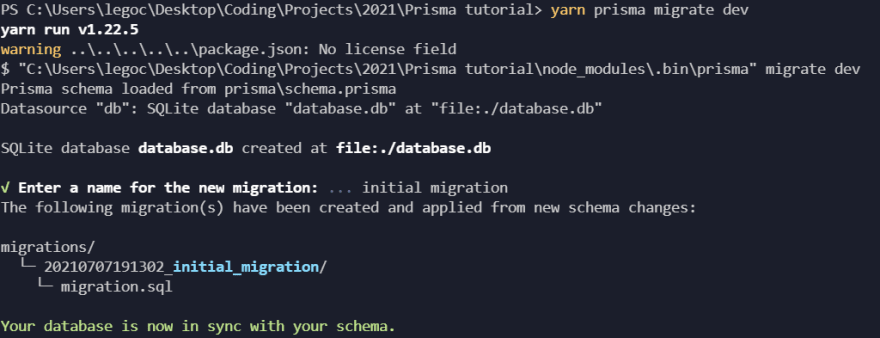
The command to apply these changes is:
yarn prisma migrate dev
The dev at the end specifies that we're working in the development environment.
We will need to specify a name for the migration, so we'll just write initial migration.
If everything goes well, the output will look something like this:
Now, we're ready to start manipulating the database.
Now that we've generated the client code, we can start using Prisma.
If the generated client code doesn't show up, try running the command:
yarn prisma generate.
We'll write our code in a file called index.js. Prisma also has built-in Typescript support.
To create an instance of the Prisma client, we import the PrismaClient class from @prisma/client.
const { PrismaClient } = require('@prisma/client');
const prisma = new PrismaClient();Because Prisma's client is custom-generated for our database, it has built-in Intellisense.

Let's walk through some examples of how we would use the Prisma client.
First, we'll create a user.
This is simple enough: creating any table in Prisma can be done with prisma.[table name].create().
prisma.user.create({
data: {
name: 'Michael Fatemi',
email: '<REDACTED>',
},
});If we want to retrieve the ID that was autogenerated for the user:
prisma.user.create({
select: {
id: true
},
data: {
name: 'Michael Fatemi',
email: '<REDACTED>',
},
});Because each Article references a User, Prisma doesn't allow us to specify the authorId manually, as this might violate the foreign key constraint created by SQL. So, we must specify that we are "connecting" a User to the article, through the syntax shown below.
async function createArticle(authorId, title, content) {
prisma.article.create({
data: {
author: {
connect: {
id: authorId,
},
},
content,
title,
publishedAt: new Date(),
},
});
}We can fetch data about a user like so:
async function getArticles(userId) {
return await prisma.user.findFirst({
select: {
articles: true
},
where: {
id: userId
}
})
}This might not be useful in the real world, but can demonstrate how powerful Prisma can be.
This example also shows how you can create more complex queries than checking for equality of a value. You can also check if a value is less than (lt), greater than (gt), equal to (eq), or others by passing an object to the where clause instead of a value.
async function getUsersWhoWroteAnArticleBefore(date) {
return await prisma.user.findMany({
select: {
id: true,
name: true
},
where: {
articles: {
some: {
publishedAt: {
lt: date
}
}
}
}
})
}Thanks for reading this article, I hope it was helpful for learning how to use Prisma to auto-generate code!
24