
34
Scrape Google Recipe Results with Python
This blog post is a continuation of Google's web scraping series. Here you'll see how to scrape Google Recipe Results from Organic Results using Python with beautifulsoup, requests, lxml libraries. An alternative API solution will be shown.
import requests, lxml
from bs4 import BeautifulSoup
from serpapi import GoogleSearch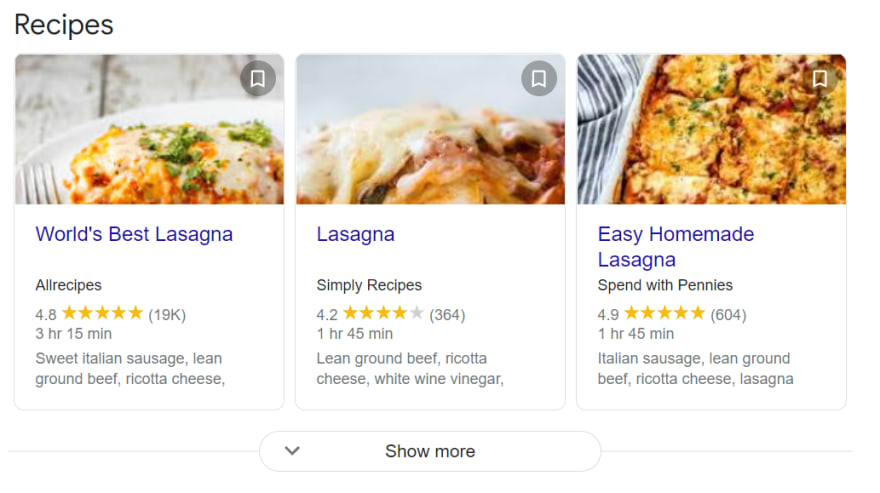
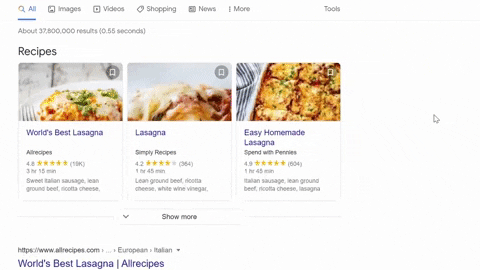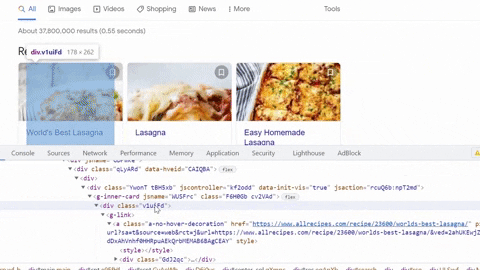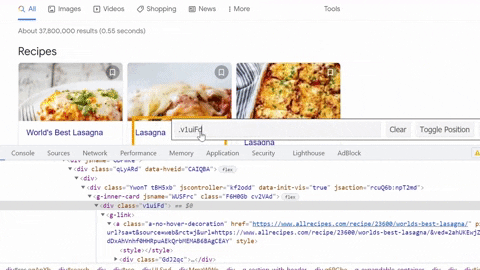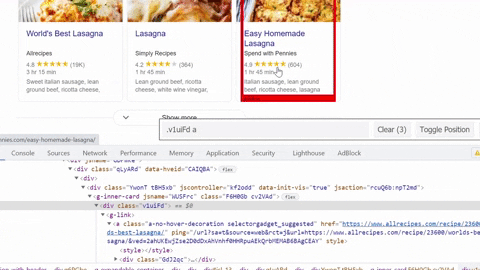
Selecting Container, Title, Rating, Reviews, Time to cook, Ingredients, Source

Selecting URL
import requests, lxml
from bs4 import BeautifulSoup
headers = {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.19582"
}
params = {"q": "lasagna recipe", "hl": "en", 'gl': 'us'}
response = requests.get("https://www.google.com/search", params=params, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
for result in soup.select('.cv2VAd'):
try:
title = result.select_one('.hfac6d').text
except: title = None
source = result.select_one('.KuNgxf').text
total_time = result.select_one('.z8gr9e').text
# returns a list() if need to extract certain ingredient
ingredients = result.select_one('.LDr9cf').text.split(',')
rating = result.select_one('.YDIN4c').text
reviews = result.select_one('.HypWnf').text.replace('(', '').replace(')', '')
print(f'{title}\n{source}\n{total_time}\n{rating}\n{reviews}\n{ingredients}\n')
--------------
'''
World's Best Lasagna
Allrecipes
3 hr 15 min
4.8
19K
['Sweet italian sausage', ' lean ground beef', ' ricotta cheese', ' tomato sauce', ' lasagna noodles']
'''If you want to extend this program and extract every recipe that Google provides, then it's time for Selenium.
I believe that there're several ways to make it work, I'll show one approach.
To get actual clicking until there's nothing to click on we need to use a while loop in combination with .is_displayed() method which returns True or False.
The logic is that it clicks on the Show more button and once there's nothing to click on it breaks out of the while loop and begin to scrape all recipes that where loaded during clicking:
While loop snippet explanation:
while True:
# locates show more button element
show_more_button = driver.find_element_by_xpath('//*[@id="isl_13"]/div[5]/div[2]').is_displayed()
time.sleep(1)
try:
# clicks on show more button
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.XPATH, '//*[@id="isl_13"]/div[5]/div[2]'))).click()
except:
# pass were used to ignore exception error and continue execution
pass
# if show_more_button element becomes False, breaks the loop
if show_more_button == False:
break
# under the hood it looks like this
'''
True
True
True
True
True
True
True
True
True
True
True
True
False # breaks from the loop
'''import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path='path/to/chromedriver.exe')
driver.get('https://www.google.com/search?q=lasagna+recipe&hl=en')
# buffer for everything to load
time.sleep(10)
while True:
# returns True or False. If element is not displayed (False), breaks out of the while loop
# pardon my french (xpath)
show_more_button = driver.find_element_by_xpath('/html/body/div[7]/div/div[10]/div[1]/div/div[2]/div[2]/div/div/div[1]/div/div/g-section-with-header/div[2]/g-expandable-container/div/div/div/div[5]/div[2]').is_displayed()
print(show_more_button) # just for debug
time.sleep(1)
try:
WebDriverWait(driver, 5).until(EC.element_to_be_clickable((By.XPATH, '/html/body/div[7]/div/div[10]/div[1]/div/div[2]/div[2]/div/div/div[1]/div/div/g-section-with-header/div[2]/g-expandable-container/div/div/div/div[5]/div[2]'))).click()
except:
pass
# if show_more_button element becomes False, break the loop
if show_more_button == False:
break
for index, result in enumerate(driver.find_elements_by_css_selector('.cv2VAd')):
try:
title = result.find_element_by_css_selector('.hfac6d').text
except: title = None
link = result.find_element_by_css_selector('.cv2VAd .v1uiFd a').get_attribute('href')
source = result.find_element_by_css_selector('.KuNgxf').text
try:
total_time = result.find_element_by_css_selector('.wHYlTd').text
except:
total_time = None
try:
# stays the list if need to extract certain ingredient
ingredients = result.find_element_by_css_selector('.LDr9cf').text.split(',')
except:
ingredients = None
try:
rating = result.find_element_by_css_selector('.YDIN4c').text
except:
rating = None
try:
reviews = result.find_element_by_css_selector('.HypWnf').text.replace('(', '').replace(')', '')
except:
reviews = None
print(f'{index + 1}\n{title}\n{link}\n{source}\n{total_time}\n{ingredients}\n{rating}\n{reviews}\n')
driver.quit()
-----------
'''
1 # first element
World's Best Lasagna
https://www.allrecipes.com/recipe/23600/worlds-best-lasagna/
Allrecipes
3 hr 15 min
['Sweet italian sausage', ' lean ground beef', ' ricotta cheese', ' tomato sauce', ' lasagna noodles']
4.8
19K
...
102 # last element
Last Minute Red Lasagna
https://www.101cookbooks.com/last-minute-red-lasagna-recipe/
101 Cookbooks
40 min
['Whole wheat no', ' red lentils', ' red pepper flakes', ' fresh pasta sheets', ' mozzarella cheese']
4.4
29
'''Note that GIF is sped-up

SerpApi is a paid API with a free plan.
The difference is that you get structured JSON with correctly formatted data, for example, 19K reviews will be 19000 which is useful if you're doing some sort of analysis and don't have to waste time on making conversion. Also, you get access to thumbnails data if you need them.
Note: it scrapes only 3 results, just like with
beautifulsoup.
All recipe results is currently under development (check out in the docs if it's already implemented)
import json # just for pretty output
from serpapi import GoogleSearch
params = {
"api_key": "YOUR_API_KEY",
"engine": "google",
"q": "lasagna recipe",
"gl": "us",
"hl": "en"
}
search = GoogleSearch(params)
results = search.get_dict()
for result in results['recipes_results']:
print(json.dumps(result, indent=2, ensure_ascii=False))
-------------
'''
{
"title": "World's Best Lasagna",
"link": "https://www.allrecipes.com/recipe/23600/worlds-best-lasagna/",
"source": "Allrecipes",
"rating": 4.8,
"reviews": 19000,
"total_time": "3 hr 15 min",
"ingredients": [
"Sweet italian sausage",
"lean ground beef",
"ricotta cheese",
"tomato sauce",
"lasagna noodles"
],
"thumbnail": "https://serpapi.com/searches/60e58864ad7fa97ae27832be/images/b6c5f341384d29417e5d9a3b87dba8a0a0c34837ef00120357584c23f98de567.jpeg"
}
'''If you have any questions or something isn't working correctly or you want to write something else, feel free to drop a comment in the comment section or via Twitter at @serp_api.
Yours,
Dimitry, and the rest of SerpApi Team.
34