
30
Dynamic import with HTTP URLs in Node.js
Is it possible to import code in Node.js from HTTP(S) URLs just like in the browser or in Deno? After all, Node.js has had stable support for ECMAScript modules since version 14, released in April 2020. So what happens if we just write something like import('https://cdn.skypack.dev/uuid')?
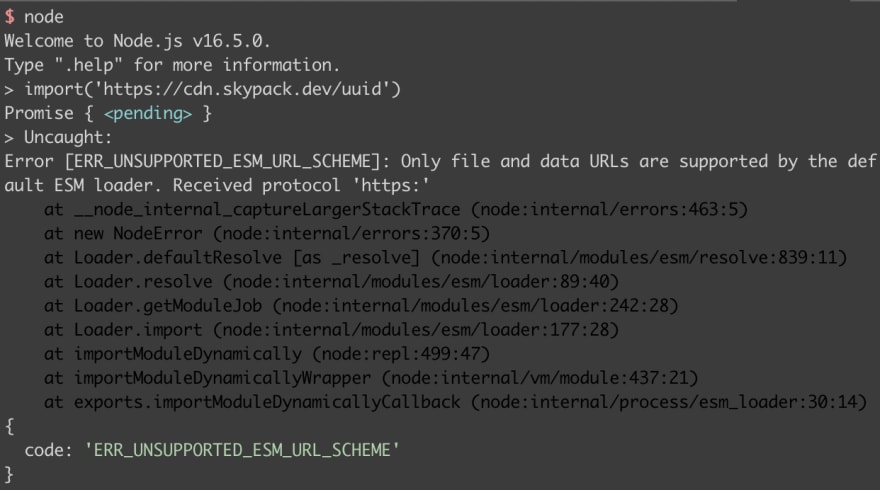
Unfortunately it's neither possible import code from HTTP URLs statically nor dynamically because the URL scheme is not supported.
An experimental feature of Node.js are custom loaders. A loader is basically a set of "hook" functions to resolve and load source code. There is even an example of an HTTP loader.
Such a loader would be passed to Node.js as a command line argument:
node --experimental-loader ./https-loader.mjsA downside to this approach is that a loader's influence is quite limited. For instance, the execution context of the downloaded code cannot be modified. The team working on loaders is still modifying their API, so this could still be subject to change.
Another Node.js API that offers more low-level control is vm. It enables the execution of raw JavaScript code within the V8 virtual machine.
In this blog post, we're going to use it to create our own dynamic import implementation!
Let's start with downloading the remotely hosted code. A very simple and naive solution is to just use "node-fetch" or a similar library:
import fetch from 'node-fetch';
async function fetchCode(url) {
const response = await fetch(url);
if (response.ok) {
return response.text();
} else {
throw new Error(
`Error fetching ${url}: ${response.statusText}`
);
}We can use this function to download any ECMAScript module from a remote server. In this example we are going to use the lodash-es module from Skypack1, the CDN and package repository of the Snowpack build tool.
const url = 'import cdn.skypack.dev/lodash-es';
const source = await fetchCode(url);Obviously important security and performance aspects have been neglected here. A more fully-featured solution would handle request headers, timeouts, and caching amongst other things.
For the longest time, Node.js has provided the vm.Script class to compile and execute raw source code. It's a bit like eval but more sophisticated. However, this API only works with the classic CommonJS modules.
For ECMAScript modules, the new vm.Module API must be used and it is still experimental. To enable it, Node.js must be run with the --experimental-vm-modules flag.
To use vm.Module we are going to implement the 3 distinct steps creation/parsing, linking, and evaluation:
First, we need to create an execution context. This is going to be the global context in which the code will be executed. The context can be just an empty object but some code may require certain global variables, like those defined by Node.js itself.
import vm from 'vm';
const context = vm.createContext({});Next, we create an instance of vm.SourceTextModule which is a subclass of vm.Module specifically for raw source code strings.
return new vm.SourceTextModule(source, {
identifier: url,
context,
});The identifier is the name of the module. We set it to the original HTTP URL because we are going to need it for resolving additional imports in the next step.
In order to resolve additional static import statements in the code, we must implement a custom link function. This function should return a new vm.SourceTextModule instance for the two arguments it receives:
- The specifier of the imported dependency. In ECMAScript modules this can either be an absolute or a relative URL to another file, or a "bare specifier" like
"lodash-es". - The referencing module which is an instance of
vm.Moduleand the "parent" module of the imported dependency.
In this example we are only going to deal with URL imports for now:
async function link(specifier, referencingModule) {
// Create a new absolute URL from the imported
// module's URL (specifier) and the parent module's
// URL (referencingModule.identifier).
const url = new URL(
specifier,
referencingModule.identifier,
).toString();
// Download the raw source code.
const source = await fetchCode(url);
// Instantiate a new module and return it.
return new vm.SourceTextModule(source, {
identifier: url,
context: referencingModule.context
});
}
await mod.link(link); // Perform the "link" step.After the link step, the original module instance is fully initialised and any exports could already be extracted from its namespace. However, if there are any imperative statements in the code that should be executed, this additional step is necessary.
await mod.evaluate(); // Executes any imperative code.The very last step is to extract whatever the module exports from its namespace.
// The following corresponds to
// import { random } from 'https://cdn.skypack.dev/lodash-es';
const { random } = mod.namespace;Some modules may require certain global variables in their execution context. For instance, the uuid package depends on crypto, which is the Web Crypto API. Node.js provides an implementation of this API since version 15 and we can inject it into the context as a global variable.
import { webcrypto } from 'crypto';
import vm from 'vm';
const context = vm.createContext({ crypto: webcrypto });By default, no additional global variables are available to the executed code. It's very important to consider the security implications of giving potentially untrusted code access to additional global variables, e.g. process.
The ECMAScript module specification allows for a type of import declaration that is sometimes called "bare module specifier". Basically, it's similar to how a require statement of CommonJS would look like when importing a module from node_modules.
import uuid from 'uuid'; // Where does 'uuid' come from?Because ECMAScript modules were designed for the web, it's not immediately clear how a bare module specifier should be treated. Currently there is a draft proposal by the W3C community for "import maps". So far, some browsers and other runtimes have already added support for import maps, including Deno. An import map could look like this:
{
"imports": {
"uuid": "https://www.skypack.dev/view/uuid"
}
}Using this construct, the link function that is used by SourceTextModule to resolve additional imports could be updated to look up entries in the map:
const { imports } = importMap;
const url =
specifier in imports
? imports[specifier]
: new URL(specifier, referencingModule.identifier).toString();As we have seen, some modules may depend on certain global variables while others may use bare module specifiers. But what if a module wants to import a core node module like fs?
We can further enhance the link function to detect wether an import is for a Node.js builtin module. One possibility would be to look up the specifier in the list of builtin module names.
import { builtinModules } from 'module';
// Is the specifier, e.g. "fs", for a builtin module?
if (builtinModules.includes(specifier)) {
// Create a vm.Module for a Node.js builtin module
}Another option would be to use the import map and the convention that every builtin module can be imported with the node: URL protocol. In fact, Node.js ECMAScript modules already support node:, file: and data: protocols for their import statements (and we just added support for http/s:).
// An import map with an entry for "fs"
const { imports } = {
imports: { fs: 'node:fs/promises' }
};
const url =
specifier in imports
? new URL(imports[specifier])
: new URL(specifier);
if (
url.protocol === 'http:' ||
url.protocol === 'https:'
) {
// Download code and create a vm.SourceTextModule
} else if (url.protocol === 'node:') {
// Create a vm.Module for a Node.js builtin module.
} else {
// Other possible schemes could be file: and data:
}So how do we create a vm.Module for a Node.js builtin module? If we used another SourceTextModule with an export statement for, e.g. fs, it would lead to an endlessly recursive loop of calling the link function over and over again.
On the other hand, if we use a SourceTextModule with the code export default fs, where fs is a global variable on the context, the exported module would be wrapped inside an object with the default property.
// This leads to an endless loop, calling the "link" function.
new vm.SourceTextModule(`export * from 'fs';`);
// This ends up as an object like { default: {...} }
new vm.SourceTextModule(`export default fs;`, {
context: { fs: await import('fs') }
});However, we can use vm.SyntheticModule. This implementation of vm.Module allows us to programatically construct a module without a source code string.
// Actually import the Node.js builtin module
const imported = await import(identifier);
const exportNames = Object.keys(imported);
// Construct a new module from the actual import
return new vm.SyntheticModule(
exportNames,
function () {
for (const name of exportNames) {
this.setExport(name, imported[name]);
}
},
{
identifier,
context: referencingModule.context
}
);The (still experimental) APIs of Node.js allow us to implement a solution for dynamically importing code from HTTP URLs "in user space". While ECMAScript modules and vm.Module were used in this blog post, vm.Script could be used to implement a similar solution for CommonJS modules.
Loaders are another way to achieve some of the same goals. They provide a simpler API and enhance the behaviour of the native import statements. On the other hand, they are less flexible and they're possibly even more experimental than vm.Module.
There are many details and potential pitfalls to safely downloading and caching remotely hosted code that were not covered. Not to even mention the security implications of running arbitrary code. A more "production ready" (and potentially safer) runtime that uses HTTP imports is already available in Deno.
That said, it's interesting to see what can be achieved with the experimental APIs and there may be certain use cases where the risks to use them are calculable enough.
Check out a complete working example on Code Sandbox:
Or find the code in this repository:
 mfellner
/
react-micro-frontends
mfellner
/
react-micro-frontends
Examples for React micro frontends
-
Skypack is nice because it offers ESM versions of most npm packages. ↩