
24
Internationalization(i18n) and Localization(L10n)
- internationalization(i18N)
-
Localization(L10N)
- Localization Process
- Develop a localization strategy
- Region and Language
- Add new region/language/service
- Incremental Localization
- Management of translation
- Localized implementation
- Localized multilingual implementation
- The Challenges of Localization
- Do you need to consider SEO
- Localization of product design
- Localization under Microservices
- Localized technical or business standards development
- Development Environment and Business Processes
- Static text processing
- Whether to store language and region settings
- Localization of back-end services
- Localization of third-party services and resources
- Release Process
- Localization under micro front-end architecture
- Localized testing
- Localization Platform
A successful product needs to go global through many stages, from the perspective of software development there are two main processes: internationalization and localization.
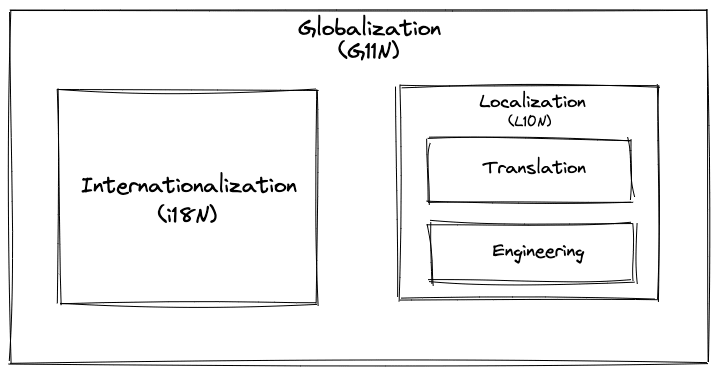
A language environment is the use of a specific language or language variant within a country or geographic region, which determines the format and parsing of dates, times, numbers and currencies, as well as the various measurement units and translated names of time zones, languages, countries and regions. Internationalization enables a piece of software to handle multiple language environments, localization enables a piece of software to support a specific regional language environment. This means that the process of globalization is to first make the software internationalized, and then to do the localization implementation so that it can support a specific language environment in a specific region.
They are often abbreviated as i18n (18 means that there are 18 letters between i and n in the word "internationalization") and L10n, respectively, due to the length of their single words, using a capital L to distinguish the i in i18n and to make it easy to distinguish the lowercase l from the 1.(Wikipedia)
- The ability to display text in the user's native language.
- Ability to enter text in the user's native language.
- Ability to process text in the user's native language in a specific encoding.
The Unicode character set can display almost every character known to man in code points ranging from 0 to 10FFFF (hexadecimal). It requires at least 21 bits for storage. The text encoding system UTF-8 adapts Unicode code points to a reasonable 8-bit data stream and is compatible with the ASCII data processing system.UTF stands for Unicode Transformation Format.
Since 2009, UTF-8 has been the dominant encoding form on the World Wide Web. As of November 2019, UTF-8 is used in 94.3% of all web pages (some of which are ASCII only, as it is a subset of UTF-8), and 96% of the top 1000 pages. Therefore, UTF-8 encoding is recommended for internationalization.
This article Internationalization of IT products is never enough to "support English" mentions that some GBK-encoded texts have many The text that "looks the same" is actually slightly different. However, in order to save space in Unicode, the same Code Point is assigned to them.

How can we distinguish these identical characters with the same code (displaying a character in a different glyph, i.e. the same character)? This requires the help of locale.
When calculating the number of Chinese characters, it is usually done by character form, i.e., simplified, traditional, variant, new, old, etc., of a character representing the same phonetic meaning. This way of counting is in fact counting variants. Therefore, the number of glyphs included in large dictionaries has long been wrongly regarded as the size of the Chinese character system.(Wikipedia)
A locale is the language environment of the software at runtime, which includes Language, Territory and Codeset. A locale is written in the following format: Language[_Territory[. UTF8. In Linux, a locale consists of the following parts.
- LC_COLLATE: Controls character sorting.
- LC_CTYPE: controls the character handling function in handling upper and lower case or determining if it is a character.
- LC_MESSAGES: format of prompt messages.
- LC_MONETARY: format of currency.
- LC_NUMERIC: the format of the number.
- LC_TIME: the format of time.
If your locale is en_US.UTF8, you must change it to zh_CN.UTF8 to display Chinese correctly. All supported locales are stored in the /usr/share/locale directory of the macOS operating system.

The same language may have some subtle differences in different countries and regions, for example, there are some differences between American English and British English. The same country may also have multiple languages, for example, China has simplified and traditional languages. In the introduction to locale above we saw the use of language_region to express the exact language of a country.
For countries and languages ISO has developed corresponding standard codes ISO 3166-1 and ISO 639-1.
The browser uses the language code to send the name of the language accepted by the browser in the Accept-Language HTTP header. For example: it, de-at, es, pt-br.
GNU gettext is the GNU Internationalization and Localization (i18n) library, which is often used to write multilingualization (M17N) programs. Many programming languages such as C, C++, Python, PHP, Rust, Elixir, etc. support the use of gettext from within the language.
The following is the flow of how Java calls gettext to complete internationalization.

- xgettext scans the source code to extract the input strings for the i18n functions tr(), trc(), and trn() and creates a pot file containing all the source language strings. The object that the translator needs to work with is the .po file, which is generated by the msginit program from the .pot template file.
- msgmerge merges the strings into a po file containing the translations for a single locale.
- msgfmt is used to generate Java class files that inherit from the Java
ResourceBundleclass.
The following diagram shows the flow of internationalization in PHP using gettext.

Elixir implements i18n's directory structure using gettext.
priv/gettext
└─ en_US
| └─ LC_MESSAGES
| ├─ default.po
| └─ errors.po
└─ it
└─ LC_MESSAGES
├─ default.po
└─ errors.poThe process of using gettext is a typical process of making an application support i18n internationalization.
- Configure the i18n framework. i18n framework automatically obtains the relevant language files by the language identifier of the system or browser (in the case of web applications). For example, gettext uses a file with .mo suffix, while Javascript is usually a .json file and Java is a .properties file.
- extract the hard-coded source language text. Call the i18n function at the hard-coded place. For this part can be extracted manually, or automatically through a program or plugin (e.g. i18next internationalization framework for Javascript has i18next-scanner).
- finally implement localization. Translate (either manually or by machine translation, there are also relevant translation platforms that can be integrated) these extracted files in the language of the country to be supported.
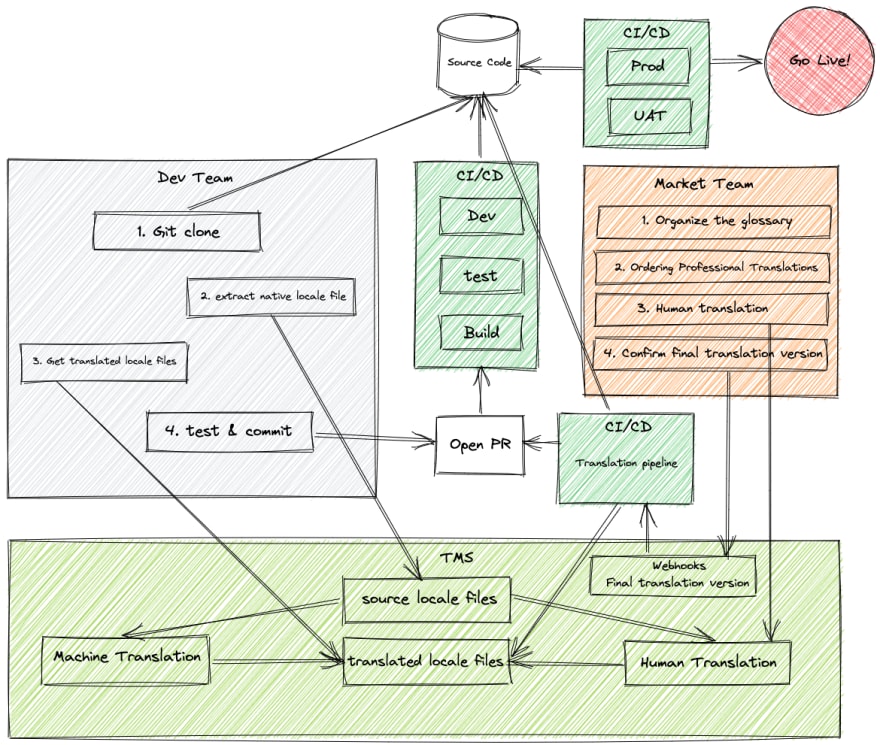
A typical localization flow chart is shown in the figure above. Among the parties involved are.
- Dev Team: Developers make the system internationalized and deploy the machine-translated version of the multilingual version to the integration environment for testers to test, and can build an automated translation integration pipeline.
- Market Team: Confirm the market and supported languages of the product, organize the glossary of terms involved in the product, and purchase professional translation services to determine the final multilingual translated version. In the case of large companies, there may be a dedicated globalization team to do this work.
- Translation management platform (TMS): completes the management of translation languages, generally with specific API interfaces or SDK development kits that can be integrated into CI/CD environments and can automate the upload and download of source and translation language files. It also has a management interface for translators to modify and determine the final version of the translation. Can provide multiple machine translation services, as well as provide human translation for purchase or complete human translation in an open source collaborative manner.
This piece begins with these basic antecedent considerations.
- Business implications of region
- Default region of the user
- Default language of the locale
- Whether different regions use the same system
- Whether to support users to switch locales
- Whether the user can belong to multiple locales
- Whether there is a one-to-one relationship between locale and country
- Mapping between locale and language
- Is there a linkage between locale and language (can the user see all languages supported by all locales)
- Whether language switching needs to be saved to the user's personal information
- Whether the user's default language needs to be set by the user's environment language identifier (OS or browser)
- Whether the service is deployed in multiple geographies and whether the data is isolated in multiple geographies
- Whether the system can support the process of adding new regions and new regions
- Whether the system can support the process of adding new languages and the process of adding new languages
- The process of localization when adding subservices to the system
- Localization process when new pages or components appear when localization is implemented
- Whether you need a translation management platform (TMS)
- Selection of Translation Management Platform
- Integration of translation management platform
- Whether to subscribe to professional translation services
- Development of collaborative processes with translation teams
- Whether each service of the system is localized by its own development team
- Whether there is a dedicated localization team to do localization
- The collaboration mode between localization team and each service development team
- Whether localization is done by code Open PR
- How each service development team does incremental localization
- Synchronization of knowledge on localization among teams
- Development of technical standards for localization and promotion within the organization
- Use of industry standard libraries (e.g. Unicode Common Locale Data Repository CLDR) for language-specific formats for dates, times, time zones, numbers, and currencies
- The locale identifier is in
language_regionformat, e.g. en_US for United States English language.
- Distinguish multilingualism by subdomains (gTLDS) or ccTLDs (e.g. ccTLDs). For example: https://en.wikipedia.org/
- Distinguish multilingualism by URL paths. For example: https://localizejs.com/de/
- Multilingual by URL query parameters (not SEO friendly). e.g. https://locize.com/?lng=de
- Multi-language by user language setting. E.g. https://myaccount.google.com/language
- Multilingual by browser local storage. E.g. https://www.instagram.com/

The challenges of localization are mainly issues arising from differences in language, culture, writing habits and laws in different geographic areas, in the following categories.
- Text encoding: For text in most Western European languages, ASCII character encoding is sufficient. However, languages that use non-Latin alphabets (e.g. Russian, Chinese, Hindi and Korean) require a larger character encoding, such as Unicode.
- Singular and plural: Different languages have different forms of singular and plural. The plural is used to represent a number that is "not one". The singular and plural forms vary from language to language, with the most common plural form being used to represent numbers of two or greater. In some languages, it is also used to represent fractions, zeroes, negative numbers, or twos.
- Image translation: Images with text need to be translated.
- Dynamic data (data from the API): The data passed from the back-end to the front-end that is displayed on the interface needs to be localized. But it is a challenge to distinguish the source of this data, for example, although the data is sourced from the back-end, it may come from a database, it may come from a file, it may come from other internal services, or it may come from a third-party dependent service.
- Icons: Some icons that are highly recognizable in one region may look completely unrecognizable to users in other regions or be something else.
- Name/address: The order of the last name and first name, and the order in which addresses are written. For example, in Chinese, the last name comes first, then the first name.
- Gender: Some languages such as French place a lot of emphasis on gender.
- Phone: The format of phone calls varies from country to country.
- Voice: Inappropriate voices or cues may be offensive, and some countries are sensitive to the gender of the voice.
- Color: Colors and shades are associated with geographic regions or markets, for example, red in the U.S. indicates a decline and in the A-share indicates a rise.
- Units of Measure
- Currency: Currency formatting must take into account the currency symbol, the position of the currency symbol and the position of the minus sign. Most currencies use the same decimal separator and thousands separator as the numbers in the regional or area setting. However, in some places this is not the case, for example in Switzerland, the decimal separator for the Swiss franc is a period.
- Date and time: The internationalization of date/time involves not only the geographical location (e.g. localized representation of calendar such as day of the week, month, etc.), but also the time zone (TimeZone, for UTC/GMT offsets). Time zones are not only geographically defined, but also politically defined. For example, China geographically spans 5 time zones, but only uses one unified time zone. Many other countries have "daylight saving time" and the difference between Berlin time and Beijing time is subject to change. Sometimes it is 7 hours (winter time), sometimes it is 6 hours (daylight saving time).
- Numbers: There are also differences in the way numbers are represented in different countries and regions. Factors that affect the representation of numbers include the representation of numeric characters, the representation of numeric symbols, the type of numbers, etc.
- Weight/length/physical units: Because of the differences in units, multiple geographical versions of the same set of data need to be converted.
- Business-related units of measurement: For example, different countries have different billing rules for their products. This requires business staff support to find out the corresponding position and give conversion rules.
- Sentence length: German is usually longer than English, and Arabic requires more vertical space.
- Writing direction: In many languages it is left to right, but in Hebrew and Arabic it is right to left and in some Asian languages it is vertical.
- Punctuation: e.g. quotation marks ("") in English, low quotation marks (,,") in German and quotation marks (<<>>) in French.
- Line breaks/splits: The rules of Asian CJK (Chinese, Japanese, Korean) character set languages are completely different from those of Western languages. For example, unlike most Western written languages, Chinese, Japanese, Korean and Thai do not necessarily use spaces to separate one word from the next. Thai does not even use punctuation.
- Case conversion: English has case conversion, while Chinese has no case distinction.
- Legal related: e.g. GDPR using personal data of EU citizens.
- Politics-related: For example, localization involves the display of flags and maps, which can easily cause major accidents if not handled properly.
- Sorting methods: For example, English is sorted alphabetically, while Chinese can be sorted in pinyin.
If you are localizing a website for toC, you need to consider some things related to search engine optimization (SEO), such as this How to approach an international strategy mentions some key points.
- If you offer your site in multiple languages, use a single language for content and navigation on each page, and avoid side-by-side translations.
- Keep the content in each language on a separate URL and mark the language in the URL. For example, the URL
www.mysite.com/de/would tell the user that the page is in German. - Display the language you want to locate to Google via the hreflang meta tag. For example,
<link rel="alternate" href="http://example.com" hreflang="en-us" />. - Do not translate only the template text, but also the content within the template.
- do not use automatic translation exclusively, which can affect the user experience
- don't use cookies or scripting techniques to switch languages, Google crawlers can't index this content properly.
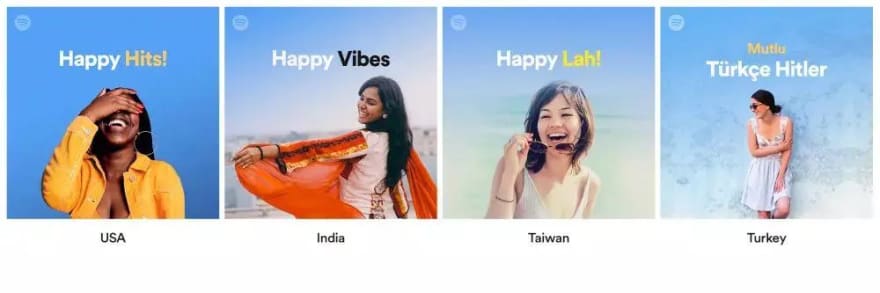
Using a more localized design for the same content in different geographies can lead to better results, as mentioned in the article Internationalization and Localization of Product Design about the different presentation of Spotify's song covers in different countries.
The localization process for a single application is relatively simple from an architectural point of view. However, many applications nowadays are microservice architectures with multiple teams collaborating on the development model. If individual teams are responsible for the localization of their respective services, there must be a unified localization committee to develop technical standards for localization.
- The identification of language markers.
- The design of language switching in front and back-end solutions.
- The design of translation automation process, etc.
Or there is a dedicated localization team to implement localization, and this team will be responsible for solving the previous problems. The project I am involved in falls into the latter category. Our team completed the localization of nearly a dozen microservice subsystems for the entire large system, and these dozens of systems were handled by several large groups of multiple teams, so the collaborative process of such cross-functional requirements (CFR) across multiple teams is a complex task.
Prior to the implementation of localization, it is important to identify the relevant technical or operational standards, some of which are.
- Internationalization implementation standards for different technology stacks in front and back ends. Since there may be multiple technology stacks in microservices, each with its own internationalization implementation, the development of implementation standards for different technology stacks can help to use the same implementation across services.
- The determination of locale markers.
- The possibility of storing language-related text in front-end or back-end static text extraction to files named by language identifiers, e.g. en.json for static text in English, and en_US.json for text related to US English (e.g. units of measure, dates, numbers, currency, etc.).
- The
language_regionformat is uniformly used in remote service calls (front-end calls to back-end or back-end calls to other internal or external services), e.g. en_US stands for getting the localized version of the English language for the US region.
- Language specific formats for dates, times, time zones, numbers and currencies use industry standard libraries. For example, using libraries that implement the CLDR standard.
- Dynamic data type identification. Identifying, for example, which data comes from internal systems (databases or files); which comes from external systems; whether these dynamic data have internationalization capabilities; and how to localize them in stages.
- Localization of documents. Localization of electronic documents (PDF) or emails generated by the back-office system. If these documents are sent to clients, also consider whether to generate documents in the client's language preference.
- List of supported regions and languages. For example, whether the error page is entered when an unsupported country or language appears or whether the default regional or language localized version is displayed.
- The default region and default language.
- whether the region and language have a binding relationship.
- Whether the language switch needs to be saved to the user's personal information.
In fact, the most time-consuming part of localization for our team was the start-up of the local environment. With so many services involved and slight differences in the way different services are launched, and even wrong guidance documents, we needed to keep stepping on the toes to finish setting up the environment. In the end, our way of dealing with this was to contact the development teams, and each time we did the pre-localization of a service, we would ask the development team to help us set up the local environment.
Another difficulty was our lack of understanding of the business. Since each service has a large number of components and pages, including dynamic data from different sources of back-end services, it was hard to figure out just by ourselves. In the end, when we did the pre-localization of this service, we would get business analysts from the development team to help us introduce the business processes involved in this service.
- Sorting through static text on the front and back ends to identify which systems have internationalization capabilities (initial language versions have had locale files extracted and internationalization libraries set up).
- Identifying where date, currency, and number formats occur and calling the industry standard libraries identified by the localization technical standards in those places.
- Identification of incremental static text translation processes, which need to be used to process new texts when they are added after the system has already been localized, using localization processes.
- Automated integration of translation platforms, where development teams use scripts or CI/CD streams to automatically upload and download files in the original and translated languages.
Some internationalized sites have language or region switching designed as hyperlinks that allow users to access different language and region versions of the site, which do not require storing language or region configurations.
Sites with user profile configuration generally offer to set the preferred language and region in the profile settings, so that users can synchronize the last set language or region when switching devices.
If your site users switch devices infrequently, a simple process can store these configurations in the browser store. When the user switches devices, the default settings are automatically restored. The advantage of such a design is that it is simple, and it is easier to overtake to other solutions later. The specific design chosen needs to be combined with the specific business to choose.
Localization of back-end services involves the following four components.
- Static text. These can be read by walking through the code to find the relevant string.
- Databases, caches or files. Initial data that does not meet localization needs can be found by walking through the database initialization script, but for dynamically stored data, tables need to be designed to meet multilingual storage as well. For some resource files where translation is necessary there is also a need to provide multilingual versions and to adapt the code that uses the files.
- Remote calls to other internal services (RPC). The locale markers for internal service calls are part of the localization technology standards developed. For example, the
locale = en_USHTTP header can be used to request pages in English for the United States. - Generate documents (PDF or Email). Generated documents include the final language version of the template static text and dynamic data rendering. Especially when these documents and emails need to be sent to users, they need to be generated in the language that matches the user's language.
If the technology stack of the back-end service is different, the localization team also needs to summarize the internationalization process for the different technology stacks of the back-end service and synchronize it with other development teams within the organization.
There are cases of calling external services in the backend service remote call. If you call external services, you need to confirm whether the external services support multi-language version first, and if they do, you can integrate them according to the docking documentation. If not, you need to contact the external service provider to determine the support plan.
Since the implementation of localization involves the transformation of more than a dozen subservices, localization can be controlled by Feature Toggles to be turned on or off in different environments. The tests affected by localization (unit tests, integration tests and UI tests) also need to be controlled via Feature Toggles so that the test suite of the original service is minimally affected.
Once all services have been localized and implemented, the localized Feature Toggles for all services can be opened to bring the final version online.
There are two designs to choose from regarding localized Feature Toggles.
- Centralized Feature Toggles. for example, a centralized feature configuration service can be built, and all localization-related services request this service to get the configuration switch status. The advantage is that localized features can be switched on and off in real time without going back online. The downside is that there is no flexibility to control the localized features of each service.
- Independent Feature Toggles: In contrast to centralized, each service sets its own localized Feature Toggles for flexible decoupling, but the downside is that each switch requires a new release to bring a single service online.
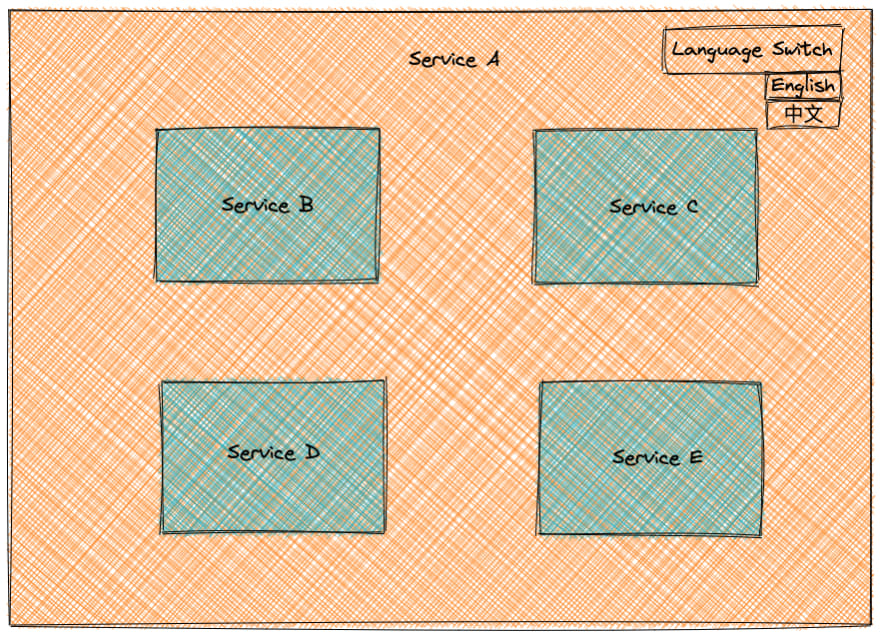
As the above figure shows a micro front-end architecture website, the whole website interface is composed of five service pages of A/B/C/D/E. The language switch button is on service A. When the user switches from English to Chinese, the other services B/C/D/E need to switch their respective interfaces to the Chinese language version.
One way is to have the internationalization (i18n) library instance initialized by Service A and mounted on the browser window object when the browser loads the page, and Services B/C/D/E use the internationalization library instance object initialized by Service A. When switching languages, the internationalization instance object of Service A switches the language of all services.
The locale files for each service can be loaded into the browser uniformly by Service A. The advantage of this approach is that we know when the last language file is loaded, which means that the localization of all services on the whole page is initialized and the user can switch languages normally.
Localization testing verifies that the application or website content meets the language, cultural and geographical requirements of a particular country or region.
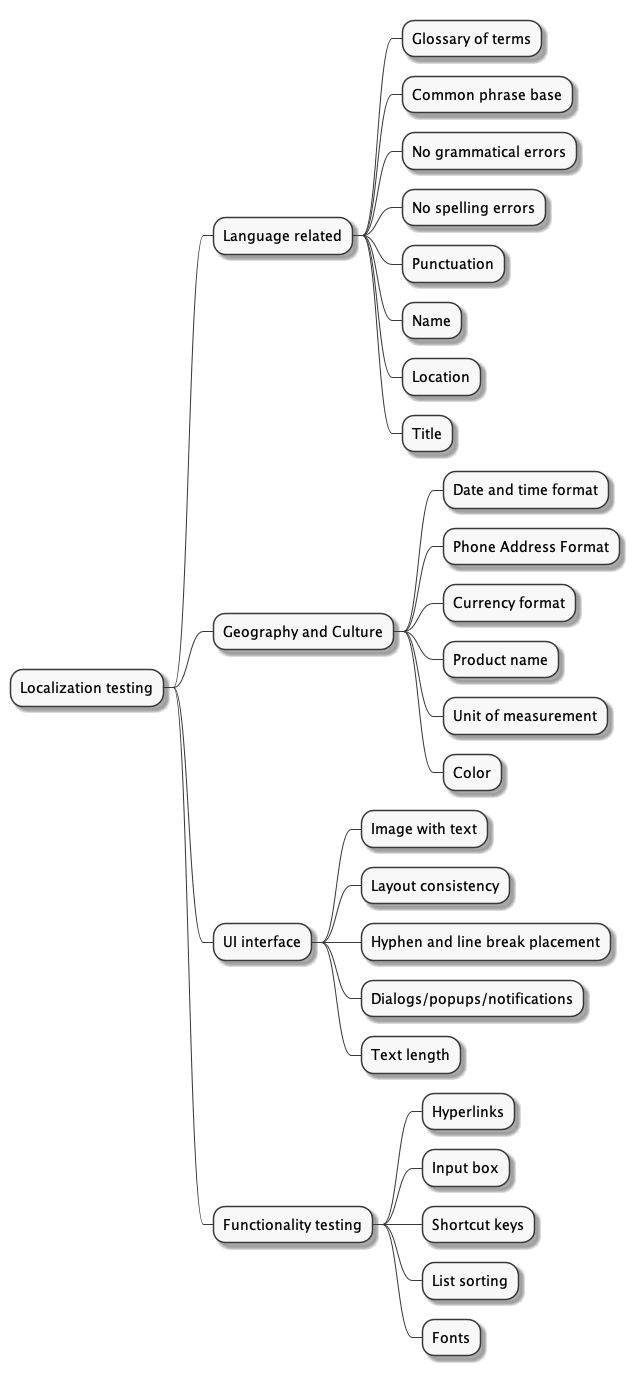
For more details, see this article Localization testing: why and how to do it.
A very important piece of localization is the selection of a suitable translation management platform (TMS), which generally has the following function points.
- Glossary: A glossary of specialized brand terms or domain terms that can help translators more accurately translate specialized language related to a product or market.
- Translation Memory (TM): TM is a database for storing strings of previously translated content. Translations are reused for the same or similar content. This ensures consistency of translations.
- Context Editor (In-Context Editor): This editor crawls website pages and allows translators to understand the context of the entire page, helping to improve the quality of the translation.
- Machine Translations (Machine Translations): most TMS platforms are docked to some machine translation platforms (such as Google Translate), which can automatically translate the target language and are suitable for developers.
- Human Translations: Professional human translation services can be ordered from the TMS platform. However, there are also features such as Crowdin, which provides localized translation collaboration for open source projects, and anyone can participate in this project for free, and the translated text with high votes will be used first.
Major localization platforms.
This concludes some introductions to internationalization and the basic process of localization. Localization is a complex task, and the biggest difficulty is not knowing enough about the target language and culture. But after you've read this article, I hope it will give you more confidence to do localization-related work.
24