
30
Confluent Schema Registry and Rust
This blog will be about the Rust library I wrote and maintain, schema_registry_converter. Since the library has little use on its own, and is about integrating data with Apache Kafka, we first need to take a few steps back.
For me having used Apache Kafka at several clients during the years, it's sometimes hard to imagine that other developers don't know anything about Kafka. There are a lot of great articles and introductions to Kafka, like Apache Kafka 101: Introduction from Tim Burgland. Kafka is different from more traditional message queues mainly because the time messages stay available for consumers is independent on how they are consumed. Multiple apps can thus read the same messages.
For the purpose of this blog it's important to know that messages are stored on Kafka as records. Records have a value and an optional key, which are both in binary format. Another important fact is that Kafka uses topics to split the messages. One topic might exist of multiple topic-partitions which are used to make it scalable. Part of the configuration is topic specific. For example, data on certain topics can be retained longer than other ones, or can be configured as compacted such that the last message with the same key will never be deleted.
Because data is stored in a binary format, it's important for apps producing data to do so in a way apps consuming the data can make sense of those bytes. An easy way to do it is to serialise the data as JSON. Especially since it's human-readable and easy to work with in most programming languages. This does make it less transparant for the consumer, and has some other downsides like the message being relatively big.
To have more control over the data, and store it in a binary format, a schema registry can be used. One the most used registries with Kafka is the Confluent Schema Registry.
So what is actually the Schema Registry? And how does it help to make sense of binary data? In essence Schema Registry is an application with some Rest endpoints, from which schema's can be registered and retrieved. It used to only support Apache Avro. Later support for Protobuf and JSON Schema was added. Part of the same Github project, and what makes Schema Registry easy to use, is a Collection of Java classes that are used to go from bytes to typed objects and vice versa. There are several classes that support Kafka Streams and ksqlDB next to the more low level Kafka [Producer(https://kafka.apache.org/documentation/#producerapi) and Consumer clients. There are more advanced use cases, but basically you supply the url for the Schema Registry, and the library will handle the rest. For producing data this will mean optionally register a new schema too get the correct id. The consumer will use the encoded id to fetch the schema used to produce the data. It can also be used with other frameworks like Spring Cloud Stream. For example in the Kotlin Command Handler by using the SpecificAvroSerde class. You might need to set additional properties to get this working.
All this is great when using a JVM language for your app, but might be a challenge when using another programming language. Part of the reason is that because the bytes produced by schema registry are specific to schema registry. There is always a 'magic' first byte, which allows for breaking changes at some point, and lets the clients know quickly whether the data is encoded properly. The reference to the schema that was used to serialize the data is also part of the data. This makes it impossible to use a 'standard' library. Since those bytes need to be removed for a 'standaard' library to work. This might be a valid reason to use something like Protobuf, combined with some documentation on which Protobuf schema was used for which topic. You also don't have to run a schema registry in that case, but for clients it's a bit more work to get the correct schema.
On the other, hand Schema Registry does offer a complete solution, where [Schema Compatibility (https://docs.confluent.io/platform/current/schema-registry/avro.html) can be configured. Because updates to schema's can be varified for backwards compatibility this way, consumers can use the old schema for the data. Storing the schema in a central location decouples the producers from the consumers. Making it much easier to add additional information later on without the need to immediately update the consumers once the producer start using the new schema. Another major advantage is the integration of Schema Registry with the Confluent Platform. Making it much easier to use of ksqlDB.
Rust is a pretty young language, the first stable version released in May 2015. I've been using Rust a couple of years, but in the early days it could be a lot of work just to get your code to compile again. Since the stable release, there has been no backwards incompatible changes. This has also paved the way for a lot of libraries, or crates as they are called in Rust. One of the major sources to start learning Rust is "the book", there are also books for specific subjects like WASM and async. There are also a lot of videos available on Youtube. One of those is this one, which I made specific for Java Developers.
Crates can be found on crates.io where you can be easily search for specific libraries, and all relevant information about the libraries is available. Rust is a c/c++ alternative, but it can in some cases be an alternative to Java as well. This largely depends on and what the app does, and if for the libraries used, there are Rust alternatives available.
Rust itself is open source. With the creation of the Rust foundation its future is secure. Personally I really like the tooling, like rustfmt and clippy which work as a default and easy to install formatter and linter respectively. Another nice thing is being able to write tests as documentation, with the documentation being available online like the AvroDecoder stuct from the schema_registry_converter library.
What originally was created as a project used in a workshop with my Open Web colleagues has turned out to be my goto project for experimentation. The full story can be found on Dev.to. Basically it's a couple of small services that together create a virtual bank where users can log in, get an account, and transfer money. One of the iterations was used for a blog with Confluent. It's relevant for this blog as the core of the schema_registry_converter came into existence creating a Rust variant for the Command Handler part of the demo project. For that project I was using schema registry, and since I wanted to keep the rest of the system the same, I didn't want to change the binary format used with Kafka.
Like I mentioned, using schema registry with a non JVM language can be challenging. Luckily I had some previous knowledge about the internals of Schema Registry from my days at Axual. When I tried to use Rust together with the Schema Registry, Avro was the only supported format. I quickly found out there was also already a Rust library supporting Avro. So it seemed with just a couple of Rest calls to the Schema Registry server, and using the library I should be able to get it to work, which I did. The result with an early version of the library can be found in kafka_producer.rs and kafka_consumer.rs.
The source for the current version of the library can be found on Github. I had to increase the major version because I needed to break the API in order to support all formats supported by the current Schema Registry version. I also added the possibility to set an API key, so it can be used with Confluent Cloud, the cloud offering from Confluent. As part of the latest major refactoring it's also supporting async. This might improve performance of your app, and is also the default for the major Kafka client, more information about why you would want to use async can be found in the async book. The schemas retrieved from the Schema Registry are cached. This way the schema is only retrieved once for each id, and reused for other messages with the same id.
Next to the additional formats there was one other major change to incorporate from Schema Registry. In order to reuse registered schemas with new schemas they made it possible to have references. So when retrieving a schema, one or more pointers to other schemas might be part of the returned JSON. To make sure I got this part right in the Rust library I created a Java project which can be used from docker.
Another interesting challenge was getting the protobuf implementation correct. Contrary to Avro or JSON Schema, one proto file can describe multiple messages. In order to properly serialise the data, the kind of message used also needs to be encoded. While for Java the same part was a pretty trivial, because the Protobuf library used had an easy way to map a number to a message. I could not find something similar in Rust, so in proto_resolver.rs I used a lexer to provide the needed functionality.
What the library does is different for a producer and a consumer. For both there are action diagrams.
Producer action diagram
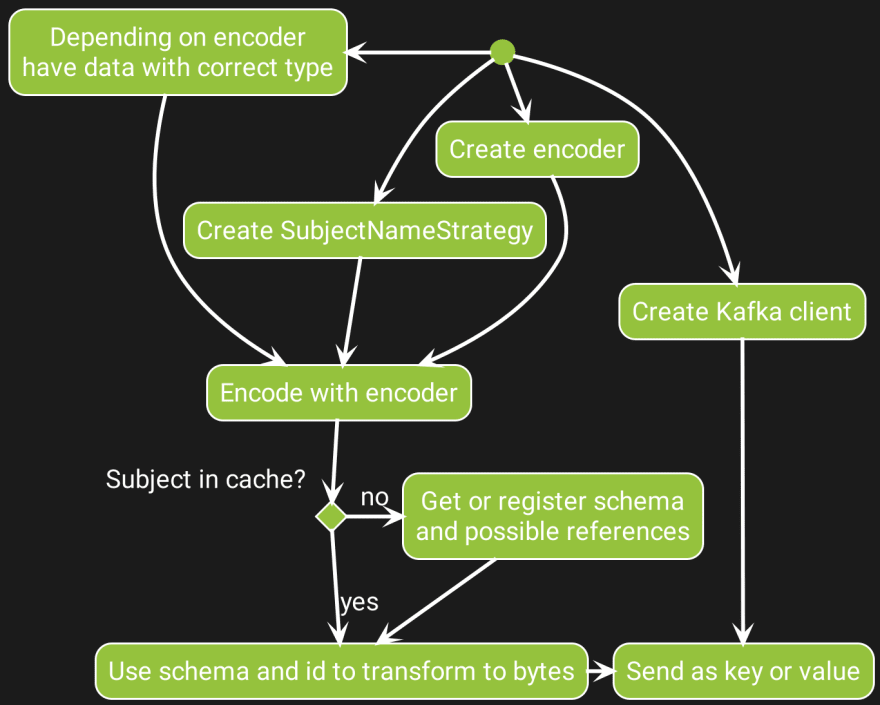
For the Producer it needs to encode the bytes in the proper way. This starts by enabling the feature (?MT what does feature mean here) of the correct encoder, depending on the format, and whether blocking or async is required. Then the data needs to be encoded using the encoder and one of the SubjectNameStrategies which might contain a schema. With the option of using the cache, a byte value is produced that can be used as either the key or value part of a Kafka record.
Consumer action diagram
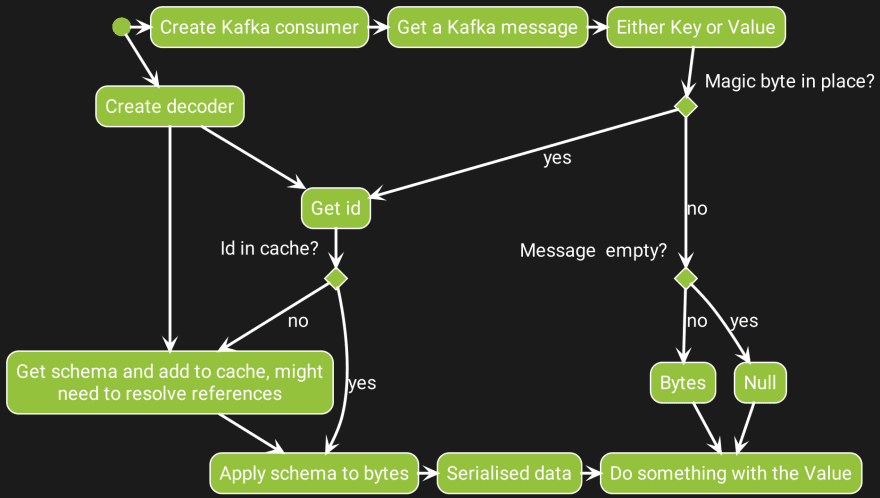
For the consumer it's also needed to use the correct decoder, based on the expected format of the message. From the Kafka record either the key or value bytes is used. With the encoded id the matching schema will be retrieved or fetched from the cache. Depending on the decoder used a certain typed value is returned. Depending on the app this value can be used for several things, for example to write something in a database.
Because of the three formats, and the two ways of using the library, async and blocking, it would be tedious to have examples for all. To make things worse each of these six possibilities has its own encoder and decoder. Where the encoder is used for a producer and a decoder for a consumer. Both also have their own separate possibilities. For the producer it's possible to register a new schema, if the latest is not the same one, or use a schema that was already registered. For the consumer it can be a challenge to use the resulting typed struct, where it might be needed for Avro to have an Enum with all the expected possibilities. Similar to what was used for the AvroData in the demo project.
Some simple examples are available in the library itself like the async Avro Decoder:
use avro_rs::types::Value;
use schema_registry_converter::async_impl::schema_registry::SrSettings;
use schema_registry_converter::async_impl::avro::AvroDecoder;
async fn test() {
let sr_settings = SrSettings::new(format!("http://{}", server_address()));
let mut decoder = AvroDecoder::new(sr_settings);
let heartbeat = decoder.decode(Some(&[0, 0, 0, 0, 1, 6])).await.unwrap().value;
assert_eq!(heartbeat, Value::Record(vec![("beat".to_string(), Value::Long(3))]));
}In order to prepare for a future blog with Confluent I wanted to play around with ksqlDB, which was the perfect opportunity to use the Rust library in a less trivial way. As it turned out there is even a library for communicating with ksqlDB from rust, using the Rest API. The PoC project for this contains some code to put protobuf data on a topic.
When I took the steps to turn the code I had into a library, I wanted to make sure I had decent code coverage. By leveraging codecov I now get updates on the code covered in pull requests. Not that there are many since the library does what it does, which is nicely scoped. The latest update was just updating dependencies, which might sometimes give problems especially for libraries like Avro, when the byte code used is not the same. A small update I'm thinking about adding it making it slightly easier to use protobuf when you know there is only one message in the proto schema.
Aside from the big rewrite, maintaining the library has taken very little time. From time to time there is a question about the library. It is nice to see people actively using it and hearing about how the library is used. Crates.io shows the amount of downloads over the last 90 days. What's interesting is that, from the start of this year, instead of a flat line, there are clear peeks during working days. This is just one of the signs Rust is getting more mature and used in production. I still haven't used it in a 'real' project yet, but that's just a matter of time. Recently the library was used in a Hackathon with a contribution as result which is part of the 2.1.0 release. The pull request made it possible to supply configuration for custom security of the schema registry.
Generally I enjoyed the time working on the library. Compared to Java, which has a much more mature ecosystem it's much easier to create a library which really adds value. Things like good error messages, and linter make it easier to create code I'm confident enough about to share with the community. For any questions regarding the library please use Github Discussions so that others might benefit from the answer as well.
30