
32
Reactive Programming 🌫️ - Demystified using RxJS
If you're looking for an RxJS quick start then this article is not for you!
Here I will be tackling Reactive Programming with the goal of shedding some light over its unreasonably illusive world using RxJS as an example.
I will be explaining the core Reactive Programming concepts, relating them to RxJS and how they work in practice. Hopefully, by the end of the read, you'll have a truer understanding of RxJS and should be able to quickly pick up any Rx Implementation to start coding with.
RxJS is an API for asynchronous programming
with observable streams.
To understand what this means we need to define what is meant by asynchronous programming and observable streams.
The best starting point can only be Reactive Programming itself!
Reactive Programming (not to be confused with Functional Reactive Programming!!) is a subset of Asynchronous Programming and a paradigm where the availability of new information drives the logic forward rather than having control flow driven by a thread-of-execution.
Asynchronous Programming is a means of parallel programming in which a unit of work runs separately from the main application thread. Generally, this is achieved via a messaging system where threads of execution competing for a shared resource don’t need to wait by blocking (preventing the thread of execution from performing other work until current work is done), and can as such perform other useful work while the resource is occupied. This concept is vital for Reactive Programming because it allows for non-blocking code to be written. Bellow a visualisation of the process:
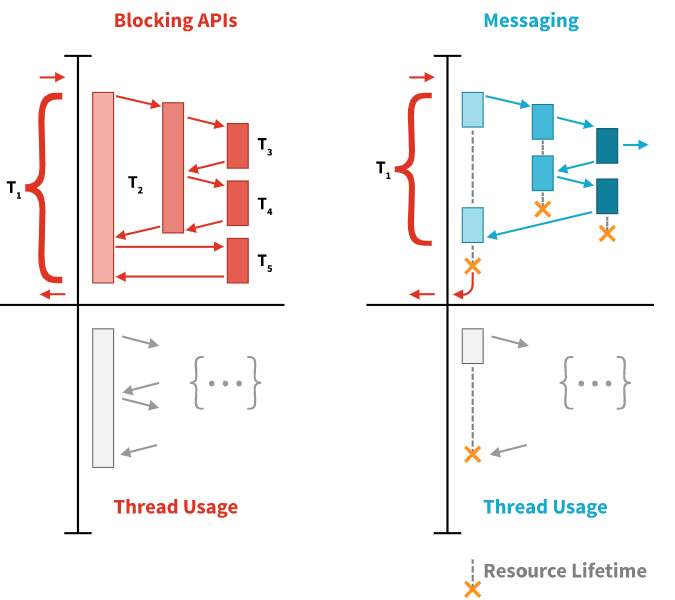
Synchronous, blocking communication (left) is resource inefficient and easily bottlenecked. The Reactive approach (right) reduces risk, conserves valuable resources, and requires less hardware/infrastructure.
Reactive Programming is generally Event-driven. Events are simply undirected messages. At their core, they are (for all intents and purposes) an extension of an event.
The Application Program Interface (API) for Reactive Programming libraries are generally either:
- Callback-based: where anonymous, side-effecting callbacks are attached to event sources and are being invoked when events pass through the dataflow chain.
- Declarative: through functional composition, usually using well-established combinators like map, filter, fold etc.
- Responsive: responsive systems focus on providing rapid and consistent response times.
- Resilient: resilient systems handle problems as they occur and stay responsive in the face of failure.
- Elastic: elastic systems stays responsive under the varying workload and ergo have the ability to scale.
- Message Driven: message-driven systems rely on asynchronous message-passing to establish to ensure that change is propagated between components without interruptions.

How do these two relate? In summary:
- Reactive Programming is a technique for managing internal logic and dataflow transformation within components of a system. It is a way of providing clarity, performance and resource efficiency of code.
- Reactive Systems is a set of architectural principles. It puts emphasis on distributed communication and gives us tools to tackle resilience and elasticity in distributed systems.
Reactive Programming should be used as one of the tools to construct a Reactive System.
Right, so, what is exactly is Reactive Programming? There are many definitions out there... some of which I think not even their authors understand what they mean. In the wise words of @andrestaltz - "Lets cut the bullshit"
Reactive programming is programming with asynchronous data streams.
Beautiful, concise and above all explainable! In fact, this definition is almost the same as the statement about RxJS I presented before. That is because RxJS is within the Reactive Programming paradigm.
From now on we assume Reactive programming with streams. There are other types of implementations that can also be considered within the paradigm, such as: Promises/Futures and Dataflow variables.
Now, as promised, I'll be showing you guys what is meant by 'asynchronous data streams'.
The key idea in Reactive Programming is that everything (for the most part) can be a stream. Streams are cheap and ubiquitous.
A stream is a sequence of ongoing events ordered in time. It can only emit 3 things: a data typed value, an error, or a termination signal.
This definition is important to remember since it remains the same no matter the implementation of the paradigm.
The way I like to think about streams is by visualising a water pipe with a closing mechanism where each water molecule (or set of) is an emitted value.

The closing mechanism can be triggered manually by turning the tap, representing a termination signal, or implicitly, if the pipe fails to do its function, representing an error. A closed pipe can no longer push out water and we call it a completed stream.
Now, let us focus on the first sentence of our definition: 'A stream is a sequence of ongoing events ordered in time.'

In other words, water droplets (data) are being pushed out of the pipe (stream) as time (program execution) passes. How do we capture these droplets to act on them?
In most implementations of Reactive Programming, we capture these emitted events only asynchronously, by defining functions that are called and passed one of the three appropriate outputs as a parameter:
- On value emission: Each time a value is pushed through the stream it will be emitted and captured here. Can happen multiple times.
- On error emission: When the stream error it will be captured here and the stream terminates. Happens only once.
- On termination: When the stream is terminated it will be captured here. Happens only once.
That covers capturing. It's time to move into the manipulation of streams themselves. We do this via Operators.
Operators offer a way to manipulate streams by transforming them. A transformation, in our context, is simply a function f that maps a stream into another stream, i.e. f: S1 → S2 This function we call an operator.
To visualise this simple imagine placing one or more appliances within the pipeline of our stream. These appliances could have filters in them or could modify the contents of the water (or other transformations) thereby transforming our stream into a new stream.
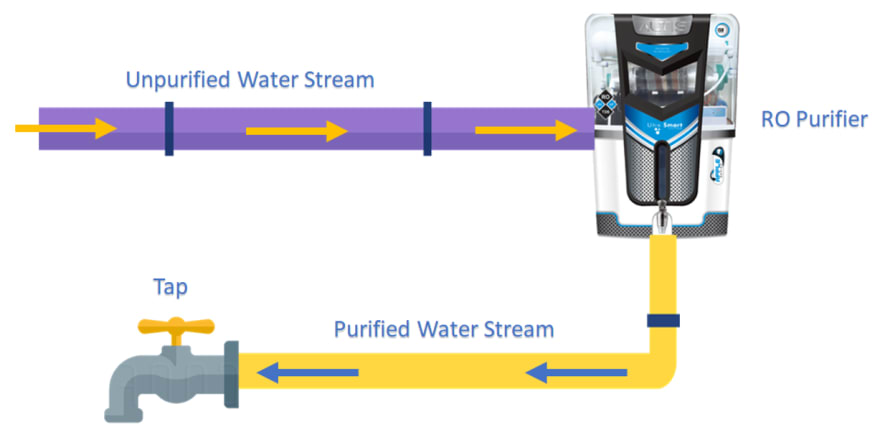
In the image above, our initial stream of type 'Unpurified Water' was transformed into a stream of type 'Purified Water' transforming the data that gets observed at the end of the pipeline from its original form.
To explain operators and their effects on real streams of data we will have to dive into the world of Marble Diagrams.
Before explaining marble diagrams we need to improve our terminology a little bit.
Now, because we will be dealing with ReactiveX in the next chapter, it's time to introduce some of the required terminologies. Don't worry, for now, I will only be giving abstracted definitions to a few terms that map to terms I've already covered. Below, the same diagrams as before, but with the new terminology included.
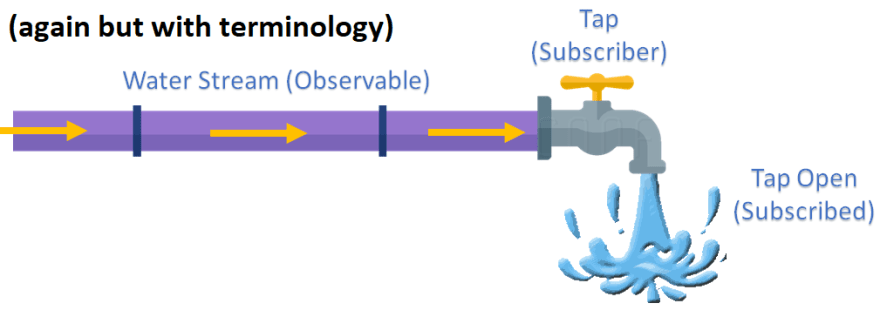
and for the operator diagram,

Simple definitions for these terms are:
- Stream -> Observable: A structure representing a stream of values over time.
- Tap -> Subscriber: Sometimes called the consumer, the code that calls the subscription process on an observable structure.
- Turning the tap -> Subscription: The method that opens the stream for the observer.
- Closing the tap -> Completing: The action of marking the stream as completed meaning it is terminated.
- Bucket -> Observer: The structure that captures our pushed values allowing us to act on them.
- Appliances -> Operators: Functions that transform the stream.
We will be returning to more precise definitions later since they are pretty much required to read any sort of RX documentation without inducing a headache. So don't worry if you don't quite understand what these mean yet.
However, we will be using this new terminology from now on so I recommend keeping the term mapping in your head.
Okay, time for actual marble diagrams!
Learning Reactive Programming can be a daunting task so the Rx team came up with the concept of marble diagrams to help with visualising observables and their operators. These diagrams are incredibly intuitive and are commonly found in any Rx Operator documentation. They allow for an easy understanding of the operators without having to read much else. A good alternative to a chunky wall of text filled with terminology! I'll try to explain how to read them as best I can:

Okay... my bad haha, sorry! Let's go step by step.
Marble diagrams describe observables. Observables are streams of values through time. So, we need a time axis!

Now that we have a time axis we need to represent our observable outputs. If you recall our earlier definition, an observable can only output a value, a termination signal or an error.
Let's start with the easy one, the termination signal:

In similar fashion, we have our error output:

Finally, lets represent our emitted value:

There can be multiple values across the time axis as long as there is no termination or error output behind them as those will unsubscribe from the observable.
Done, simple right? On to the next part: operators in marble diagrams!
As previously mentioned, operators are functions that transform observables. That means they take as input one or more observables and output a new observable. We can represent them in a marble diagram like so:

The block in between is our operator function, taking in an observable and returning another. So, our function is filtering the input observable by taking the modulus 2 to determine whether a pushed value is even and if it is it allows that push value to pass through, essentially, filtering the stream.
As mentioned before, operators can have more than one observable as input, such as the case for operators such as switchMap

The switchMap operator is a very popular one that has a handful of practical applications. It is generally used to implement a discard action between the input streams which can save a lot of trouble and computation in practice.
In summary, every time the Input Observable 1 emits a value, Input Observable 2 emits all of its values unless Input Observable 1 emits a new value before the Input Observable 2 completes. If you look at the output observable you will notice that there are only two 30's. This is because Input Observable 2 could not be complete before Input Observable 1 emitted the value 5. You easily confirm this because the space between 3 and 5 is much less than the size of the axis for Input Observable 2, suggesting there was only time to emit the first two values.
RxJS is a library extending ReactiveX for composing asynchronous and event-based programs by using observable sequences with JavaScript. It provides one core type, the Observable, satellite types (Observer, Schedulers, Subjects) and operators (map, filter, reduce, every, etc) to allow the manipulation of the observable streams with easy and significantly reducing the amount of code needed to solve asynchronous problems.
- Growing very rapidly.
- RxJs alone has 25mil weekly downloads.
- Provides a very high-quality asynchronous API.
- Lightweight & memory optimised.
- Easy error handling.
- Makes asynchronous programming much faster in most applications.
- Relatively steep learning curve.
- Implies a functional programming style (data immutability).
- Testing/debugging can be a learning process.
In RxJS some arguably established definitions are:
- Observable: represents the idea of an invokable collection of future values or events.
- Observer: is a collection of callbacks that knows how to listen to values delivered by the Observable.
- Subscription: represents the execution of an Observable, which is primarily useful for cancelling the execution.
- Operators: are pure functions that enable a functional programming style of dealing with collections with operations like map, filter, concat, reduce, etc.
- Subject: is equivalent to an EventEmitter, and the only way of multicasting a value or event to multiple Observers.
- Schedulers: are centralized dispatchers to control concurrency, allowing us to coordinate when computation happens on e.g. setTimeout or requestAnimationFrame or others.
- Producer: The code that is subscribing to the observable. This is whoever is being notified of nexted values, and errors or completions.
- Consumer: Any system or thing that is the source of values that are being pushed out of the observable subscription to the consumer.
- Unicast: The act of one producer being observed only one consumer. An observable is "unicast" when it only connects one producer to one consumer. Unicast doesn't necessarily mean "cold".
- Multicast: The act of one producer being observed by many consumers.
- Cold: An observable is "cold" when it creates a new producer during subscribe for every new subscription. As a result, a "cold" observables are always unicast, being one producer observed by one consumer. Cold observables can be made hot but not the other way around.
- Hot: An observable is "hot", when its producer was created outside of the context of the subscribe action. This means that the "hot" observable is almost always multicast. It is possible that a "hot" observable is still technically unicast if it is engineered to only allow one subscription at a time, however, there is no straightforward mechanism for this in RxJS, and the scenario is unlikely. For the purposes of discussion, all "hot" observables can be assumed to be multicast. Hot observables cannot be made cold.
- Push: Observables are a push-based type. That means rather than having the consumer call a function or perform some other action to get a value, the consumer receives values as soon as the producer has produced them, via a registered next handler.
- Pull: Pull-based systems are the opposite of push-based. In a pull-based type or system, the consumer must request each value the producer has produced manually, perhaps long after the producer has actually done so. Examples of such systems are Functions and Iterators
By now we should agree that observables are simply structures that lazy push collections of multiple values. Subscriptions are the resulting structure representing a disposable resource, usually the execution of an Observable.
Heres how we code them in RxJS:
import { Observable } from 'rxjs';
/* Instantiate an observable */
const observable = new Observable(subscriber => {
subscriber.next(1); // pushes a value
subscriber.next(2); // pushes another value synchronously
setTimeout(() => {
subscriber.next(3); // pushes last value after a wait of 1s
subscriber.complete(); // terminates observable stream
}, 1000);
});
/* Subscribing to an observable */
console.log('just before subscribe');
const subscription = observable.subscribe({
// The three possible output captures:
next(x) { console.log('got value ' + x); },
error(err) { console.error('something wrong occurred: ' + err); },
complete() { console.log('done'); }
}); // creates subscription object
console.log('just after subscribe');
/* Unsubscribing to an observable using subscription */
setTimeout(() => {
subscription.unsubscribe();
}, 500);
// Logs:
// just before subscribe
// got value 1
// got value 2
// just after subscribeNotice how we never see the value 3 logged because we cancel our subscription before it is emitted through the closure function passed to setTimeout.
However, this does not mean the value was not emitted, it was, we just don't see it because we stopped subscribing. The stream was not terminated via the act of unsubscribing.
A cold observable starts producing data when some code invokes a subscribe() function on it.
A cold observable:
import { Observable } from "rxjs";
// Creating a cold observable
const observable = Observable.create((observer) => {
observer.next(Math.random()); // We explicitly push the value to the stream
});
// Subscription 1
observable.subscribe((data) => {
console.log(data); // 0.24957144215097515 (random number)
});
// Subscription 2
observable.subscribe((data) => {
console.log(data); // 0.004617340049055896 (random number)
});A hot observable produces data even if no subscribers are interested in the data.
A hot observable:
import { Observable } from "rxjs";
// Coming from an event which is constantly emmit values
const observable = Observable.fromEvent(document, 'click');
// Subscription 1
observable.subscribe((event) => {
console.log(event.clientX); // x position of click
});
// Subscription 2
observable.subscribe((event) => {
console.log(event.clientY); // y position of click
});The main differences are:
- Promises are eager. Observables are lazy.
- Promises are single-value emissions. Observables are multi-value streams.
- Promises have no cancelling or operator APIs. Observables do.

A stackblitz example of RxJS vs Promises: https://stackblitz.com/edit/classicjs-vs-rxjs
Although observables are not an extension of the Promise/A+ specification, RxJS still provides means to transform an observable into a true Promise. An example follows:
import { Observable } from "rxjs";
// Return a basic observable
const simpleObservable = val => Observable.of(val).delay(5000);
// Convert basic observable to promise
const example = sample('First Example')
.toPromise() // Now its a promise
.then(result => {
console.log('From Promise:', result); // After 500ms, output 'First Example'
});With the use of RxJS's toPromise method, any observable can be converted to a promise. Note that because it returns a true JS Promise, toPromise is not a pipable operator, as it does not return an observable.
In practice, an Observer is a consumer of values delivered by an Observable. Observers are simply a set of callbacks, one for each type of notification delivered by the Observable: next, error, and complete. The following is an example of a typical Observer object:
const observer = {
next: x => console.log('Observer got a next value: ' + x),
error: err => console.error('Observer got an error: ' + err),
complete: () => console.log('Observer got a complete notification'),
};
// To use it, pass it to a subscribe
observable.subscribe(observer);That's it for observers, really!
RxJS is mostly useful for its operators, even though the Observable is the foundation. Previously we studied operators as functions that transformed streams. Nothing changes here, just terminology!
RxJS has a (very) vast library of operators. We will only be touching on a few simple ones to cover what we've talked about already:
import { from } from "rxjs";
import { filter } from "rxjs/operators";
from([1, 2, 3, 4, 5]).pipe(
filter((x) => (x % 2) === 0)
).subscribe(console.log); // [2, 4]
If you remember our filter example from before this should be fairly simple to understand!
A pipeline is simply a series of operators that get executed in order. Something obvious but that people forget, every pipeline operator must return an observable.
The same exmaple as before but with chaining operators:
import { from } from "rxjs";
import { filter, take, map } from "rxjs/operators";
from([1, 2, 3, 4, 5]).pipe(
filter((x) => (x % 2) === 0),
take(1),
map((firstValue) => "The first even number was " + firstValue)
).subscribe(console.log);There are a ton more operators that do vastly different things in categories such as: Creation, Filtering, Combination, Error Handling, Transformation, Multicasting, etc. I encourage you to try a few from each of the categories out. This is the power of RxJS, there's a lot already done for you!
A Subject is like an Observable, but can multicast to many Observers. Subjects are like EventEmitters: they maintain a registry of many listeners. In fact, part of a subject is literally an observable and you can get a reference to that observable.
The easiest way to think of a subject is quite literally:
- Subject = Observer + Observable
Example:
import { Subject, from } from 'rxjs';
const subject = new Subject<number>();
subject.subscribe({
next: (v) => console.log(`observerA: ${v}`)
});
subject.subscribe({
next: (v) => console.log(`observerB: ${v}`)
});
subject.next(1);
subject.next(2);
// Logs:
// observerA: 1
// observerB: 1
// observerA: 2
// observerB: 2
const observable = from([1, 2, 3]);
observable.subscribe(subject); // You can subscribe providing a Subject
// Logs:
// observerA: 1
// observerB: 1
// observerA: 2
// observerB: 2
// observerA: 3
// observerB: 3IMO, the best use case for Subjects is when the code it is referenced in is the one that is producing the observable data. You can easily let your consumers subscribe to the Subject and then call the .next() function to push data into the pipeline. Be wary of overusing them since most problems are solvable with only data transformation and Observables.
Finally, schedulers! They might seem hard to understand but are quite simple at a surface level which is more than enough for us to know about. In essence, schedulers control the order of tasks for Observables. There are only a few of them and they won't be changing anytime soon, here they are:

You can use schedulers by passing them to observables through a handful of operators (usually of the creation category) as arguments. The most basic example, forcing a synchronous observable to behave asynchronously:
import { Observable, asyncScheduler } from 'rxjs';
import { observeOn } from 'rxjs/operators';
const observable = new Observable((observer) => {
observer.next(1);
observer.next(2);
observer.next(3);
observer.complete();
}).pipe(
observeOn(asyncScheduler)
);
console.log('just before subscribe');
observable.subscribe({
next(x) {
console.log('got value ' + x)
},
error(err) {
console.error('something wrong occurred: ' + err);
},
complete() {
console.log('done');
}
});
console.log('just after subscribe');
// Logs
// just before subscribe
// just after subscribe
// got value 1
// got value 2
// got value 3
// doneNotice how the notifications got value... were delivered after just after subscription. This is because observeOn(asyncScheduler) introduces a proxy Observer between the new Observable and the final Observer.
Other schedulers can be used for different timings. We are done!
- RxJS visualizer: https://rxviz.com/
- Instant marble diagrams: https://thinkrx.io/
- Docs with marble diagrams: https://rxmarbles.com/
- Operator decision tree: https://rxjs.dev/operator-decision-tree
- https://gist.github.com/staltz/868e7e9bc2a7b8c1f754
- https://www.reactivemanifesto.org/
- https://en.wikipedia.org/wiki/Reactive_programming
- https://www.zachgollwitzer.com/posts/2020/rxjs-marble-diagram/
- https://medium.com/@bencabanes/marble-testing-observable-introduction-1f5ad39231c
- https://www.lightbend.com/white-papers-and-reports/reactive-programming-versus-reactive-systems
32