
41
How you can track your personal finances using Python 🐍
In this post, I'd like to describe how you can track your personal finances using a workflow that is highly focused on data privacy, is 100% self-hosted, and uses only the Python ecosystem.
I'm also secretly hoping that some of you find this interesting enough to explore it in more detail. 🙂
We all know that money is important. Having money buys us freedom and lack of money is stressful. So how do we know whether we're doing good on that front?
The answer is simple: we track our money.
We keep an eye on how much money is coming in to our accounts, how much is going out, and when and how often those events are happening. We keep an eye out on trends, what are the recurring expenses, how many of those are necessary, so on and so forth.
There's a good chance that you're doing this already. There are plenty of off-the-shelf solutions one can pick from for this purpose. There are mobile and SaaS apps that can connect to all your bank accounts, import all your financial transactions, and show you consolidated data.
Not that there's anything particularly wrong with such apps. I'm instead of the opinion that my financial data (from across all my bank accounts) is something only I should have consolidated access to. Financial data is one of the most privata data I own. So limiting the possible attack vectors sounds to me like an obvious choice.
If you're out searching for such software and limit your search to open-source only solutions, you're most likely going to come across Plain Text Accounting, which is something I'll describe in this post.
TL:DR: Maintaining double-entry accounting based records of your financial transactions in plain-text files is the way to go.
Double-entry accounting is a great way to track your finances. In this system, the flow of money between accounts is represented using transactions. You can think of a transaction as an "entry" of sorts that talks about a specific instance of money flowing between accounts. In most cases, transactions are composed of two "legs", where one leg is the credit side and the other one is the debit side.
One of the most important rules of double-entry accounting is that the sum of the amounts of the individual legs in a transaction must be zero. A transaction is said to be "balanced" if this rule is satisfied.
Here's a sample transaction to help you visualize this:
2021-01-01 * "AMAZON.DE"
Assets:MyBank -42.00 EUR
Expenses:Amazon 42.00 EURThis transaction represents an Amazon purchase I made where the money was deducted from one of my accounts (called
Assets:MyBank) and added to an Amazon expense account.A collection of such transactions is what makes up your financial ledger.
The Python ecosystem contains a really neat package called Beancount.
Beancount is a command-line implementation of the double-entry accounting system that works on top of plain-text files. It mainly provides the following three things:
As with most Python packages, getting started is as easy as creating a virtual environment and running
pip install beancount.I wrote earlier that one of the main things that Beancount provides is a language specification for defining financial transactions in a plain-text format.
What does this format look like? Here's a quick example:
option "title" "Alice"
option "operating_currency" "EUR"
; Accounts
2021-01-01 open Assets:MyBank:Checking
2021-01-01 open Expenses:Rent
2021-01-01 * "Landlord" "Thanks for the rent"
Assets:MyBank:Checking -1000.00 EUR
Expenses:Rent 1000.00 EURWhat you see here is a very basic financial ledger of an imaginary person.
In the first few lines we specify some metadata. Then we open (initialize) two Accounts. And the last three lines define a transaction where rent was deducted from one of those accounts and debited to the other one.
Note that the account names don't always have to correspond one-to-one to real-world accounts. You can define as many accounts as you like, each for a specific purpose. For instance, you can have one account to track your supermarket expenses, one for rent, one for Netflix, so on and so forth.
As I said, this is a very basic example. Real-world ledger files tend to be much longer.
For instance, at the time of this writing my personal
.beancount file contains close to 21,000 lines.~/Work/finances main ❯ wc -l goel.beancount
20996 goel.beancountI hope that at this point you have a basic understanding of Beancount and double-entry accounting. In this section, I'll quickly run you through how data flows in such a system.
The core idea with Beancount is that the user is responsible for storing all their financial transactions inside their
.beancount file. This file acts as the single source of truth for all your financial data from all your banks.So how do your transactions from your bank(s) end up in this file? In a series of three simple steps:
Almost every bank allows you to export your data in some form. You should be able to log in to your bank's website, select a timeframe, and download all the transactions in a given file format. This usually tends to be CSV, but you can also download a PDF or sometimes an OFX file.
This is the first step in a Beancount-driven workflow: download all your original data to your machine.
Note that ideally this should be something that Python can parse without much ceremony. For instance, if I would have the choice between CSV and PDF, I would most likely pick a CSV download. Not because Python cannot parse PDF data (because it can) but because CSV is a much simpler data format than PDF.
The next step is to take these CSV files and convert this data into a format that Beancount understands.
Beancount provides an importer framework to help with this process. Importers are Python programs which take a source file (eg. the downloaded CSV), parse it, and convert the data into data structures that Beancount provides. A text representation of these data structures is what makes up your personal ledger.
Now, obviously Beancount does not know about all the banks on the planet and what their CSV exports look like and how they should be parsed. This is where the Python developer inside you can shine.
The
Importer classes shipped with Beancount are more like protocols. The base class is literally called ImporterProtocol. They define method signatures and leave the implementation up to you. This way, you can inherit the base ImporterProtocol class for your own importer, override the relevant methods, and let Beancount know of the existence of these importer classes using a configuration file.from beancount.ingest.importer import ImporterProtocol
def convert_to_beancount_data_structs(line):
"""
Implement me!
"""
class MyBankImporter(ImporterProtocol):
def extract(self, file):
"""
Read and parse the file and convert the original data into Beancount
data structures
"""
entries = []
for line in file:
entries.append(convert_to_beancount_data_structs(line))
return entriesDepending on what banks you have accounts with, you can define multiple such importer classes and let Beancount know of their existence in a configuration file. Everything else will be handled for you automatically using the command line scripts included in Beancount.
The next step is also the most fun part (at least I find it fun).
We take the output of the previous step, pipe everything over to our
.beancount file, and "balance" transactions.Recall that the flow of money in double-entry accounting is represented using transactions involving at least two accounts. When you download CSVs from your bank, each line in that CSV represents money that's either incoming or outgoing. That's only one leg of a transaction (credit or debit). It's up to us to provide the other leg.
This act is called "balancing".
For instance, assume that the output of the previous step was the following transaction:
2021-01-01 * "Landlord" "Thanks for the rent"
Assets:MyBank:Checking -1000.00 EURThe total amount of the legs in this transaction does not yet sum to zero. It's up to us to balance it.
Balancing involves figuring out what the transaction is about and assigning it an equal and opposite leg. In this case we can see that this transaction has to do with us paying rent. So the second leg should clearly contain the
Expenses:Rent account.2021-01-01 * "Landlord" "Thanks for the rent"
Assets:MyBank:Checking -1000.00 EUR
Expenses:Rent 1000.00 EURThis process of balancing is something we do for all the transactions, so that the entire ledger can be marked as balanced.
That's basically it. Those three steps, performed at regular intervals of time, should ensure that your
.beancount data contains all your financial transactions and is in good shape.I prefer doing this every month. So on the first Sunday of every month, I prepare a fresh cup of coffee, download all the CSV files, run them through my importers, and balance all the unbalanced transactions.
You might think that this is too much work. I have to admit that I had a similar thought when I started out.
In my experience so far, it has been the exact opposite. The entire process has never taken me more than 45 minutes to finish. Considering that I do this once a month, the time investment seems more than fair. And the added benefit is that by balancing these transactions by hand, I get a fairly good idea of what was happening in my accounts in the previous month.
So far we talked about entering data into the system.
The real power of personal accounting software is in showing you insights from that data. In this section I'll quickly walk you through the two tools I end up using the most:
bean-query and Fava.bean-query is a command line utility shipped with Beancount that lets you run SQL-ish queries on your financial data. The query language is specific to Beancount. But if you're familiar with SQL, you'll feel right at home with bean-query.Here's an example run from my own data where I want to know how much I spent on public transport in the last three years, grouped by the year:
beancount> SELECT \
year, SUM(number) AS total \
WHERE account ~ 'Expenses:PublicTransport' AND year >= 2019 \
GROUP BY year;
year total
---- ------
2019 672.60
2020 328.02
2021 30.50The first column in the output contains the year and the second one contains the total amount of money that I spent buying public transport tickets.
Side note: I've been working remote since 2016, but it's pretty clear from those numbers when the COVID-lockdown hit my town the most.
Fava is a community-maintained web interface for Beancount. At its core it's a Flask application which reads your
.beancount file and provides all sorts of visualizations you'll find useful.Here's a screenshot of one of the reports that Fava can generate for you:
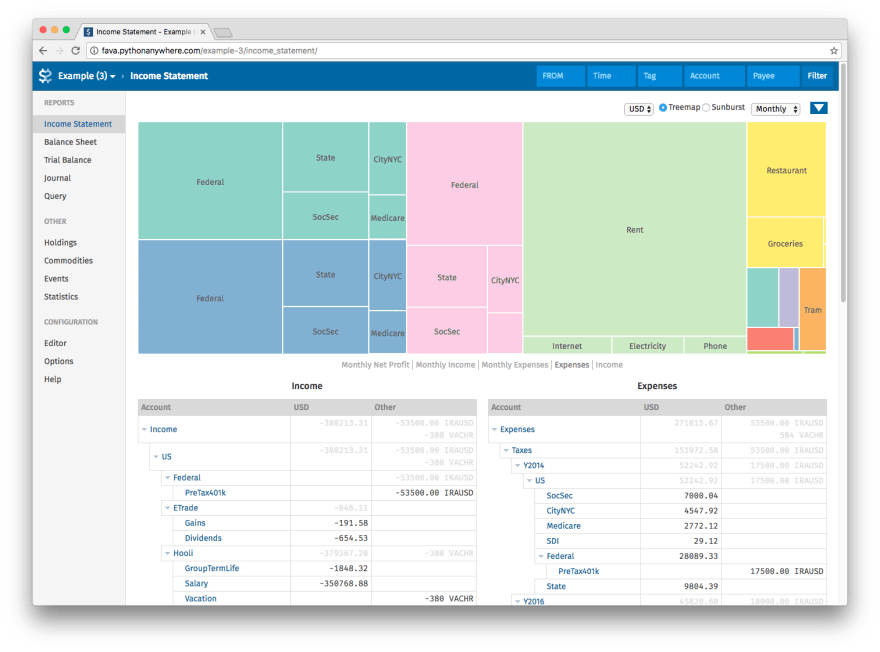
There are multiple reports built-in, for instance balance sheet, income statement, document browser (another neat feature of Beancount where you can attach documents (eg. invoices) to transactions), and more. And you can filter all the data using timeframes.
There is an online demo at this URL in case you'd like to get a feel for it: https://fava.pythonanywhere.com/.
Between Fava and
bean-query, I use Fava the most. I feel that the visualizations provided by Fava give me a really good sense of almost all the financial insights I'm looking for.That was it! Congratulations for making it this far! I hope this article was able to interest you in this privacy-focused way of tracking personal finances.
If you're interested in learning more, you should consider buying an ebook I wrote on this topic titled Tracking Personal Finances using Python. In this
ebook, I explain the concepts mentioned above in detail to help you build your own personalized multi-banking application using Python.
ebook, I explain the concepts mentioned above in detail to help you build your own personalized multi-banking application using Python.
Beancount and Double Entry Accounting can be slightly confusing to folks who are just starting out. So this ebook is my attempt at lowering the barrier to entry.
And if you have questions about any of this, feel free to reach out to me on Twitter!
41