
19
Twitch Streaming Graph Analysis - Part 1
Twitch is the world’s leading live streaming platform for gamers. The idea of exploring the Twitch dataset is to see which streamers, teams, and games are most popular. Also, we would like to see which people or bots are considered the most reliable for VIP or moderator badges. We will measure the popularity of streamers with the number of their followers and viewers. Other types of users also participate in a stream, and they are called chatters. Each streamer has a network of chatters, VIPs, and moderators, so we will use the MAGE PageRank algorithm to check for the most popular streamer. Besides that, we can calculate the betweenness centrality on this network and see which streamer has the most influence. This blog will be divided into three parts, depending on the part of the application we are building:
- Part 1: data source and backend implementation
- Part 2: frontend implementation
- Part 3: streaming data from Kafka cluster
Our app consists of five main services:
-
twitch-stream: This Python script gets new chatters for certain streamers and sends them to the Kafka cluster. -
kafka: A Kafka cluster consisting of four topics. There are two consumers (one is inmemgraph-mageand the other is in thetwitch-app) and three producers (inmemgraph-mage,twitch-appandtwitch-stream). -
memgraph-mage: The graph analytics platform that we query for relevant statistics. This platform also stores the incoming Twitch data from Kafka and performs PageRank on all streamers. -
twitch-app: A Flask server that sends all data which we query frommemgraph-magetoreact-app. It also consumes the Kafka stream and sends it to thereact-app. -
react-app: A React app that visualizes the Twitch network with the D3.js library.

The data was collected using Twitch API. The data needed to be rearranged so that it could fit the idea of graph databases. Here you can find the script that creates .csv files which we'll load into Memgraph. The files which we'll use are: streamers.csv, teams.csv, vips.csv, moderators.csv and chatters.csv. In streamers.csv we can find important information about languages the user speaks and games the user streams. Those two will actually be nodes in our graph database.

Every node except for the :User:Stream has only a name. Stream label is given to the users who have live streams. Followers and view count properties will be important in measuring their popularity. Language, team, and game could be properties on :User:Stream nodes, but since there are many users who speak the same language, belong to the same team, or play the same game, we want them to be connected. Now when we understand the Twitch network better, let's visualize this network by making the whole web application!
Since we are building a web application using many technologies, we will need to install a few tools before starting:
-
Docker and Compose:
- On Windows, you need to install Windows Subsystem for Linux (WSL) and then Docker Desktop. On Linux install Docker and Docker Compose.
-
Memgraph
- Make sure to have the latest memgraph/memgraph-mage Docker image:
docker pull memgraph/memgraph-mage
- Make sure to have the latest memgraph/memgraph-mage Docker image:
-
Node.js
- We will need Node.js for the
npxcommand which we'll use to create our React app.
- We will need Node.js for the
You can find the whole project here. We'll be referring to it a lot, so you should definitely check it out. In the end, our project structure will look like this:
| docker-compose.yml
|
+---backend
| app.py
| Dockerfile
| requirements.txt
|
+---frontend
| | .dockerignore
| | craco.config.js
| | Dockerfile
| | package.json
| | package-lock.json
| +---node_modules
| +---public
| +---src
|
+---memgraph
| |
| +---import-data
| | chatters.csv
| | moderators.csv
| | streamers.csv
| | teams.csv
| | vips.csv
| +---mg_log
| +---mg_lib
| +---mg_etcNow we will step by step build our application from bottom to top. First, we have to create the backend and memgraph directories. Within the memgraph directory, we create the import-data subdirectory and move all the CSV files we've scraped to it or we can use files we already have. In the beginning, our project structure looks like this:
| docker-compose.yml
|
+---backend
| app.py
| Dockerfile
| requirements.txt
|
+---memgraph
| |
| +---import-data
| | chatters.csv
| | moderators.csv
| | streamers.csv
| | teams.csv
| | vips.csvWe will create a docker-compose.yml file with many services which will depend on one another, so that we can simply run our application using docker-compose build and docker-compose up.
version: "3"
networks:
app-tier:
driver: bridge
services:
memgraph-mage:
image: memgraph/memgraph-mage
user: root
volumes:
- ./memgraph/import-data:/usr/lib/memgraph/import-data
- ./memgraph/mg_lib:/var/lib/memgraph
- ./memgraph/mg_log:/var/log/memgraph
- ./memgraph/mg_etc:/etc/memgraph
entrypoint:
[
"/usr/lib/memgraph/memgraph",
]
ports:
- "7687:7687"
networks:
- app-tier
twitch-app:
build: ./backend
volumes:
- ./backend:/app
ports:
- "5000:5000"
environment:
MG_HOST: memgraph-mage
MG_PORT: 7687
depends_on:
- memgraph-mage
networks:
- app-tierThe docker-compose.yml can be a lot simpler, but the app-tier and networks sections will come in handy later. We are building the memgraph-mage service which will have a running Memgraph instance along with MAGE query modules. Next, we need to have volumes to persist our data. In that way, we will have to load data only in the first run. In the subfolder import-data we have all the .csv files which we have to load into Memgraph. We called our backend service twitch-app and this service depends on memgraph-mage. In the backend, we first want to load data into Memgraph, and for this to work, there should be a running Memgraph instance. Our backend will be running on port 5000. Now let's take a look at the backend Dockerfile.
FROM python:3.8
# Install CMake
RUN apt-get update && \
apt-get --yes install cmake && \
rm -rf /var/lib/apt/lists/*
# Install packages
COPY requirements.txt ./
RUN pip3 install -r requirements.txt
COPY app.py /app/app.py
WORKDIR /app
ENV FLASK_ENV=development
ENV LC_ALL=C.UTF-8
ENV LANG=C.UTF-8
ENTRYPOINT ["python3", "app.py", "--populate"]In the first run, the flag --populate should definitely be included, so that the data would be loaded into Memgraph. Later on, if you were to restart the app, make sure to remove the --populate flag. Due to the volumes which we created, the data will stay loaded into Memgraph. We are using micro web framework Flask, that is, a package Werkzeug, which is a utility library for Python. It is a toolkit for Web Server Gateway Interface applications that can realize software objects for request, response, and utility functions. That will be just enough for our web application since the backend will communicate with Memgraph on request and send a response back. We are also copying requirements.txt to the container and installing all the dependencies. Let's see what's in there:
Flask==1.1.2
pymgclient==1.0.0
gqlalchemy==1.0.4As expected, Flask is there, so it will be installed in our container. Next, we have pymgclient, Memgraph database adapter for Python language on top of which gqlalchemy is built. We will connect to the database with gqlalchemy and it will assist us in writing and running queries on Memgraph.
We will be building API with the help of which frontend will be able to get all necessary data from Memgraph. First, we need to set up everything for the Flask server. We are adding arguments such as --host, --port and --debug flags. Also, we have created the previously mentioned --populate flag. We initialize our Flask app and save these arguments to use them when running the app.
app = Flask(
__name__,
)
memgraph = Memgraph()
def parse_args():
"""Parse command line arguments."""
parser = ArgumentParser(description=__doc__)
parser.add_argument("--host", default="0.0.0.0", help="Host address.")
parser.add_argument("--port", default=5000, type=int, help="App port.")
parser.add_argument(
"--debug",
default=True,
action="store_true",
help="Run web server in debug mode.",
)
parser.add_argument(
"--populate",
dest="populate",
action="store_true",
help="Run app with data loading."
)
parser.set_defaults(populate=False)
log.info(__doc__)
return parser.parse_args()
args = parse_args()
@log_time
def load_data():
"""Load data into the database."""
if not args.populate:
log.info("Data is loaded in Memgraph.")
return
log.info("Loading data into Memgraph.")
try:
memgraph.drop_database()
load_twitch_data(memgraph)
except Exception as e:
log.info("Data loading error.")
def main():
if os.environ.get("WERKZEUG_RUN_MAIN") == "true":
connect_to_memgraph(memgraph)
init_log()
load_data()
app.run(host=args.host, port=args.port, debug=args.debug)
if __name__ == "__main__":
main()When app.py is started, a connection to Memgraph is initiated. All methods which communicate with our instance of Memgraph are located in database.py. When the connection is established, the data can be loaded. We are going to use LOAD CSV Cypher clauses to import data into Memgraph. There are different ways of importing data, but this seemed like the most appropriate one. For example, let's show how streamers.csv can be loaded:
path_streams = Path("/usr/lib/memgraph/import-data/streamers.csv")
memgraph.execute(
f"""LOAD CSV FROM "{path_streams}"
WITH HEADER DELIMITER "," AS row
CREATE (u:User:Stream {{id: ToString(row.user_id), name: Tostring(row.user_name),
url: ToString(row.thumbnail_url), followers: ToInteger(row.followers),
createdAt: ToString(row.created_at), totalViewCount: ToInteger(row.view_count),
description: ToString(row.description)}})
MERGE (l:Language {{name: ToString(row.language)}})
CREATE (u)-[:SPEAKS]->(l)
MERGE (g:Game{{name: ToString(row.game_name)}})
CREATE (u)-[:PLAYS]->(g);"""
)Here we have created nodes with the labels :User:Stream and their properties. A streamer speaks certain language and plays a certain game, which is why we have created nodes :Language and :Game to represent those connections. Similarly, we have created the whole database, as drawn on the graph schema.
After our data is loaded into Memgraph, we run the Flask server. Currently, the app doesn't do much. The only thing you can actually check is whether your data is truly in Memgraph. The easiest way, especially if you are a visual type, is by using Memgraph Lab. Since you have a running Memgraph instance, you can just install Memgraph Lab, open it and click on the Connect button. Then, on the tab Overview you can see the total number of nodes and edges in your database.
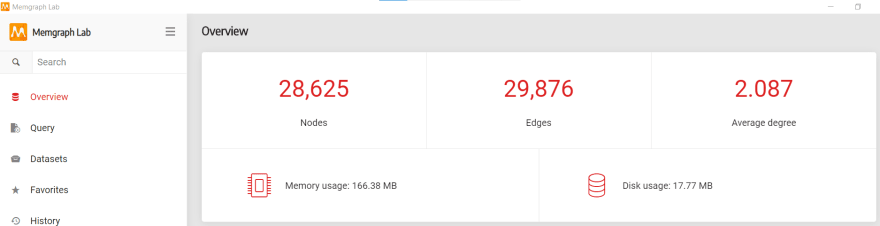
Nice - our data is really there! Now we can add some simple methods in our backend to try out the connection with Memgraph.
@app.route("/nodes", methods=["GET"])
@log_time
def get_nodes():
"""Get the number of nodes in database."""
try:
results = memgraph.execute_and_fetch(
"""MATCH ()
RETURN count(*) AS nodes;"""
)
for result in results:
num_of_nodes = result['nodes']
response = {"nodes": num_of_nodes}
return Response(response=dumps(response),
status=200,
mimetype="application/json")
except Exception as e:
log.info("Fetching number of nodes went wrong.")
log.info(e)
return ("", 500)App route says that we can get the response at localhost:5000/nodes. The method sends a query to Memgraph which will execute it and fetch the results. In our case, there is only one result, and that is the total number of nodes in the database. We send it as a JSON response. Try it out!
The idea behind these methods was to find out some interesting statistics about the network. All of them have a similar implementation and you can check them out here. Let's see how we got top games:
@app.route("/top-games/<num_of_games>", methods=["GET"])
@log_time
def get_top_games(num_of_games):
"""Get top num_of_games games by number of streamers who play them."""
try:
results = memgraph.execute_and_fetch(
f"""MATCH (u:User)-[:PLAYS]->(g:Game)
RETURN g.name as game_name, COUNT(u) as number_of_players
ORDER BY number_of_players DESC
LIMIT {num_of_games};"""
)
games_list = list()
players_list = list()
for result in results:
game_name = result['game_name']
num_of_players = result['number_of_players']
games_list.append(game_name)
players_list.append(num_of_players)
games = [
{"name": game_name}
for game_name in games_list
]
players = [
{"players": player_count}
for player_count in players_list
]
response = {"games": games, "players": players}
return Response(response=dumps(response),
status=200,
mimetype="application/json")
except Exception as e:
log.info("Fetching top games went wrong.")
log.info(e)
return ("", 500)The most popular game is the one that is being played by the most players. We would like to get a game name and the number of players that play it, in descending order. With Cypher queries and Memgraph, that’s pretty easy! After that, we just have to put our data in a dictionary and then the response will be in JSON format and easy to work with. Therefore, the response will be a list of games along with the number of players that play that game, in descending order. The length of the list depends on the argument num_of_games.
Besides general statistics, we would like to visualize some information about streamers. It would be fun to search our database for our favorite streamer. We want to get the game the streamer plays, the language the streamer speaks and the team the streamer is part of.
@app.route("/streamer/<streamer_name>", methods=["GET"])
@log_time
def get_streamer(streamer_name):
"""Get info about streamer whose name is streamer_name."""
is_streamer = True
try:
# Check whether streamer with the given name exists
counters = memgraph.execute_and_fetch(
f"""MATCH (u:User {{name:"{streamer_name}"}})
RETURN COUNT(u) AS name_counter;"""
)
for counter in counters:
if(counter['name_counter'] == 0):
is_streamer = False
# If the streamer exists, return its relationships
if(is_streamer):
results = memgraph.execute_and_fetch(
"""MATCH (u:User {name:'"""
+ str(streamer_name)
+ """'})-[]->(n)
RETURN u,n;"""
)
links_set = set()
nodes_set = set()
for result in results:
source_id = result['u'].properties['id']
source_name = result['u'].properties['name']
source_label = 'Stream'
target_id = result['n'].properties['name']
target_name = result['n'].properties['name']
target_label = list(result['n'].labels)[0]
nodes_set.add((source_id, source_label, source_name))
nodes_set.add((target_id, target_label, target_name))
if (source_id, target_id) not in links_set and (
target_id,
source_id,
) not in links_set:
links_set.add((source_id, target_id))
nodes = [
{"id": node_id, "label": node_label, "name": node_name}
for node_id, node_label, node_name in nodes_set
]
links = [{"source": n_id, "target": m_id}
for (n_id, m_id) in links_set]
# If the streamer doesn't exist, return empty response
else:
nodes = []
links = []
response = {"nodes": nodes, "links": links}
return Response(response=dumps(response),
status=200,
mimetype="application/json")
except Exception as e:
log.info("Fetching streamer by name went wrong.")
log.info(e)
return ("", 500)Through the response we’ll get the streamer node along with the links the streamer is connected to. This data will be useful on the frontend side, where we will be able to draw graphs with this data. Now let’s see how Memgraph’s query modules work, particularly PageRank and Betweenness Centrality algorithms. With these two we will measure the popularity and influence of streamers. Using these procedures you can simply determine which node is the most relevant in your graph. Here is get_page_rank() method:
@app.route("/page-rank", methods=["GET"])
@log_time
def get_page_rank():
"""Call the Page rank procedure and return top 50 in descending order."""
try:
results = memgraph.execute_and_fetch(
"""CALL pagerank.get()
YIELD node, rank
WITH node, rank
WHERE node:Stream OR node:User
RETURN node, rank
ORDER BY rank DESC
LIMIT 50; """
)
page_rank_dict = dict()
page_rank_list = list()
for result in results:
user_name = result["node"].properties["name"]
rank = float(result["rank"])
page_rank_dict = {"name": user_name, "rank": rank}
dict_copy = page_rank_dict.copy()
page_rank_list.append(dict_copy)
response = {"page_rank": page_rank_list}
return Response(response=dumps(response),
status=200,
mimetype="application/json")
except Exception as e:
log.info("Fetching users' ranks using pagerank went wrong.")
log.info(e)
return ("", 500)We filtered the results by the :Stream and :User label, since we are interested in measuring the influence of them, rather than different parts of our graph. There are many different methods which you can implement, but here is the list of the ones you can find in the repository:
| Method | Description |
|---|---|
get_top_games(num_of_games) |
Get top num_of_games games by number of streamers who play them. |
get_top_teams(num_of_teams) |
Get top num_of_teams teams by number of streamers who are part of them. |
get_top_vips(num_of_vips) |
Get top num_of_vips vips by number of streamers who gave them the vip badge. |
get_top_moderators(num_of_moderators) |
Get top num_of_moderators moderators by number of streamers who gave them the moderator badge. |
get_top_streamers_by_views(num_of_streamers) |
Get top num_of_streamers streamers by total number of views. |
get_top_streamers_by_followers(num_of_streamers) |
Get top num_of_streamers streamers by total number of followers. |
get_streamer(streamer_name) |
Get info about streamer whose name is streamer_name. |
get_streamers(language, game) |
Get all streamers who stream certain game in certain language. |
get_nodes() |
Get the number of nodes in database. |
get_edges() |
Get the number of edges in database. |
get_page_rank() |
Call the PageRank procedure and return top 50 in descending order. |
get_bc() |
Call the Betweenness centrality procedure and return top 50 in descending order. |
That's it for now! In the next part of this blog post, find out how to build React application on top of the backend, and in the third part, learn how to ingest new data with Kafka and see how we can see that in our visualization. Feel free to join our Discord Community server, where you can ask any question related to this blog post or anything else you want to know about Memgraph.
19